本文最后更新于:2024年5月7日 下午
语音训练需要优质的数据,我们尝试使用原神中的语音进行训练,首先需要提取并解析其中的语音信息。
感谢 B站大佬的分享
处理流程
- 找到数据
- 解压数据
- 解密数据
数据处理
找到数据
在 PC 版原神中,音频文件放在游戏文件夹中,我的路径为:
D:\Program Files\Genshin Impact\Genshin Impact Game\YuanShen_Data\StreamingAssets\AudioAssets\Chinese

3.7 版原神共 114 个语音文件 9.38 g,将其中的数据拷贝出来。
解压数据
拿到的数据均为 使用 Extractor2.5 解压数据
下载工具后解压,打开 exe 文件即可运行,选择所有刚刚生成的语音文件作为输入文件,选择输出文件夹:
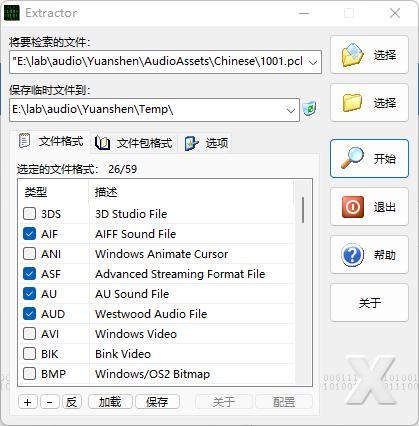
开始解压:
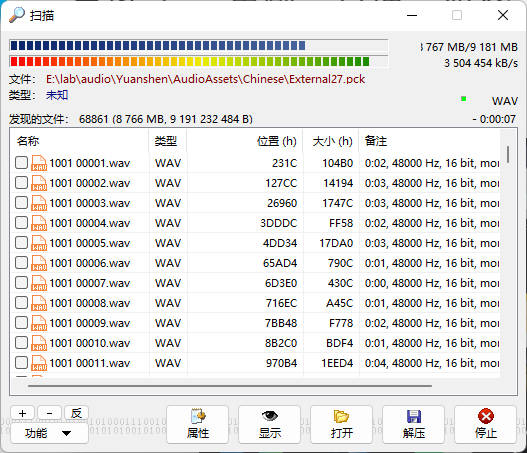
之后反选所有数据, 选择解压即可。
共拿到语音 72021 条。
解密数据
解压直接得到的数据无法听到语音,需要进行解密:
需要用到项目: https://github.com/vgmstream/vgmstream
进入项目的 release 下载需要的编译文件(以我当前 Win 为例):

下载后解压,得到可执行文件,将其加入系统路径
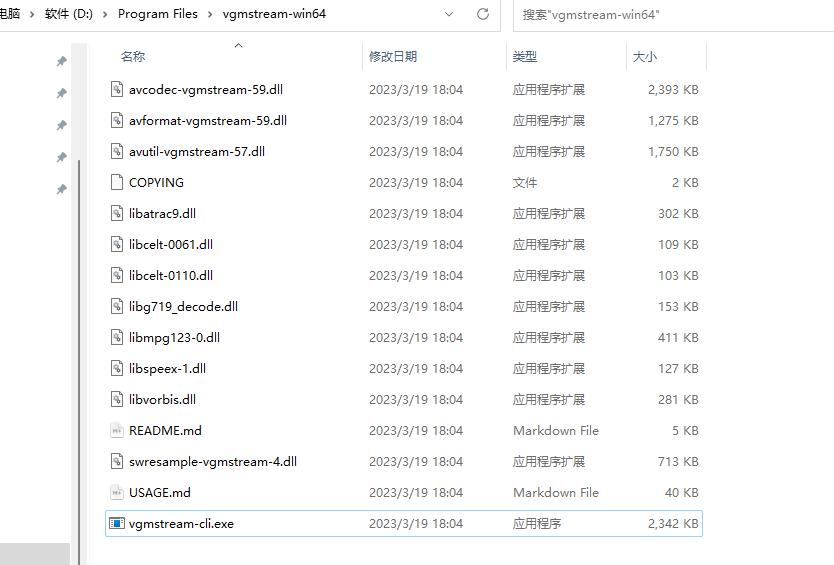
这样就可以使用 vgmstream-cli.exe 直接运行解密了
编写 Python 脚本:
1 | |
我将数据放到 Temp 文件夹,脚本在 Temp 外一层,可以直接运行。
脚本
os.system命令中空格字符需要用双引号包住。
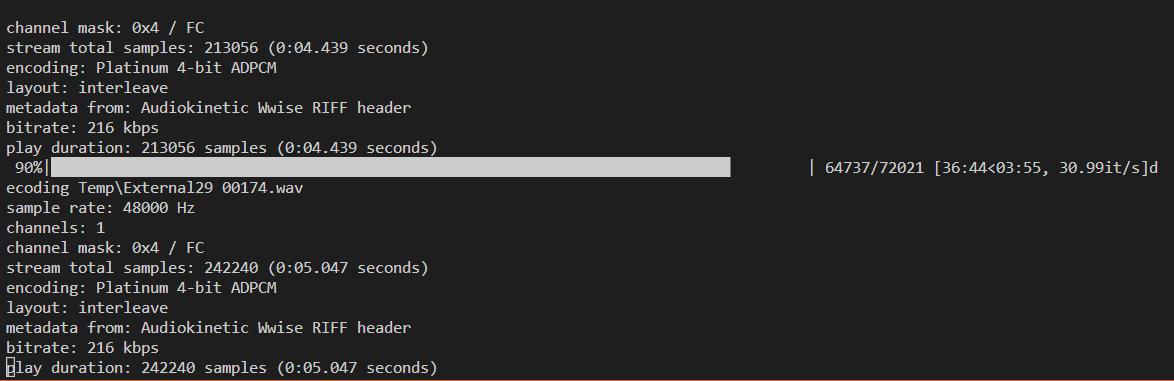
在我的机器上运行四十分钟解密所有语音文件,得到 72021 条。
筛选数据
粗略筛选数据,删除 200k 以下的音频文件,最终得到原神原始音频 57546 条。
参考资料
- https://www.bilibili.com/video/BV1sM411i7to/?vd_source=8ee219651c85ad2dcb7767effc5919a7
- https://www.windowszj.net/pcsoft/yingyong/34535.html
- https://github.com/vgmstream/vgmstream
- https://blog.csdn.net/Scott0902/article/details/129446831
文章链接:
https://www.zywvvd.com/notes/study/audio/yuanshen-audio/yuanshen-audio/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付