本文最后更新于:2024年5月7日 下午
声纹识别是指利用声音特征对说话人的身份进行识别的生物识别技术,已有几十年的发展历史,但直到深度学习兴起之后才开始广泛应用。 本文记录当前主流声纹模型 ECAPA-TDNN。
简介
ECAPA-TDNN由比利时哥特大学Desplanques等人于2020年提出,通过引入SE (squeeze-excitation)模块以及通道注意机制,该方案在国际声纹识别比赛(VoxSRC2020)中取得了第一名的成绩。百度旗下PaddleSpeech发布的开源声纹识别系统中就利用了ECAPA-TDNN提取声纹特征,识别等错误率(EER)低至0.95%。
Baseline
两种基于DNN的说话人识别系统将作为衡量ECAPA-TDNN模型性能的有力baseline:一种是x-vector系统,另一种是基于ResNet的系统,这两种系统目前都在VoxSRC等说话人验证任务上达到了最先进水平。
x-vector
x-vector包含多层帧级别的TDNN层,一个统计池化层和两层句子级别的全连接层,以及一层softmax,损失函数为交叉熵。得益于网络中的统计池化层,x-vector可以接受任意长度的输入,并将帧级别的特征融合成整句的特征。此外,在训练中引入了包含噪声和混响在内的数据增强策略,使得模型对于噪声和混响等干扰更加鲁棒。
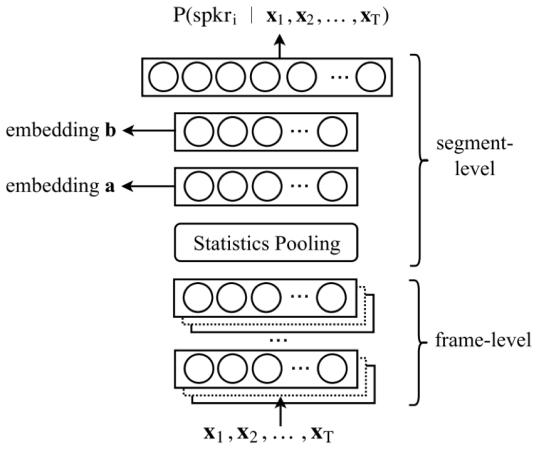
扩展的 TDNN x-vector 体系结构,它改进了原始 x-vector系统。初始帧层由一维空洞卷积层和全连接层交叉而成。每个过滤器都可以访问前一层或输入层的所有特征。空洞卷积层的任务是逐渐建立时间上下文。在所有框架层中引入残差连接。框架层之后是一个仔细的统计数据池化层,用于计算最终帧级特征的平均值和标准差。在统计池化层使用注意力机制,如下图所示,给不同的帧不同的权重,并且同时生成加权平均数、加权标准差。在这种方式下,它可以有效地捕获到更长期的说话人特征变化。在统计池化层之后,引入两个全连接层,第一层作为瓶颈层(1x1的卷积层),生成低维说话人特征嵌入。

基于ResNet的r-vector
第二个基线系统是文献中提出的r-vector(从ResNet中提取的嵌入)。它由基于ResNet架构的ResNet18和ResNet34实现。ResNet采用残差块来简化比以往深很多的网络的训练,对每几个堆叠的层做依次残差学习,在特征相加时维度相等的情况下,即恒等映射时,一个残差块被定义为:
$$
y=F(x,{W_i})+x
$$
其中x和y是所考虑的层的输入和输出向量。函数 $F(x,{W_i})$ 表示要学习的残差映射。如果该条件不满足(比如,通道数不同)的话,我们还可以对输入执行一个线性投影 $W_s$ 来匹配二者的维度,如下:
$$
y=F(x,{W_i})+W_sx
$$
该网络的卷积帧层使用二维特征作为输入,并使用二维CNN对其进行处理,受x-vector向量拓扑的启发,在池化层中收集平均值和标准差统计信息,使用的ResNet的详细拓扑如下图所示。总之,不论网络的深浅,使用残差学习总是有好处的:浅时能够加快收敛,深时可以解决退化问题,使求解器找到较好的解。

论文核心技巧
针对目前基于x-vector的声纹识别系统中的一些优缺点,论文从以下3个方面进行了改进:
依赖于通道和上下文的统计池化
在最近的x-vector架构中,软自注意力(soft-attention)用于计算时序池化层中的加权统计信息,可以在不同的帧集上提取特定的说话人属性。基于此,论文将这种时间注意力机制扩展到通道维度:
$$ e_{t, c}=\boldsymbol{v}_{c}^{T} f\left(\boldsymbol{W} \boldsymbol{h}_{t}+\boldsymbol{b}\right)+k_{c} $$式中,$ℎ_t$ 是时间步长 $t$ 处最后一个帧层的激活,参数W和b将注意力信息投影到一个较小的R维表示中,这一表征由所有C个通道共享以减小过拟合的风险。通过非线性函数f(.)之后,该信息通过带权重的线性层$v_c$和偏置$k_c$转换为通道相关的自注意力分数$e_{t,c}$,再通过时域t上的softmax函数进行归一化得到注意力权重$α_{t,c}$:
$$
\alpha_{t, c}=\frac{\exp \left(e_{t, c}\right)}{\sum_{\tau}^{T} \exp \left(e_{\tau, c}\right)}
$$
一维Squeeze-Excitation(挤压激励模块)Res2Blocks
在x-vector系统中帧层的时间上下文限制为15帧,无法利用更大范围的时序上下文以提高性能。考虑到语音数据的长时关联性,论文引入了计算机视觉领域中的一维挤压激励(SE)模块,该模块能有效建模全局通道的相关性。
SE的第一个组件是挤压操作,它为每个通道生成描述符,挤压操作仅包括计算跨时域的帧级特征的平均向量z:
$$ \boldsymbol{z}=\frac{1}{T} \sum_{t}^{T} \boldsymbol{h}_{t} $$然后在激励操作中使用z中的描述符来计算每个通道的权重。论文将激励操作定义为:
$$ \boldsymbol{s}=\sigma\left(\boldsymbol{W}_{2} f\left(\boldsymbol{W}_{1} \boldsymbol{z}+\boldsymbol{b}_{1}\right)+\boldsymbol{b}_{2}\right) $$此操作充当瓶颈层,得到的向量s是介于0和1之间的权重sc,这些权重在每个通道计算后与原始输入相乘后得到估计的输出 $\tilde{\boldsymbol{h}}_{c}$: $$ \tilde{\boldsymbol{h}}_{c}=s_{c} \boldsymbol{h}_{c} $$
为了将SE模块与残差连接的优点结合起来,论文提出了如下图所示的 SE-Res2Block架构:
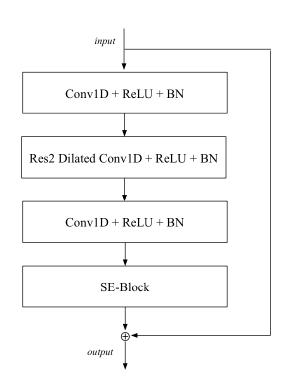
SE-Res2Block包含具有前一层和后一个层上下文为1帧的空洞卷积,第一个层可用于降低特征维度,而第二个密集层将特征数量恢复到原始维度,然后用SE模块来缩放每个通道,整个单元使用一个跳跃连接。
ResBlock是一种流行的计算机视觉体系结构,关于它有许多改进的工作,使用ResBlock让系统可以轻松地整合改进的模块,性能更优。例如,最近的Res2Net模块增强了中央卷积层,因此它可以通过在内部构造层次化的类残差连接来处理多尺度特征。此模块的集成提高了性能,同时显著减少了模型参数的数量。
多层特征聚合及求和
原始的 x 向量系统仅使用最后一帧层的特征映射来计算池化统计信息。鉴于TDNN的分层性质,这些更深层次的特征是最复杂的特征,应该与说话者身份密切相关。然而,根据相关文献中的证据,论文认为更浅的特征映射也有助于更稳健的说话人嵌入。对于每一帧,论文提出将所有SE-Res2Blocks的输出特征串联起来。在这个多层特征聚合(MFA)之后,一个密集层(dense layer)处理连接的信息以生成用于注意力统计池的特征。
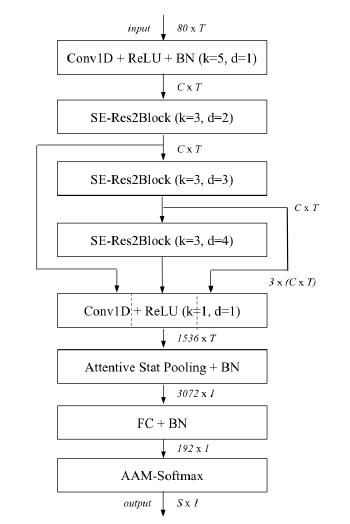
另一种利用多层信息的补充方法是使用所有先前SE-Res2Blocks和初始卷积层的输出作为每个帧层块的输入。论文中,通过将每个SE-Res2Block中的残差连接定义为所有先前块的输出的总和来实现这一点。这可以从算法框图中“Conv1D+ReLU(k=1,d=1)”上面的几个箭头看出。论文选择对特征图求和,而不是串联来限制模型参数计数。最终,ECAPA-TDNN的整体架构如图所示。
原始论文
开源项目
我这里推荐一个我用过的半开源项目,说他半开源是因为源码开源了,预训练模型下载需要付费,有点不舒服,但也能理解。
项目地址:https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch
使用方法
-
将仓库克隆到本地
-
下载预训练模型(付费,有条件也可以自己训练)
-
将模型放到 models 文件夹
-

-
替换配置文件
configs/ecapa_tdnn.yml为你下载的模型配置文件 -
修改 inter_ 开头的文件运行就可以得到结果了。
示例代码
1 | |
这是我使用的代码,将文件夹中所有 wav 文件循环,通过网络提取声纹特征,做成字典保存起来备用。
声纹特征 192 维。
参考资料
- https://arxiv.org/pdf/2005.07143.pdf
- https://zhuanlan.zhihu.com/p/543196489
- https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch
文章链接:
https://www.zywvvd.com/notes/study/audio/voiceprint-recognition/voiceprint-recognition/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付