本文最后更新于:2024年5月11日 下午
机器学习中经常会在损失函数中加入正则项,称之为正则化(Regularize)。
简介
在损失函数中加入正则项,称之为正则化。
目的:防止模型过拟合
原理:在损失函数上加上某些规则(限制),缩小解空间,从而减少求出过拟合解的可能性
理解正则化
- 以最简单的线性模型为例
- 我们在统计学习中接触到线性回归的最小二乘估计和正则化的岭回归与拉索回归。
- 在最小二乘估计中加入正则项后,我们得到岭估计:
- 在数学上我们可以证明岭估计的参数模要严格小于最小二乘估计的参数模,换句话说,我们可以认为加入L2正则项后,估计参数长度变短了,这在数学上被称为特征缩减(shrinkage)。
shrinkage
-
指训练求解参数过程中考虑到系数的大小,通过设置惩罚系数,使得影响较小的特征的系数衰减到0,只保留重要特征的从而减少模型复杂度进而达到规避过拟合的目的。常用的 shinkage的方法有 Lasso(L1正则化)和岭回归(L2正则化)等。
-
采用shrinkage方法的主要目的
- 一方面因为模型可能考虑到很多没必要的特征,这些特征对于模型来说就是噪声,shrinkage可以通过消除噪声从而减少模型复杂度;
- 模型特征存在多重共线性(变量之间相互关联)的话可能导致模型多解,而多解模型的一个解往往不能反映模型的真实情况,shrinkage可以消除关联的特征提高模型稳定性。
线性模型的损失函数
- 对于包括多元线性回归模型、逻辑回归和SVM在内的线性模型,我们需要利用测试集来最小化损失函数从而求得模型参数 $w$。
- 在线性模型的损失函数中加入正则项可以得到目标函数。其中 $λ$ 被称为正则化系数,当 $λ$ 越大时,正则化约束越强。
$$
\frac{1}{2} \sum_{i=1}^{N} y_{i}-w^{T} \phi\left(x_{i}\right)^{2}+\frac{\lambda}{2} \sum_{i=1} M\left|w_{j}\right|^{q}
$$
- 通过令目标函数导函数为0,我们可以得到参数的表达式为:
选择L2正则项的原因
- 给损失函数加上的正则化项可以有多种形式,下面给出了正则化的一般形式:
$$
\frac{1}{2} \sum_{i=1}^{N} y_{i}-w^{T} \phi\left(x_{i}\right)^{2}+\frac{\lambda}{2} \sum_{i=1} M\left|w_{j}\right|^{q}
$$
- 其中 $M$ 是参数的个数,也是模型特征的维数; $q$ 是正则项的阶数,L2 正则项的 $q$ 为 2。
- 考虑到在高维数据下很难给出正则项的几何意义,我们假设数据源只有两个特征:
- $q$ 不同取值时正则项的函数值图像:
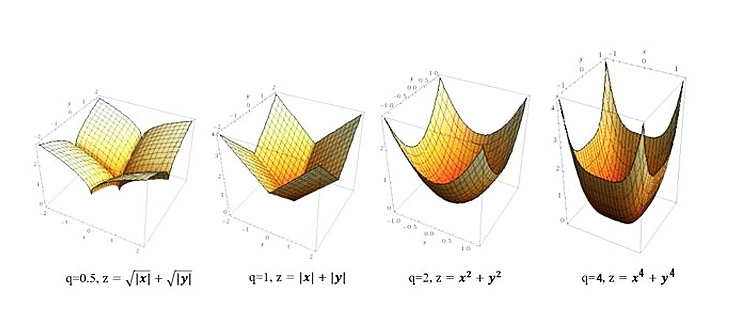
- $q$ 不同函数值图像对应的等高线(即俯视图)为:
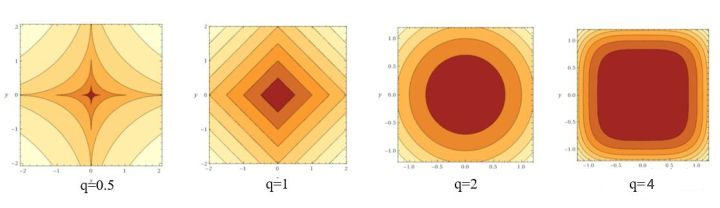
- 最小化目标函数时,可以看做在控制损失函数不变的情况时令正则项最小化,几何意义如下所示:蓝色圈表示没有限制的损失函数随着 $w$ 迭代寻找着最小化的过程的 $E(w)$ 函数等高线(同个圆上的损失函数值相同),蓝色圈和橙色圈之和就是目标函数值,目标函数最小化的点往往出现在蓝圈和橙圈相交的点即目标函数最小化的参数值 $w∗$ 。
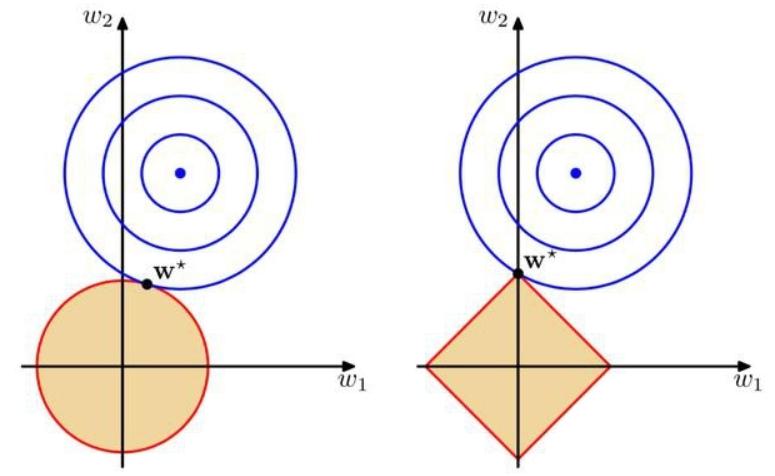
- 可以看到,L1 正则化的最优参数值 $w∗$ 恰好是 $w_1=0$ 的时候,意味着我们剔除了模型中一个特征(系数为0等价于剔除该特征),从而达到了降低模型复杂度的目的。在这个意义上L1正则化效果要优于L2正则化,但L1存在拐点不是处处可微,从而L2正则化有更好的求解特性。
总结
-
梳理一下,正则化有多种方式,包括L0(向量中非零元素个数),L1(向量中元素绝对值之和),L2(向量的模)。但是L0范数的求解是个NP完全问题,而L1也能实现稀疏并且比L0有更好的优化求解特性而被广泛应用。
-
L2范数指各元素平方和后开根的值,可令 w 每个元素接近于0,虽然不如L1更彻底地降低模型复杂度,但是由于处处可微降低了计算难度
参考资料
文章链接:
https://www.zywvvd.com/notes/study/machine-learning/regular-term/regular-term/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付