本文最后更新于:2024年5月7日 下午
语音识别已经是很成熟的技术了,本文记录调用百度 API 实现语音识别的过程。

简介
百度语音识别的功能:
- 技术领先识别准确
采用领先国际的流式端到端语音语言一体化建模方法,融合百度自然语言处理技术,近场中文普通话识别准确率达98%
- 多语种和多方言识别
支持普通话和略带口音的中文识别;支持粤语、四川话方言识别;支持英文识别
- 深度语义解析
支持50多个领域的语义理解,如:天气,交通,娱乐等。还可接入智能对话定制与服务平台UNIT自定义语义理解和对话服务,让您更准确地理解用户意图
- 中文标点智能断句
使用大规模数据集训练语言模型,根据语音的内容理解和停顿智能匹配合适的标点符号(包括,。!?),使识别结果的表现方式贴合表述,更加可懂
- 数字格式智能转换
根据语音内容理解可以将数字序列、小数、时间、分数、基础运算符正确转换为数字格式,使得识别的数字结果更符合使用习惯,直观自然
- 支持自助训练专属模型
支持在语音自训练平台上自助训练模型,上传词汇文本即可零代码完成训练,精准提升业务领域词汇识别率5-25%,并可专属使用
准备流程
参考文档:https://ai.baidu.com/ai-doc/SPEECH/qknh9i8ed
-
申请百度智能云账号
-
登录百度智能云,进入控制台
-
导航 -> 产品服务 -> 语音技术

- 创建应用

勾选需要的应用,填入信息即可。
- 领取免费资源
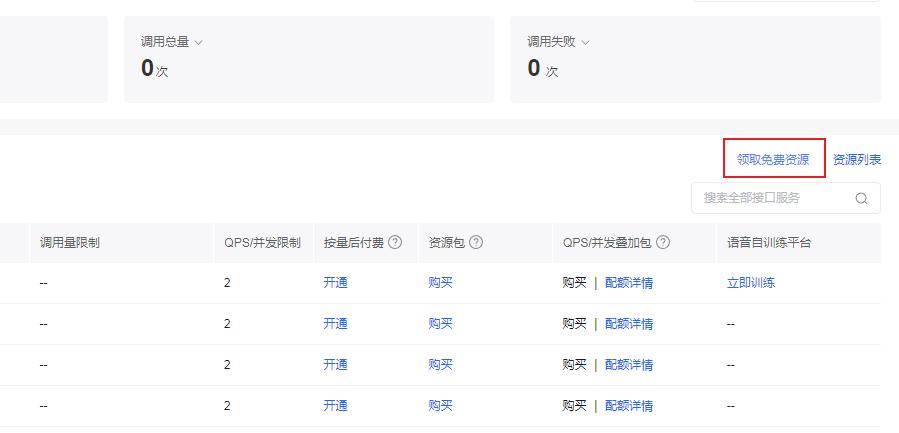
- 选择自己需要的服务 -> 0元领取
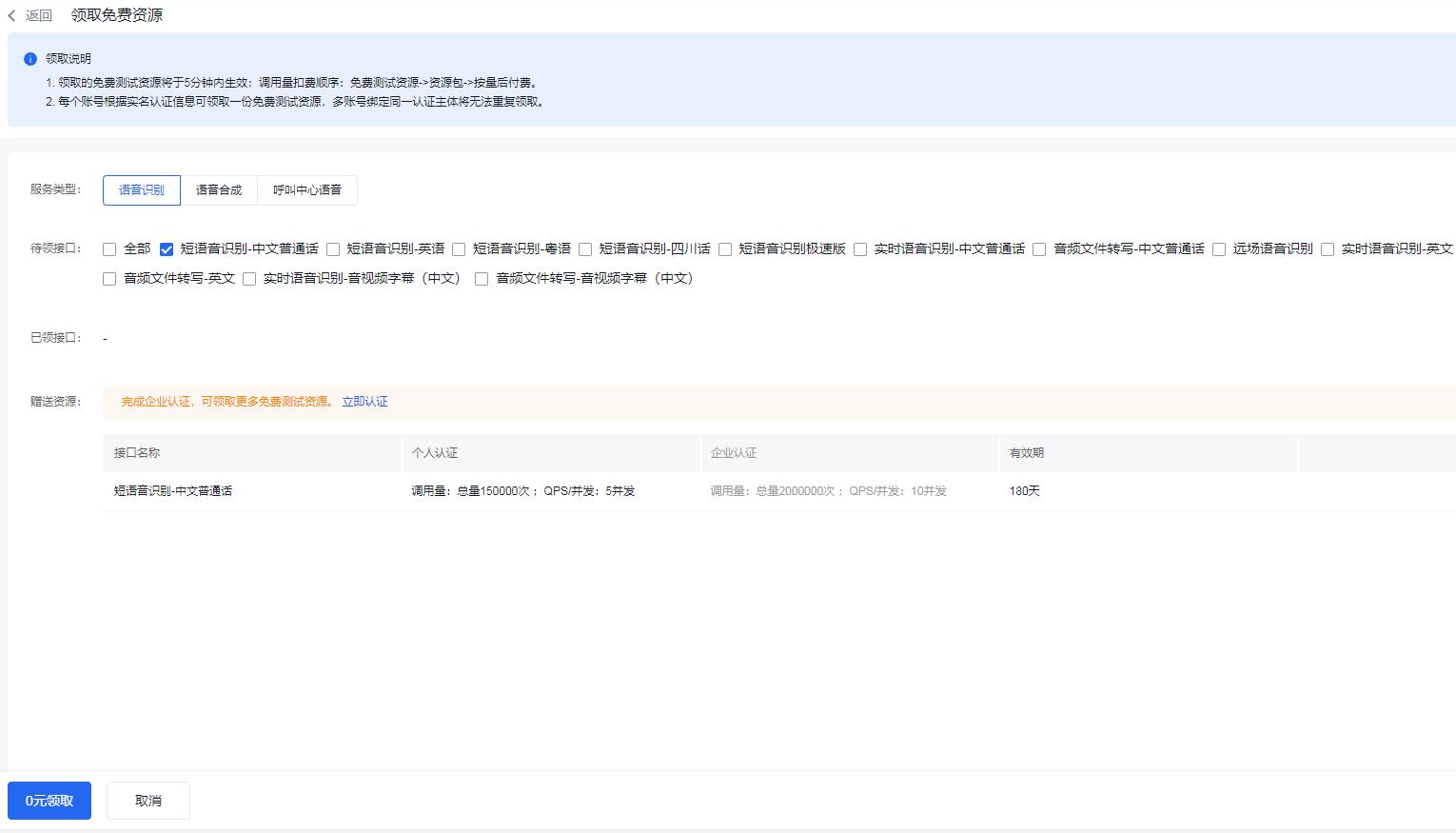
- 5分钟内,等待其生效
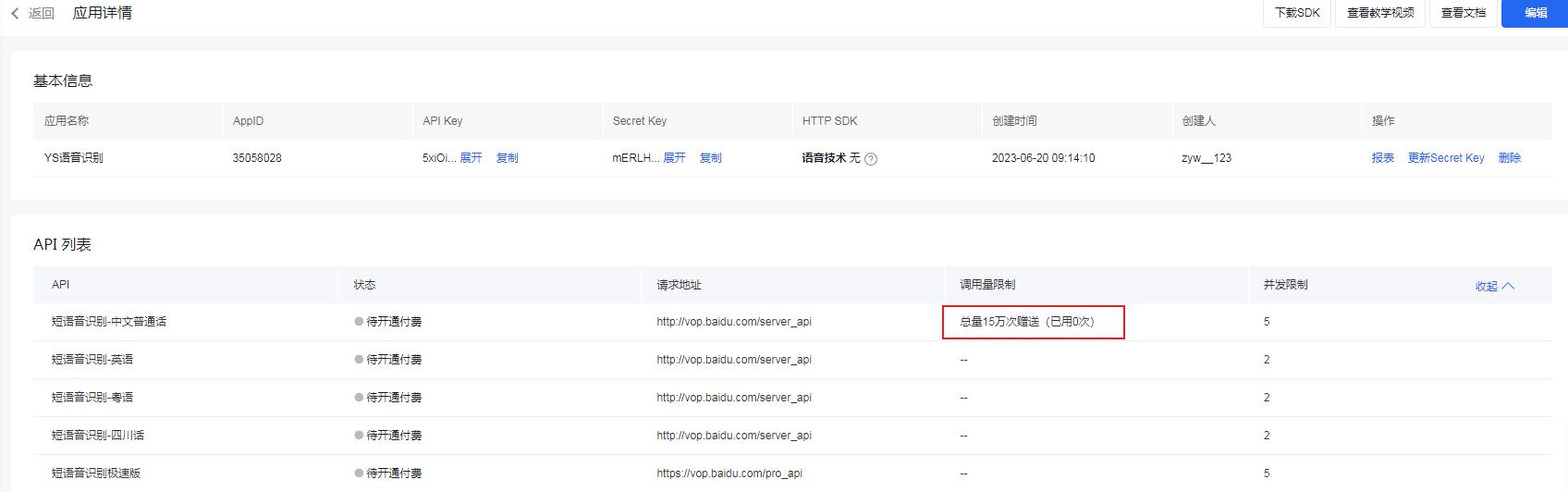
生效后可以看到 15 W 次的免费测试额度,对简单测试来说已经足够用了。
获取 Access Token
在您创建完毕应用后,平台将会分配给您此应用的相关凭证,主要为AppID、API Key、Secret Key。以上三个信息是您应用实际开发的主要凭证,请您妥善保管。
您需要使用创建应用所分配到的AppID、API Key及Secret Key,进行Access Token(用户身份验证和授权的凭证)的生成。
官方文档: Access Token获取 。
核心方法需要向授权服务地址https://aip.baidubce.com/oauth/2.0/token发送请求(推荐使用POST),并在URL中带上以下参数:
- grant_type: 必须参数,固定为
client_credentials;
- client_id: 必须参数,应用的
API Key;
- client_secret: 必须参数,应用的
Secret Key;
官方推荐三种方法,我们这里采用 Python 脚本实现的方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| import requests
import json
def main():
url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=xxxxxx&client_secret=xxxxx"
payload = ""
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
if __name__ == '__main__':
main()
|
从返回的 json 包中取出 access_token 的值即可,返回值中的 expires_in 为该 token 的有效期,单位是 s,其他参数忽略,暂时不用;
我返回的 “expires_in”:2592000,表示 30 天有效期,过期后需要重新申请 access_token。
语音识别
分为 API 版和 SDK 版,使用 HTTP 接入的录音时长不能超过 60s,对于我来说足够用了,因此本文以 HTTP API 接入方式为例。
音频重采样
语音识别需要将音频采样频率固定在 16k,如果当前音频不是 16k 采样率,需要重采样。
可以参考 修改 wav 音频采样率
测试音频
原神中的一段 音频 为例。
调用百度的音频识别 API Python Demo 示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
import sys
import time
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
timer = time.perf_counter
AUDIO_FILE = 'audio_resampled.wav'
FORMAT = AUDIO_FILE[-3:];
CUID = '123456PYTHON';
RATE = 16000;
DEV_PID = 1537;
ASR_URL = 'http://vop.baidu.com/server_api'
SCOPE = 'audio_voice_assistant_get'
if __name__ == '__main__':
my_token = "your access token"
"""
httpHandler = urllib2.HTTPHandler(debuglevel=1)
opener = urllib2.build_opener(httpHandler)
urllib2.install_opener(opener)
"""
speech_data = []
with open(AUDIO_FILE, 'rb') as speech_file:
speech_data = speech_file.read()
length = len(speech_data)
if length == 0:
raise RuntimeError('file %s length read 0 bytes' % AUDIO_FILE)
params = {'cuid': CUID, 'token': my_token, 'dev_pid': DEV_PID}
params_query = urlencode(params);
headers = {
'Content-Type': 'audio/' + FORMAT + '; rate=' + str(RATE),
'Content-Length': length
}
url = ASR_URL + "?" + params_query
print("url is", url);
print("header is", headers)
req = Request(ASR_URL + "?" + params_query, speech_data, headers)
try:
begin = timer()
f = urlopen(req)
result_str = f.read()
print("Request time cost %f" % (timer() - begin))
except URLError as err:
print('asr http response http code : ' + str(err.code))
result_str = err.read()
if (IS_PY3):
result_str = str(result_str, 'utf-8')
print(result_str)
with open("result.txt", "w") as of:
of.write(result_str)
|
在代码的 my_token 处填入自己的 access-token,就可以识别我的示例音频了,我的输出:
1
2
| {"corpus_no":"7246604200451327860","err_msg":"success.","err_no":0,"result":["这就是四方之风的力量中特婉林只能借用三方的原因了。"],"sn":"185528422541687231520"}
|
还是可以的。
参考资料
文章链接:
https://www.zywvvd.com/notes/study/audio/baidu-speech-recognition/baidu-speech-recognition/

