本文最后更新于:2024年5月11日 下午
VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)20年的一篇端到端的TTS论文。结合VAE+flow+gan三种方法的语音合成模型。 。
简介
这篇文章发表在 ICML 2021 会议上,当时的 TTS(test-to-speech)工作效果好的都以两阶段的为主,端到端的工作效果一般。
这篇文章使用 CVAE + Flow + GAN 实现了端到端的媲美两阶段 TTS 的性能。
核心部分
- CVAE
- 基于变分推理的对齐估计
- 提高综合质量的对抗性训练
流程图
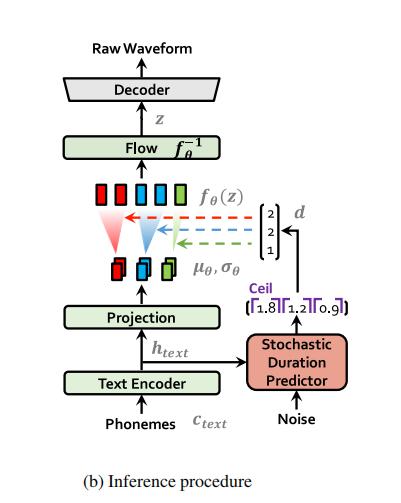
该模型的整体架构由后验编码器、先验编码器、解码器、判别器和随机持续时间预测器组成。后验编码器和判别器只用于训练,不用于推断。
-
训练流程
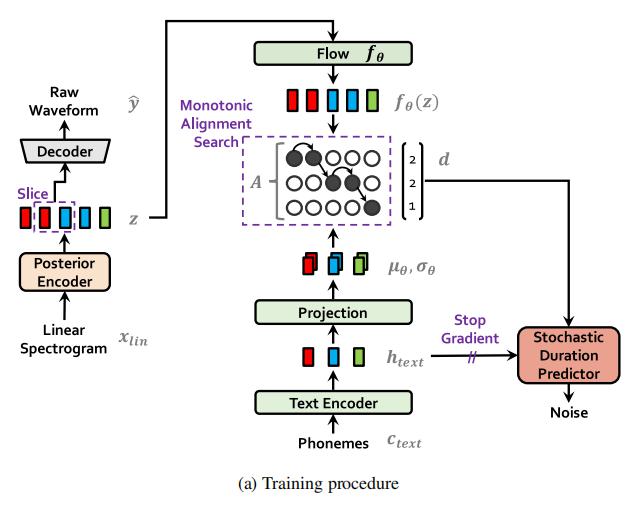
-
推理流程
变分推断 (Variational Inference)
对应文章 2.1 节
核心公式:
$$ \log p_{\theta}(x \mid c) \geq \mathbb{E}_{q_{\phi}(z \mid x)}\left[\log p_{\theta}(x \mid z)-\log \frac{q_{\phi}(z \mid x)}{p_{\theta}(z \mid c)}\right] $$这里 $c$ 为条件,可以理解为文本;
$\log p_{\theta}(x \mid c) $ 为我们要最大化的对数概率,$\theta$ 为模型参数,直接最大化这个模标很难,我们转而去最大化化其变分下界,由于带有条件,这里用到的是条件变分下界。
$ p_{\theta}(z \mid c) $ 表示条件 $c$ 下潜变量 $z$ 的先验分布;
$ p_{\theta}(x \mid z) $ 是 $x$ 的似然,可以理解为给定 $z$ 拿到 $x$ 的概率,也就是解码器;
$ q_{\phi}(z \mid x) $ 是 $x$ 的近似后验分布;
右边项也就是 $ q_{\phi}(z \mid x) $ 和 $ p_{\theta}(z \mid c) $ 的 KL散度,最小化这个散度就得到了很好的 $ q_{\phi}(z \mid x) $ 。
重构损失(RECONSTRUCTION LOSS)
对于目标数据,模型训练过程中使用 mel 谱代替原始声波,用 $x_{mel}$ 表示。
目的是:通过使用一个近似人类听觉系统响应的mel缩放来提高感知质量。
采样 $z$,通过解码器得到 $\hat{y} $ ,将 $ \hat{y} $ 转换到 mel 谱得到 $ \hat{x}_{m e l} $。
重构损失为二者之间的 $L_1$ 损失:
$$ L_{\text {recon }}=\left\|x_{m e l}-\hat{x}_{m e l}\right\|_{1} $$KL散度 (KL-DIVERGENCE)
先验编码器 $c$ 的输入条件由从文本中提取的音素 $c_{text}$ 和音素与隐变量之间的对齐A组成。
A 是一个具有 $| c_{text }| × | z |$ 维度的硬单调注意力矩阵,表示每个输入音素扩展到与目标语音时间对齐的长度。
由于没有用于对齐的真值标签,我们必须在每次训练迭代时估计对齐,我们将在之后讨论。
在问题设置中,我们旨在为后验编码器提供更多的高分辨率信息。因此,我们使用目标语音 $x_{lin}$ 的线性尺度语谱图作为输入,而不是 mel 语谱图。注意修改后的输入并不违背变分推断的性质。
KL 散度:
$$ \begin{array}{r}L_{k l}=\log q_{\phi}\left(z \mid x_{l i n}\right)-\log p_{\theta}\left(z \mid c_{\text {text }}, A\right) \\ z \sim q_{\phi}\left(z \mid x_{l i n}\right)=N\left(z ; \mu_{\phi}\left(x_{l i n}\right), \sigma_{\phi}\left(x_{l i n}\right)\right)\end{array} $$因子化正态分布被用来参数化先验和后验编码器。
增加先验分布的表达能力对于生成真实样本非常重要。因此,我们在因式分解的正态先验分布的基础上应用了 flow,它允许简单分布按照变量的变化规律可逆地转化为更复杂的分布:
对齐估计(Alignment Estimation)
单调对齐搜索(MONOTONIC ALIGNMENT SEARCH)
为了估计输入文本和目标语音之间的对齐度A,我们采用单调对齐搜索( MAS, MONOTONIC ALIGNMENT SEARCH)。该方法采用对经过标准化流的数据进行最大似然估计搜索对齐结果:
$$ \begin{aligned} A & =\underset{\hat{A}}{\arg \max } \log p\left(x \mid c_{\text {text }}, \hat{A}\right) \\ & =\underset{\hat{A}}{\arg \max } \log N\left(f(x) ; \mu\left(c_{\text {text }}, \hat{A}\right), \sigma\left(c_{\text {text }}, \hat{A}\right)\right)\end{aligned} $$Monotonic Alignment Search是一种用于音频信号处理的算法,用于将一个语音序列与一个模板进行比对。该算法使用动态规划来寻找最佳匹配,并且相邻的时间帧在匹配的过程中是单调递增的。换句话说,它不允许在匹配过程中跳过任何帧,这使得它能够更准确地匹配序列。
Monotonic Alignment Search本身是一种基于音频信号的处理算法,它使用动态规划来找到最佳匹配。在语音识别中,我们通常会将说话者的声音转换成文本,并与先前知道的正式文本进行比对,以便识别所说的内容。因此,可以将Monotonic Alignment Search视为语音识别中的一部分,其中它帮助确定了音频信号和文本之间的对应关系。
具体而言,Monotonic Alignment Search用于将一个语音序列与一个模板进行比对,以确定它们之间的相似度。如果我们有一个已知的正式文本,那么我们可以将其转换为音频信号,并使用Monotonic Alignment Search算法来将其与被识别的语音信号进行匹配。这样,我们就可以得到一个包含文本和语音之间对应关系的对齐图表,从而正确地识别出所说的内容。
当我们要将一个人的发音与一个已知单词进行匹配时,Monotonic Alignment Search算法可以很好地帮助我们确定哪些音素在哪个时间点被发出。
例如,假设我们有一个单词“hello”作为模板,并且我们想要检测某个人是否正确地发出了这个单词。我们可以录制这个人说话的音频,并将其与模板进行比较。使用Monotonic Alignment Search算法,我们可以对齐这两段音频,找到最可能的匹配。
在这个过程中,算法会逐步比对语音信号和模板中的每一个时间帧,确保相邻的时间帧是单调递增的。如果它发现某个时间帧在整个匹配过程中无法对齐,那么就会尝试跳过该时间帧,以寻找更好的匹配。最终,算法将输出一个包含匹配结果的对齐图表,以及每个时间帧的对应关系。这样,我们就可以知道哪些音素在哪个时间点被发出,从而判断该人是否正确地发出了“hello”这个单词。
—— gpt3.5
直接在我们的设定中应用 MAS 是困难的,因为我们的目标是 ELBO,而不是精确的对数似然。因此,我们重新定义 MAS 来寻找使 ELBO 最大化的对齐,这就转化为寻找使潜变量 $z$ 的对数似然最大化的对齐:
$$ \begin{array}{l}\underset{\hat{A}}{\arg \max } \log p_{\theta}\left(x_{\text {mel }} \mid z\right)-\log \frac{q_{\phi}\left(z \mid x_{l i n}\right)}{p_{\theta}\left(z \mid c_{\text {text }}, \hat{A}\right)} \\ =\underset{\hat{A}}{\arg \max } \log p_{\theta}\left(z \mid c_{\text {text }}, \hat{A}\right) \\ \quad=\log N\left(f_{\theta}(z) ; \mu_{\theta}\left(c_{\text {text }}, \hat{A}\right), \sigma_{\theta}\left(c_{\text {text }}, \hat{A}\right)\right)\end{array} $$由于修改后的公式格式与原始 MAS 相同,我们可以不加修改地使用原MAS实现。
持续时间估计(DURATION PREDICTION FROM TEXT)
将估计出的对齐 A 进行求和可以计算每个单词的持续时长,但是这种计算得到的时长过于固定单一,不像真实的人在讲话中会有不同的语气。为了生成类似人类的语音节奏,我们设计了一个随机时长预测器,使其样本服从给定的时长分布音素。随机持续时间预测器是一种基于流的生成模型,通常通过最大似然估计进行训练。
具体来说,我们引入两个随机变量u和ν,它们与持续时间序列d具有相同的时间分辨率和维度,分别用于变分去量化和变分数据增强。我们将u的支持度限制在 $[ 0,1 )$,使得差分 $d - u$ 成为一个正实数序列,并将ν和d通道级联,构成高维的隐表示。我们通过一个近似后验分布$q φ ( u , ν | d , c{text})$对两个变量进行采样。得到的目标是音素时长的对数似然的一个变分下界:
$$ \log p_{\theta}\left(d \mid c_{\text {text }}\right) \geq \mathbb{E}_{q_{\phi}\left(u, \nu \mid d, c_{\text {text }}\right)}\left[\log \frac{p_{\theta}\left(d-u, \nu \mid c_{t e x t}\right)}{q_{\phi}\left(u, \nu \mid d, c_{\text {text }}\right)}\right] $$那么训练损失 $L_{dur}$ 就是负的变分下界。我们将阻止输入梯度反向传播的停止梯度算子应用到输入条件中,使得持续时间预测器的训练不影响其他模块的训练。
采样程序相对简单;音素时长通过随机时长预测器的逆变换从随机噪声中采样,然后将其转换为整数。
对抗训练(Adversarial Training)
为了在我们的学习系统中采用对抗训练,我们添加了一个判别器 D 来区分解码器 G 产生的输出和真实波形 $y$。在这项工作中,我们使用两种类型的损失成功地应用于语音合成;最小二乘损失函数用于对抗训练,额外的特征匹配损失用于训练生成器:
$$ \begin{aligned} L_{a d v}(D) & =\mathbb{E}_{(y, z)}\left[(D(y)-1)^{2}+(D(G(z)))^{2}\right] \\ L_{a d v}(G) & =\mathbb{E}_{z}\left[(D(G(z))-1)^{2}\right] \\ L_{f m}(G) & =\mathbb{E}_{(y, z)}\left[\sum_{l=1}^{T} \frac{1}{N_{l}}\left\|D^{l}(y)-D^{l}(G(z))\right\|_{1}\right]\end{aligned} $$式中:T 为判别器的总层数;
$D^l$ 输出第 $l$ 层特征个数为 $N^l$的判别器的特征图。
值得注意的是,特征匹配损失可以看作是在判别器的隐藏层中测量的重构损失,作为VAEs的元素级重构损失的替代。
总损失函数
结合VAE和GAN训练,我们的条件VAE训练的总损失可以表示如下:
$$
L_{v a e}=L_{r e c o n}+L_{k l}+L_{d u r}+L_{a d v}(G)+L_{f m}(G)
$$
原始论文
### 参考资料- Kim J, Kong J, Son J. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech[C]//International Conference on Machine Learning. PMLR, 2021: 5530-5540.
- https://zhuanlan.zhihu.com/p/560245337?utm_id=0
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/tts/vits/vits/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付