本文最后更新于:2024年5月11日 下午
获取原始语音文件 后,需要筛选出某个角色的音频用于下一步训练,本文记录实现过程。
困难
数据庞大 :原神中语音场景很多,角色也很多,要从几万条语音中找到目标角色的那几百条语音类似于海里捞一堆针了。
解决思路
有问题就想办法解决,这里记录我的实践路线:
选择目标角色(神里绫华 、云堇 )
网上抓出目标角色的一些经典台词(几十条就行)
我们能够轻易获取的角色语音内容信息
识别所有语音内容
重采样语音 到 16k 采样率识别语音
将识别结果与经典台词进行比对,找到角色的部分语音文件作为种子文件
提取语音的声纹特征
对特征进行降维
对降维特征进行聚类 ,根据聚类结果分类语音
在降维空间中查看种子文件所在位置,提取同一簇语音数据
进行人工筛选,数据整理
准备工作
准备好音频文件 是第一位的
选出目标角色的台词
以云堇为例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 有道是闻名不如见面,今天终于有缘与你相会,实属荣幸。我姓云,单名一个堇字,不才正是云翰社当家主事的人。我们戏社最近挂靠在和裕茶馆,日后还请多多赏光,常来听戏。
语音识别
音频重采样
原始原神语音采样率 48k,有点高了,需要降到 16k
方法参考 重采样语音
语音识别
可以使用百度语音识别 或者 科大讯飞 语音识别
对我来说,二者比较下来讯飞的识别更准,但是免费额度比百度少,新用户5W次,百度有15W 次。
这里分享一下我的 百度识别结果 ,仅供参考(讯飞的还在跑)。
筛选种子文件
我们现在有角色的语音文字GT,和所有角色的语音识别结果,现在需要将二者对应上,以找到该角色的部分语音。
这里还有个困难是我们的识别结果不一定准,由于是语音识别写成的文字,错别字、多字、少字都很正常,需要在识别结果有误差的情况下对齐文字。
这里我的解决思路是使用去掉标点的文字拼音字符串 之间的最长公共子序列 的长度来评定是否匹配。
核心功能在我的 python 库 mtutils 中,安装:
中文句子转成纯拼字字符串
1 2 3 4 5 import mtutils as mt'中文,句子。?' '_' , '' )
最长公共子序列
1 2 import mtutils as mt
评分标准设置为公共串长度的平方除以两个字符串的长度
1 2 length_match = len (mt.find_lcseque(key_str, target_sen))2 / len (key_str) / len (target_sen)
筛选时仅记录得分最高的音频文件。
示例代码
直接贴上我的筛选代码,仅供参考
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import mtutils as mtdef get_sentences (role_name ):list ()'base_data' , role_name + '.txt' )assert mt.OS_exists(words_file_path)lambda x: x if len (x) > 0 else None )for line in mt.tqdm(file_lines):'_' , '' )return role_sentencesif __name__ == '__main__' :'神里绫华' , '云堇' ]for role_name in role_name_list:'audio-rec-results.json' )dict ()for target_sen_group in mt.tqdm(role_sentences):1 0 None None for key, value in mt.tqdm(res_dict.items()):0 ]if len (value) < 1 :continue '_' , '' )len (mt.find_lcseque(key_str, target_sen))2 / len (key_str) / len (target_sen)if match_score > best_score:'target_sen' : target_sen,'base_sen' : base_sen,'target_len' : len (target_sen),'match_len' : best_length,'best_score' : best_score,'match_sen' : best_value,'match_file_name' : best_key'_res.json' )pass
这里分享我 云堇 的匹配结果(低分的被我删掉了)。
提取音频文件声纹特征
参考 声纹识别 ECAPA-TDNN
声纹识别可以直接输入 48k 采样率的音频数据,音频文件 57546 个,声纹的特征 192 维,因此得到了 $57546 \times 192$ 的特征矩阵。
三百多M,这里就不上传了。
特征降维
事实上 ECAPA-TDNN 的代码仓库作者使用的声纹匹配是直接用原始 192 维特征计算余弦相似度计算的,两个音频文件声纹特征的余弦相似度高,则是同一个人的,这在方向上是合理的
我尝试了这个方法发现召回率和准确率都不够高,这里我推荐用暴力、直观一点的方法,特征降维。
参考 降维方法 PCA、t-sne、Umap 的 python 实现
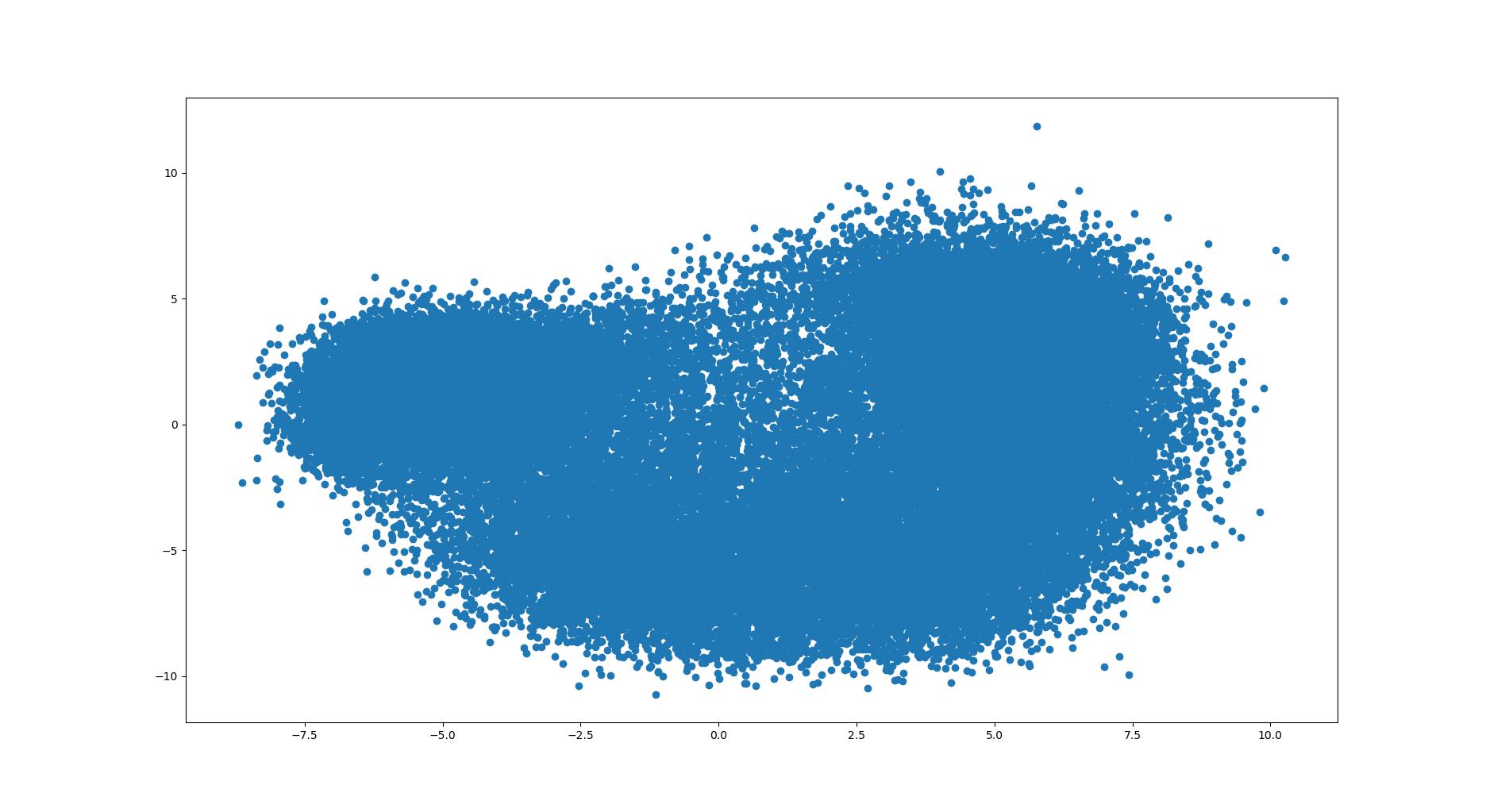
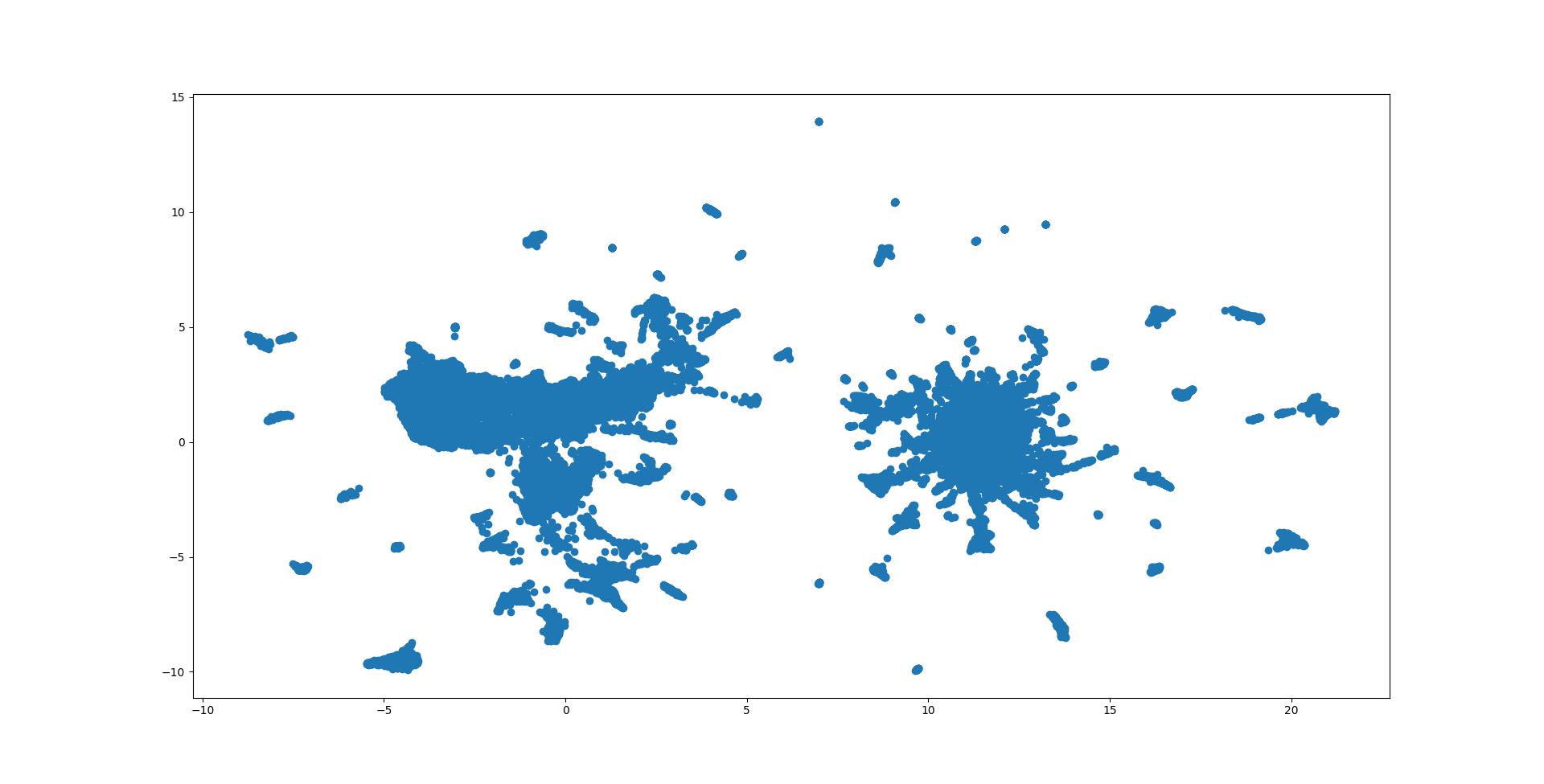
我将上述原始特征矩阵在这三种降维方法下做了尝试,二维可视化图像如下:
对比起来觉得 T-sne 分得更开,如果一坨就是一个角色就完美了(事实上差不多确实如此)
因此使用 T-sne 方法降维到 2D 数据,现在特征矩阵维度 $57546 \times 2$
特征聚类
可以手动选择tsne 特征上的一个区域,将其中的特征对应的数据筛选出来,看看是不是同一个人的,这样比较麻烦也不够优雅,我尝试了特征聚类
参考:常用聚类算法
DBSCAN 是最合适我的使用场景的,运算占用内存小,不需要设置类别数量,根据密度聚类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from matplotlib import pyplot as pltimport numpy as npimport mtutils as mtfrom sklearn.cluster import MiniBatchKMeansfrom sklearn.cluster import DBSCAN18.5 , 9.4 )1 , 1 , figsize=figsize)'tsne_fea_save.pickle' )1.5 , min_samples=6 )for sub_label in clusters[:]:0 ], X[cluster.labels_==sub_label, 1 ], color=(np.random.random(), np.random.random(), np.random.random()))pass
将除了噪声数据外的特征对应的文件按照聚类类别划分到不同文件夹
可视化种子文件位置
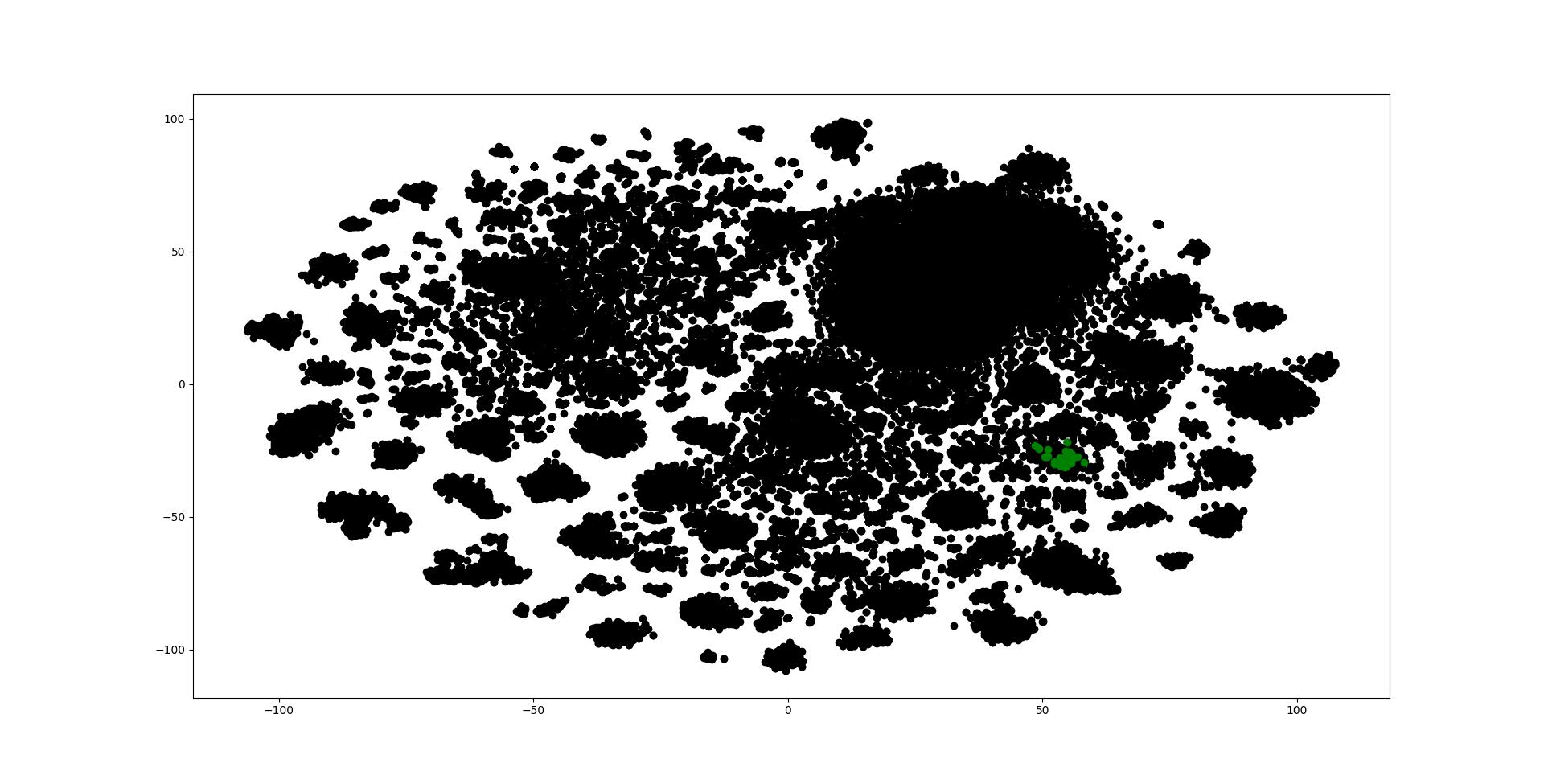
将种子文件的特征在降维特征上可视化出来:
那么我们有理由猜想,下图表示的这一坨,就是云堇的语音
人工确认
根据特征位置找到这一坨特征对应的文件,听一遍确认真的是云堇 ~
将这些数据对应的语音识别结果拿到整理出来,再修改修改,就得到了云堇的语音文件和内容标注了 ~
不容易啊 …
挑了一部分特征做了标注,基本上还是准的
参考资料
文章链接:https://www.zywvvd.com/notes/study/audio/speech-classification/classify-audio-ys/