本文最后更新于:2024年5月11日 下午
Proposal 是检测网络很重要的内容,一路以来的检测网络一直在其中做文章,本文介绍 Sparse R-CNN, 该网络设置可学习的候选框,设计了行之有效的端到端检测网络。
背景
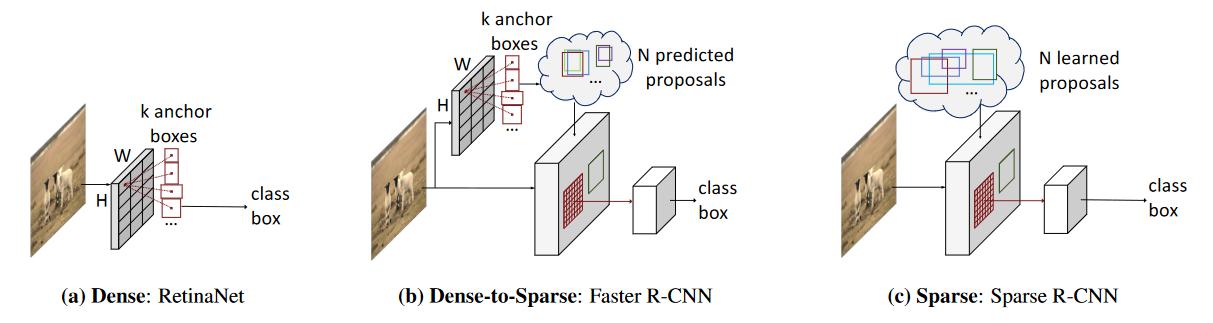
- 早期的目标检测都严重依赖设置密集的目标候选框(如 R-CNN),比如对特征图$(H\times W)$ 每个像素设置 $k$ 个anchor boxes,这样就会有成千上万个anchors $(H\times W\times k)$,这样过于低效,此类网络在文章中被描述为 dense (稠密候选框) 的检测网络。
- 之后网络逐渐向着稀疏化候选框的方向发展,经典的代表是 Faster R-CNN 网络,使用一个子网络从多个候选框中选出 N 个预测的 proposals,用于检测其中是否存在目标物体,该网络也起到了将 Dense 候选框转化为 Sparse 候选框的作用,但是毕竟存在 Dense 候选框的过程,文章中称此类网络为 Dense-to-Sparse 的检测网络
- 按照这个节奏,文章提出了彻头彻尾的 Sparse 检测网络,但是想要获得初始就 Sparse 的有效候选框谈何容易,直觉上觉得初始稀疏的候选框必须用到数据的先验信息,不然从何而来呢,于是文章顺理成章地提出了经过学习的初始稀疏候选框检测网络,由于自始至终候选框都是稀疏的,被称为 Sparse 检测网络
简介
-
Sparse-RCNN提出一种纯稀疏(purely sparse)的图像目标检测方法,设置N个可学习的object proposals,用于检测头的分类和位置检测。
-
Sparse RCNN避免了人工设置候选框的大量超参数以及多对一的正负样本分配。更重要的是,最终的预测结果可以直接输出而不需要NMS(非极大抑制)。并且性能与表现良好的检测器相当。
-
文章主要使用以下几个技术或方法:
-
Learnable proposal box 可学习建议框,网络设置固定数量的方框作为学习参数。
-
Learnable proposal feature 可学习建议特征向量,与建议框一一绑定,补充高层抽象特征信息。
-
Dynamic instance interactive head 动态实体交互检测头,建议框、RoI、特征向量三者绑定,每个 RoI 单独检测,不存在正负样本均衡问题,也不需要NMS操作。
-
Sparse R-CNN
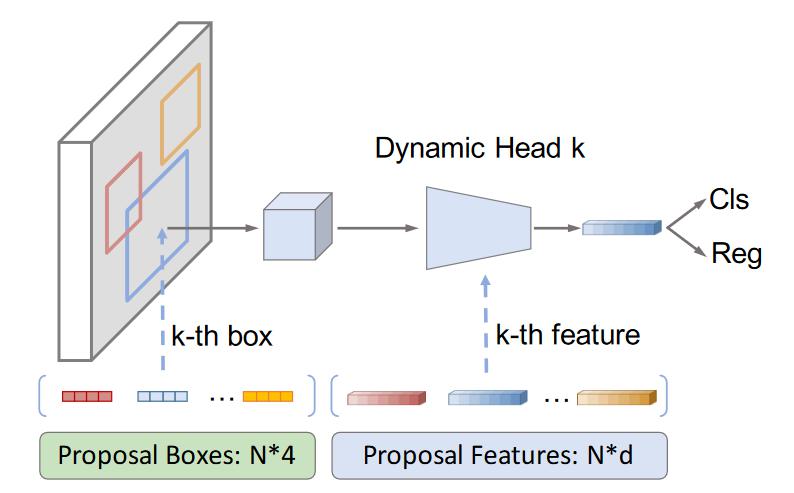
- Sparse RCNN的检测头如上图所示,和RCNN系列十分类似。检测的输入是image、proposal boxes 和 proposal feature,输出是分类和回归结果。
- 对比Faster RCNN的结构:
- Sparse RCNN 没有 RPN 结构, Proposal Boxes 不是由 RPN 产生, 而是一组预设的可学习参数。用一个4维向量就能表示一个anchor boxes, N*4 的向量就是预设了N个可学习anchor,相较于滑动采样的密集 anchor, 数量要少的多。(N通常设置100-300个)。
- Sparse RCNN 第一步将输入 image 和 Proposal Boxes融合,相当于用N个方框从原始image 抠图然后对齐, 这里对应 Faster RCNN 的 RoI Pooling 操作。
- 建议区域抠出来之后,Sparse 并没有像 Faster RCNN 简单地接两个全连接层就完事了。而是与 Proposal Feature 再做一次卷积, 然后接两层全连接层做分类和回归。其中Proposal Feature和Proposal Boxes一样, 也是一个可学习的参数。
网络信息流
graph TD
A[Image]
B(Backbone)
C[Feature]
I((融合))
J((动态实例交互))
D[Proposal Boxes]
E[Roi Feature]
F[Proposal Features]
G(Fully Connected Layer)
H[Cls Results]
K[Feature]
L[Reg Results]
A --> B
B --> C
C --> I
D --> I
I --> E
E --> J
F --> J
J --> K
K --> G
G --> H
G --> L
style A fill:#ff8
style D fill:#ff8
style F fill:#ff8
style H fill:#9ff
style L fill:#9ff
- 图像、可学习的候选框和候选框对应的特征作为网络输入(黄色),分类、回归结果作为输出(蓝色),构建了网络信息流
可学习候选框 、候选特征
proposal box 和 proposal feature是网络中要学习的两个重要参数。两者的数目相同(都为N)且一一对应,每一个proposal box得到的RoI只和它对应的proposal feature做进一步的融合。
- proposal box 是一个4维的向量,代表一个方框(目标位置),其学习的内容可以理解为物体位置的统计量。
- proposal feature是一个高维的向量(比如256),它蕴含着与其匹配proposal box对象的更为深层次的更抽象的信息。因为proposal box只记录了对象的位置信息,对于其他更为抽象的细节信息完全丢失了。proposal feature是为了丰富proposal box对象的特征信息。或者是类似于SENet,是针对proposal box加权的注意力机制。
动态实例交互头
-
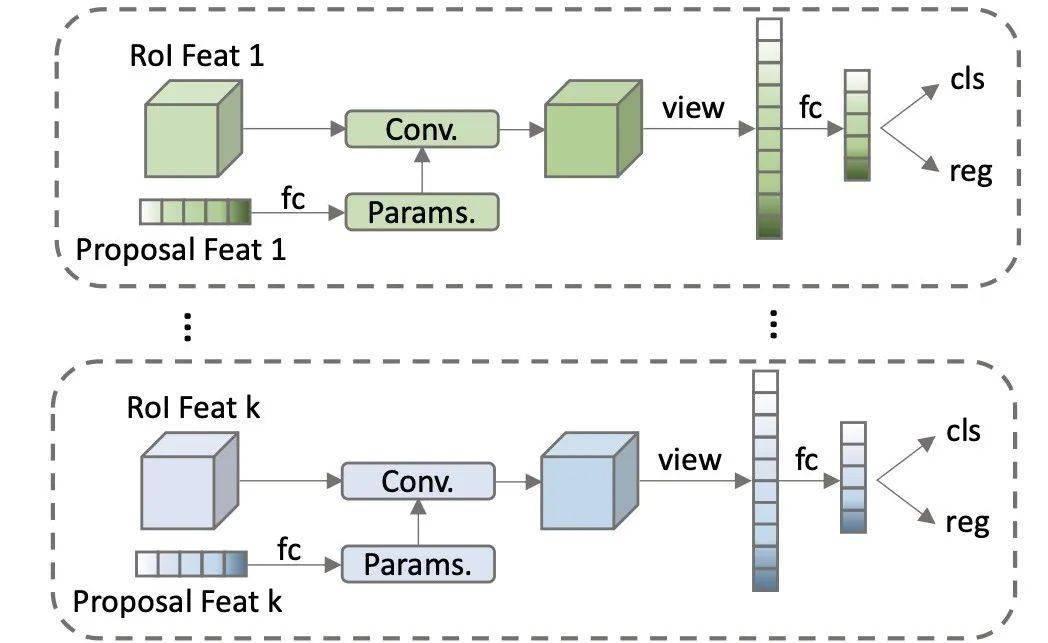
文章设计了动态实力交互检测头 (Dynamic instance interactive head) 。
-
学习到的proposal boxes可以理解为图像中可能出现物体的位置的统计值,这样coarse的表征提取出来的RoI feature显然不足以精确定位和分类物体。于是,一种特征层面的candidates被引入,称为proposal features,这也是一组可学习的参数,N*d。
-
N代表object candidates的个数,与proposal boxes一一对应;d代表feature的维度,一般为256。这组proposal features与proposal boxes提取出来的RoI feature做一对一的交互,从而使得RoI feature的特征更有利于定位和分类物体。相比于原始的2-fc Head,这样的设计称为Dynamic Instance Interactive Head。
-
从上面的介绍我们知道,proposal box、RoI、 proposal feature这三者是绑定在一起的,因此作者对每个RoI都“单独”设置一个检测头,这样N个proposal boxes就有N个检测头。
-
检测头输出N个proposal boxes, 使用 Hungarian算法 与目标targets建立二分匹配图。
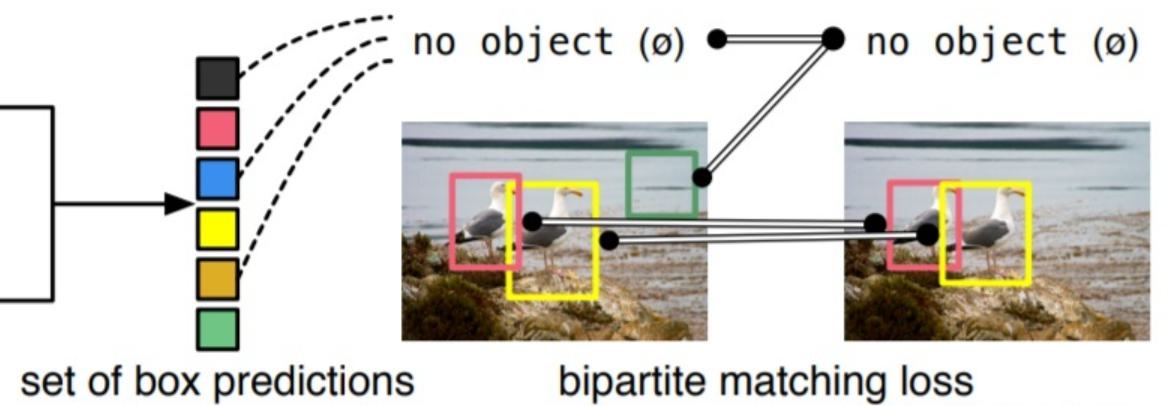
生成了3个proposal boxes,gt中只有两个targets. 没有目标的 proposal boxes 与一种特殊的类别 no object 相匹配。
损失函数
-
每一对box-target匹配的损失函数:
$$ \mathcal{L}=\lambda_{\text {cls }} \cdot \mathcal{L}_{\text {cls }}+\lambda_{L 1} \cdot \mathcal{L}_{L 1}+\lambda_{\text {giou }} \cdot \mathcal{L}_{\text {giou }} $$ -
将二分匹配图中所有的匹配的损失函数求和,就获得最终的损失函数值,用于反向传播更新权重。
网络性能
在COCO数据集上是实现44.5AP,同时能够达到22FPS(ResNet-50 FPN)的速度。
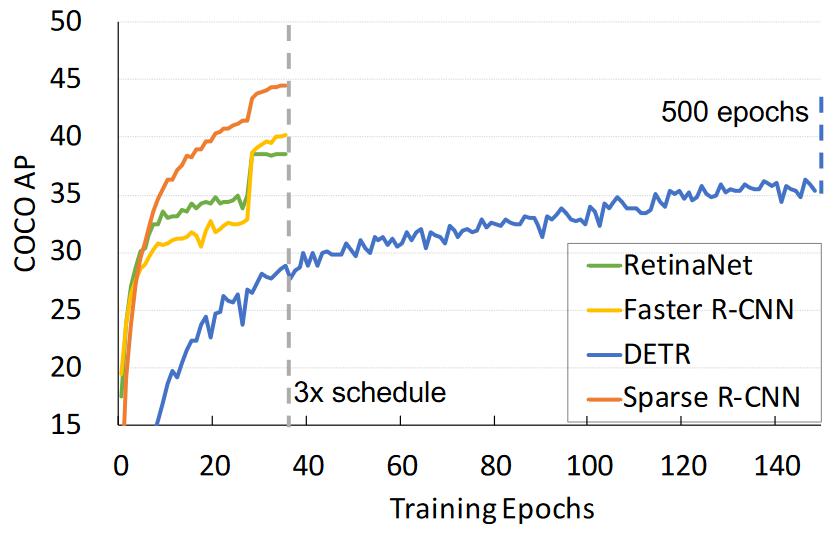
原始论文
开源代码
参考资料
- Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
- https://zhuanlan.zhihu.com/p/335822817
- https://blog.csdn.net/you2336/article/details/111089176
- https://www.sohu.com/a/434372564_610522
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/detection/sparse-rcnn/sparse-rcnn/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付