本文最后更新于:2024年5月11日 下午
本文介绍三种常用降维方法 PCA、t-sne、Umap 的 Python 实现。
数据集
提取游戏音频 5.7W 段,提取声音指纹特征,放在 fea.json 文件中用于测试。
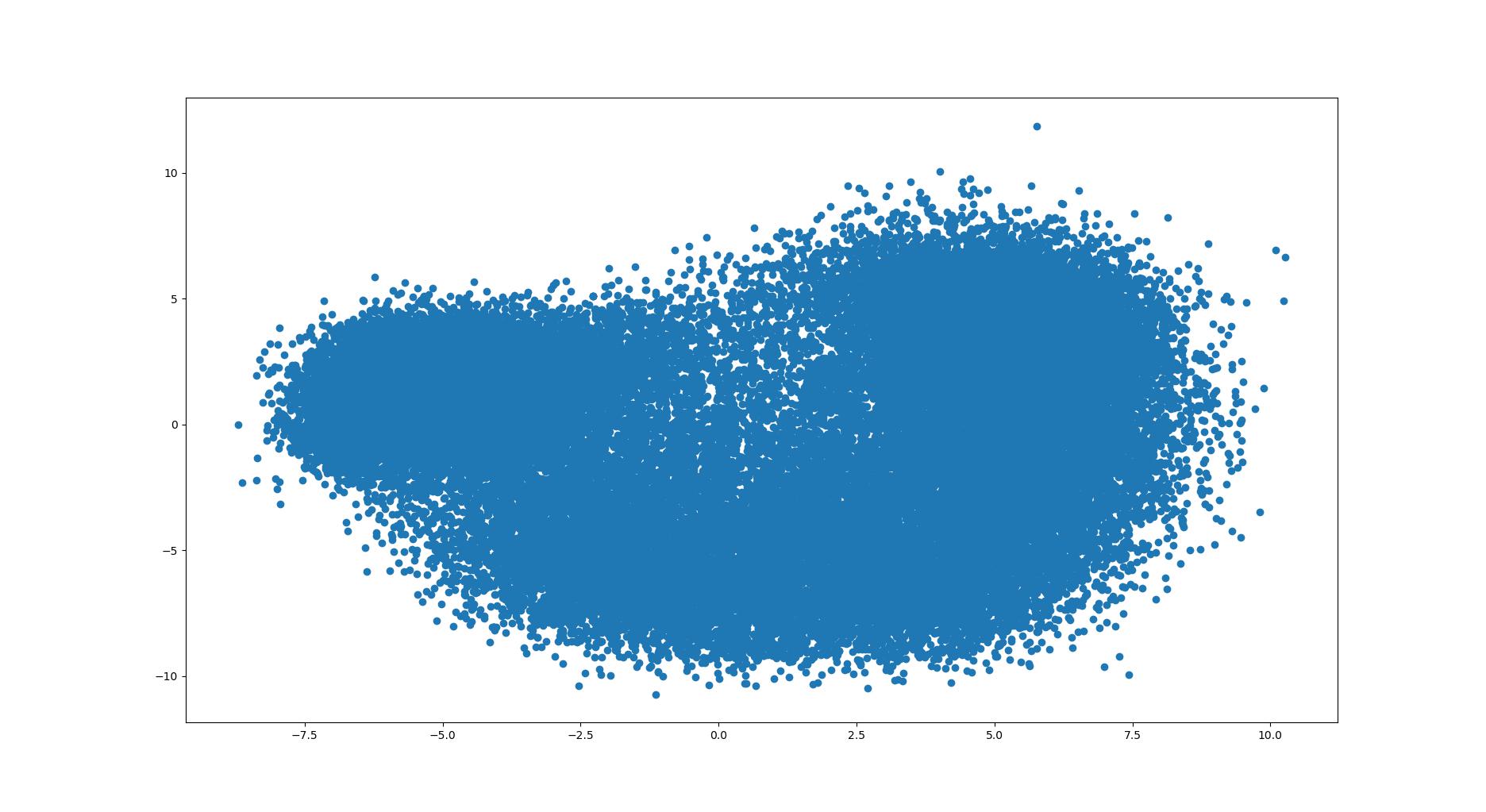
PCA
主成分分析方法(Principal Component Analysis,PCA)是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import mtutils as mtfrom sklearn.manifold import TSNEfrom sklearn.preprocessing import StandardScalerfrom sklearn.decomposition import PCAimport matplotlib.pyplot as pltimport numpy as np'fea.json' )list (fea_info.values()))2 ).fit_transform(data) 0 ], X_pca[:, 1 ])2 , perplexity=20 , random_state=42 )0 ], new_data[:, 1 ])
测试效果
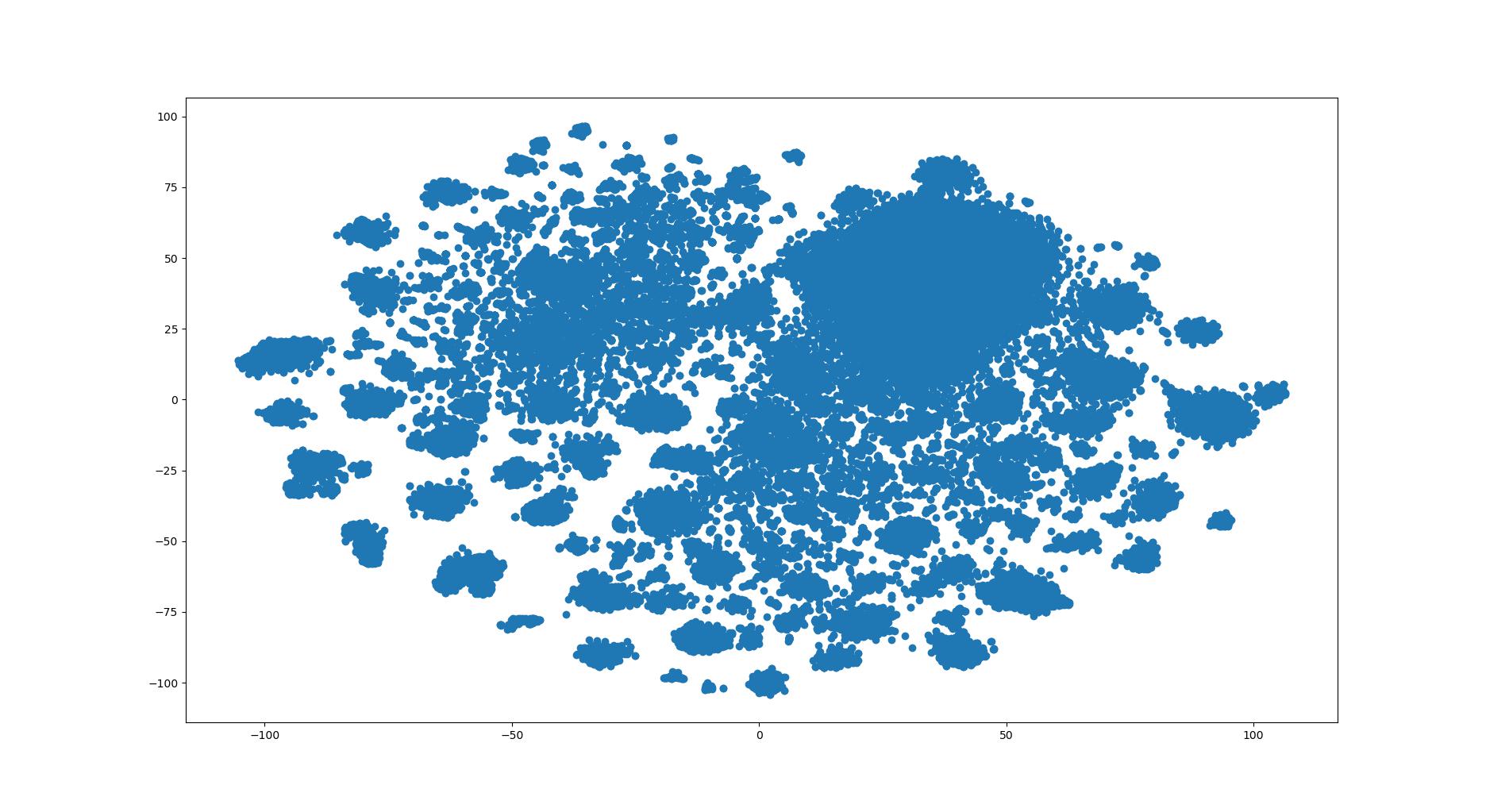
t-SNE
t-分布领域嵌入算法(t-Distributed Stochastic Neighbor Embedding,t-SNE)是一种降维技术,用于在二维或三维的低维空间中表示高维数据集,从而使其可视化。与其他降维算法(如PCA)相比,t-SNE创建了一个缩小的特征空间,相似的样本由附近的点建模,不相似的样本由高概率的远点建模。
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import mtutils as mtfrom sklearn.manifold import TSNEfrom sklearn.preprocessing import StandardScalerimport matplotlib.pyplot as pltimport numpy as np'fea.json' )list (fea_info.values())2 , perplexity=20 , random_state=42 )0 ], new_data[:, 1 ])pass
测试效果
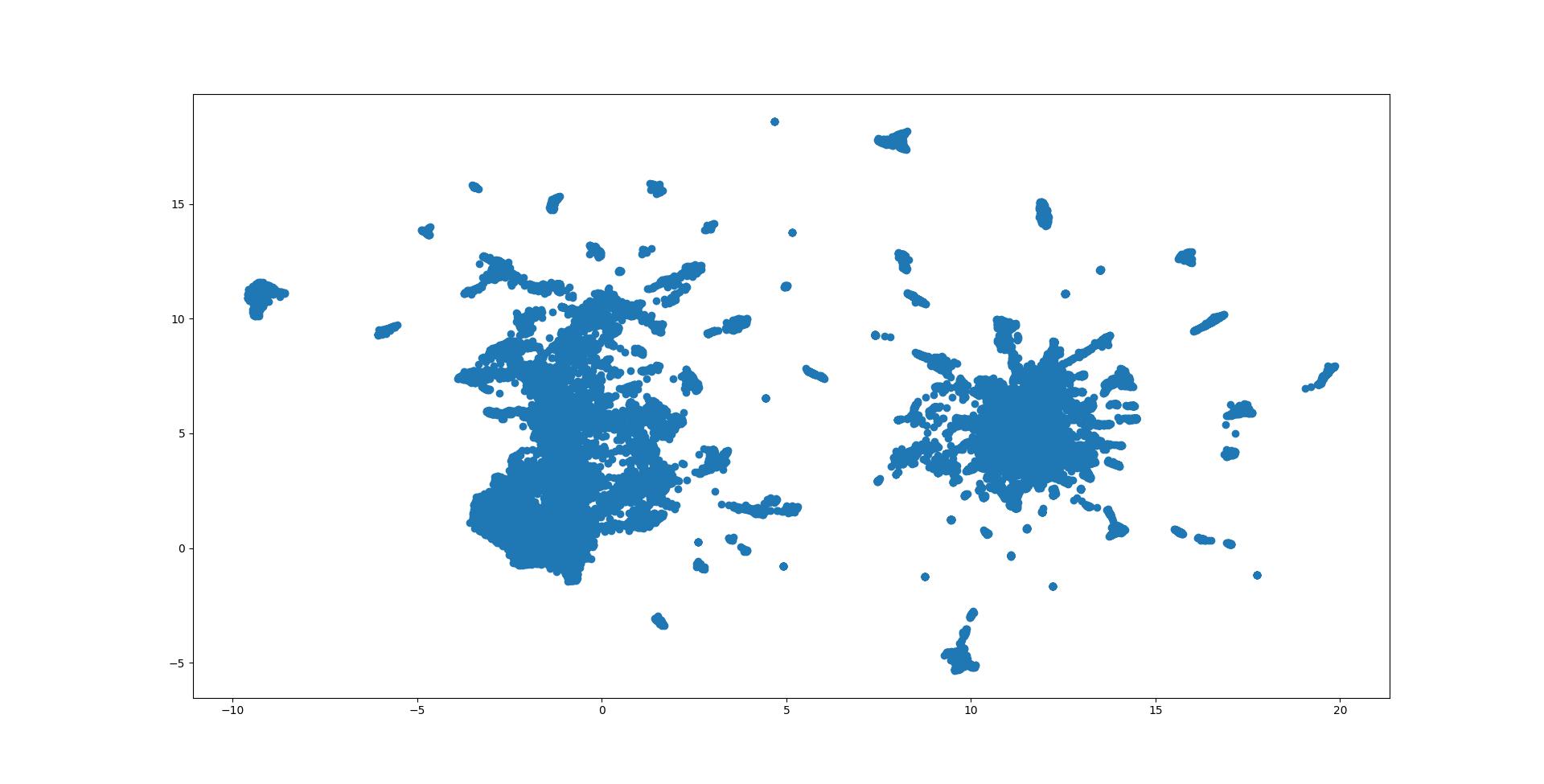
Umap
UMAP(Uniform Manifold Approximation and Projection for Dimension Reduction,一致的流形逼近和投影以进行降维)。 一致的流形近似和投影(UMAP)是一种降维技术,类似于t-SNE,可用于可视化,但也可用于一般的非线性降维。
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import mtutils as mtfrom sklearn.manifold import TSNEfrom sklearn.preprocessing import StandardScalerimport matplotlib.pyplot as pltimport numpy as npimport umap'fea.json' )list (fea_info.values())2 )0 ], embedding[:, 1 ])pass
测试效果
参考资料
文章链接:https://www.zywvvd.com/notes/study/machine-learning/dimension-reduction/dedu-dim/