本文最后更新于:2024年5月11日 下午
拟合数学模型时,如果数据中存在少量的异常值,直接拟合会使得模型出现偏差,RANSAC可以有效解决此类问题。
简介
-
随机抽样一致算法(RANdom SAmple Consensus,RANSAC),采用迭代的方式从一组包含离群的被观测数据中估算出数学模型的参数,该算法最早由 Fischler 和 Bolles 于1981年提出。
-
算法通过从数据中随机多次采样,拟合模型,寻找误差最小的模型作为输出结果,根据大数定律,随机性模拟可以近似得到正确结果。
-
RANSAC算法被广泛应用在计算机视觉领域和数学领域,例如直线拟合、平面拟合、计算图像或点云间的变换矩阵、计算基础矩阵等方面。
算法假设
-
数据中包含正确数据和异常数据(或称为噪声)。正确数据记为内点(inliers),异常数据记为外点(outliers)。
-
对于给定一组正确的数据,存在可以计算出符合这些数据的模型参数的方法。
数学原理
- 假设内点在整个数据集中的概率为t,即:
$$
t=\frac{n_{\text {inliers }}}{n_{\text {inliers }}+n_{\text {outliers }}}
$$
- 确定该问题的模型需要n个点,这个n是根据问题而定义的,例如拟合直线时n为2,平面拟合时n=3,求解点云之间的刚性变换矩阵时n=3,求解图像之间的射影变换矩阵是n=4,等等。
- k表示迭代次数,即随机选取n个点计算模型的次数。P为在这些参数下得到正确解的概率。
- 可以得到,n个点都是内点的概率为 $t^n$,则n个点中至少有一个是外点的概率为
$$
1-t^n
$$
- $ \left( 1 - t ^ {n} \right) ^ {k} $ 表示k次随机抽样中都没有找到一次全是内点的情况,这个时候得到的是错误解,那么成功的概率为: $$ P=1-\left(1-t^{n}\right)^{k} $$
-
内点概率t是一个先验值,可以给出一些鲁棒的值。同时也可以看出,即使t给的过于乐观,也可以通过增加迭代次数k,来保证正确解的概率P。
-
同样的,可以通过上面式子计算出来迭代次数k,即假设需要正确概率为P(例如需要99%的概率取到正确解),则:
$$
k=\frac{\log (1-P)}{\log \left(1-t^{n}\right)}
$$
算法描述
以空间中多个数据点拟合直线为例
- 要得到一个直线模型,需要两个点唯一确定一个直线方程。所以第一步随机选择两个点。
- 通过这两个点,可以计算出这两个点所表示的模型方程y=ax+b。
- 将所有的数据点套到这个模型中计算误差。
- 找到所有满足误差阈值的点。
- 重复(1)~(4),直到达到一定迭代次数后,选出满足阈值点数量最多的模型作为问题的解。
示例
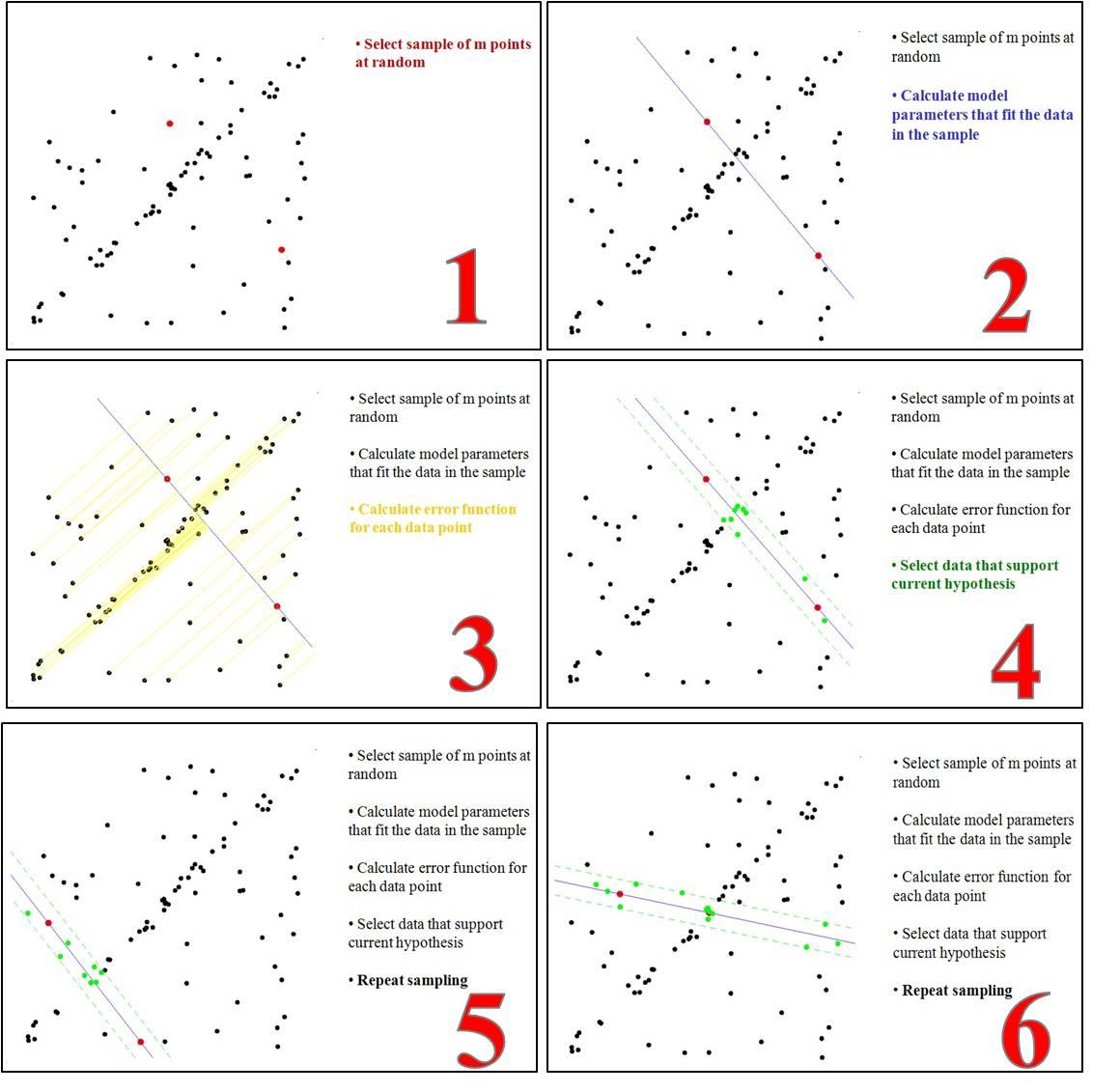
- 通过多次迭代,可以有很大的概率得到正确拟合的直线

- 而由于异常数据的干扰,直接用最小二乘拟合很容易带来偏差,这就是 RANSAC 排除异常数据带来的优势
示例代码
1 | |
-
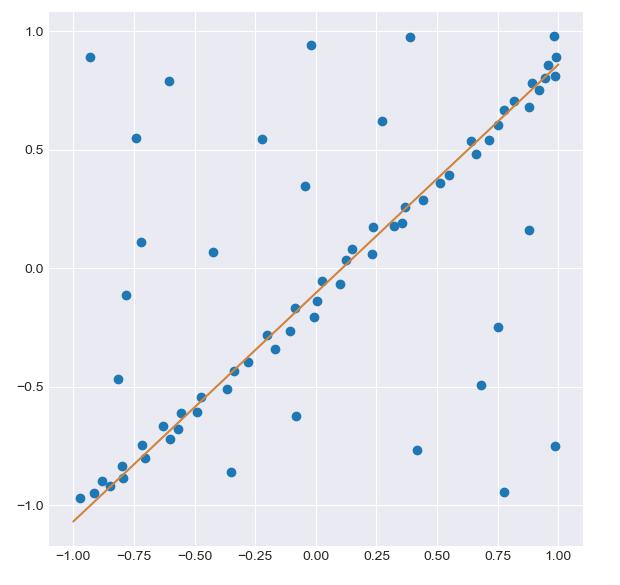
运行结果
运行 RANSAC 实现的结果。橙线显示了迭代法找到的最小二乘参数,成功地忽略了异常点。
参考资料
- https://blog.csdn.net/u010128736/article/details/53422070
- https://en.wikipedia.org/wiki/Random_sample_consensus
文章链接:
https://www.zywvvd.com/notes/study/probability/ransac/ransac/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付