本文最后更新于:2024年5月7日 下午
Pytorch 框架支持多卡分布式并行训练网络,可以利用更大的显存得到更大的 batchsize,同时也会倍增训练速度,本文记录 Pytorch 多卡训练实现过程。
简介
-
Pytorch 支持两种多卡并行训练的方案,DataParallel 和 DistributedDataParallel
-
主要区别在于 DataParallel 为单一进程控制多个显卡,配置简单但显卡资源利用率不够高,DistributedDataParallel 相对复杂,胜在高效
-
将单卡训练的 Pytorch 流程修改为多卡并行需要对代码中的关键节点进行调整,Github 上有一个仓库做了很优质的 demo,可以用来参考,在此感谢这位大佬
DataParallel
DataParallel 可以帮助我们(使用单进程控)将模型和数据加载到多个 GPU 中,控制数据在 GPU 之间的流动,协同不同 GPU 上的模型进行并行训练(细粒度的方法有 scatter,gather 等等)。
DataParallel 使用起来非常方便,我们只需要用 DataParallel 包装模型,再设置一些参数即可。需要定义的参数包括:参与训练的 GPU 有哪些,device_ids=gpus;用于汇总梯度的 GPU 是哪个,output_device=gpus[0] 。DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总:
1 | |
值得注意的是,模型和数据都需要先 load 进 GPU 中,DataParallel 的 module 才能对其进行处理,否则会报错:
1 | |
汇总一下,DataParallel 并行训练部分主要与如下代码段有关:
1 | |
在使用时,使用 python 执行即可:
1 | |
DistributedDataParallel
实现原理
- 使用 nn.DistributedDataParallel 进行Multiprocessing可以在多个gpu之间复制该模型,每个gpu由一个进程控制。(如果你想,也可以一个进程控制多个GPU,但这会比控制一个慢得多。也有可能有多个工作进程为每个GPU获取数据,但为了简单起见,本文将省略这一点。)这些GPU可以位于同一个节点上,也可以分布在多个节点上。每个进程都执行相同的任务,并且每个进程与所有其他进程通信。只有梯度会在进程/GPU之间传播,这样网络通信就不至于成为一个瓶颈了。
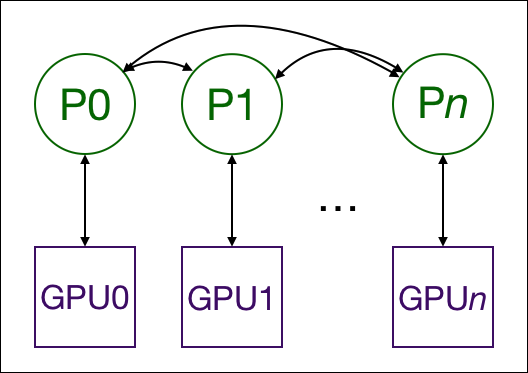
- 训练过程中,每个进程从磁盘加载自己的小批(minibatch)数据,并将它们传递给自己的GPU。每个GPU都做它自己的前向计算,然后梯度在GPU之间全部约简。每个层的梯度不仅仅依赖于前一层,因此梯度全约简与并行计算反向传播,进一步缓解网络瓶颈。在反向传播结束时,每个节点都有平均的梯度,确保模型权值保持同步(synchronized)。
- 上述的步骤要求需要多个进程,甚至可能是不同结点上的多个进程同步和通信。而Pytorch通过它的 distributed.init_process_group 函数实现。这个函数需要知道如何找到进程0(process 0),一边所有的进程都可以同步,也知道了一共要同步多少进程。每个独立的进程也要知道总共的进程数,以及自己在所有进程中的阶序(rank),当然也要知道自己要用那张GPU。总进程数称之为 world size。最后,每个进程都需要知道要处理的数据的哪一部分,这样批处理就不会重叠。而Pytorch通过 nn.utils.data.DistributedSampler 来实现这种效果。
实现过程
在 pytorch 1.0 之后,官方终于对分布式的常用方法进行了封装,支持 all-reduce,broadcast,send 和 receive 等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信。官方也曾经提到用 DistributedDataParallel 解决 DataParallel 速度慢,GPU 负载不均衡的问题,目前已经很成熟。
- 现在假设我们已经有一套单卡训练 Pytorch 模型的代码,包含
模型加载,数据加载,模型训练,模型验证,模型保存等模块,此时我们要将该套代码改为分布式多卡并行训练 - 总体来看需要修改的流程如下
graph LR
multi-process[多进程启动器]
dist-init[分布式初始化]
dist-sampler[分布式数据集]
dist-model[分布式模型]
loss-collect[损失函数汇总]
model-save[保存模型]
multi-process --> dist-init
subgraph Worker: local_rank
dist-init --> dist-sampler
dist-sampler --> dist-model
dist-model -- 训练 --> loss-collect
loss-collect --> model-save
end
配置好需要用到的显卡id
1 | |
配置全局相同的随机数种子
- 为了数据集划分时有相同的划分方式,最好开局前配置好统一的随机种子
1 | |
设计单个进程的工作流程
不同显卡各自需要一个进行进行控制,每个进程由不同
local_rank区分,单个显卡对应着携带某个local_rank的Worker函数
- 需要将训练流程整合到一个函数中(此处命名为
_train) - 函数内部执行
数据加载,模型加载,前向推理,梯度回传,损失汇总,模型保存的工作
多进程启动
- 设计好工作流函数
Worker后需要用多进程的方式启动 nprocs参数中填入进程数量,一般为需要使用的显卡数量
1 | |
- 函数会将
0 - (device_num-1)范围内的整数依次作为第一个参数分配给一个进程执行self._train函数 - 如果有其他参数可以放入 args 中
- 如果在 Windows 下运行需要在
__name__ == '__main__'下:
1 | |
初始化分布式进程
- 此时进入到了 Pytorch 子进程在流程函数 Worker 的工作流程
- 流程开始需要对当前进程进行初始化
1 | |
- 其中 rank 为多进程启动时分配的数值
初始化分布式模型
分布式训练需要将模型转换为分布式模型
- 初始化正常的模型
model - 放入显卡显存中
1 | |
- 创建分布式模型
1 | |
加载分布式数据
分布式训练需要分布式数据
- 正常创建
Dataset对象dataset - 生成分布式模型采样器
1 | |
- 将分布式采样器放入到
Dataloader初始化参数中,此时shuffle参数需要设置为False
1 | |
- 随后可以正常训练,进行前向推导和反向传播
汇总 Loss
- 此时不同显卡各自执行着自己的任务,互相没有通信,为了获取更准确的evaluate结果,需要将多卡 validation 的 loss 结果汇总
1 | |
保存模型
保存模型其实可以正常保存,不过如果不加处理会有额外开销
- 多进程训练模型时,保存模型在每个进程中都会有这一步操作,如果不加干预每个进程都会保存一遍模型,为了避免这种问题做一些调整即可
1 | |
- 模型保存时仅需保存其中的 module 变量
1 | |
注意
- DistributedDataParallel 中实际的 BatchSize 数量是显卡数与输入dataloader 的 batch_size 参数的乘积。
DataParallel 与 DistributedDataParallel 的区别
关于 nn.DataParallel (以下简称DP) 和 DistributedDataParallel (以下简称DDP) 的区别
- DDP通过多进程实现的。也就是说操作系统会为每个GPU创建一个进程,从而避免了Python解释器GIL带来的性能开销。而DataParallel()是通过单进程控制多线程来实现的。还有一点,DDP也不存在前面DP提到的负载不均衡问题。
- 参数更新的方式不同。DDP在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由
rank=0的进程,将其broadcast到所有进程后,各进程用该梯度来独立的更新参数而 DP是梯度汇总到GPU0,反向传播更新参数,再广播参数给其他剩余的GPU。由于DDP各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。而在DP中,全程维护一个 optimizer,对各个GPU上梯度进行求平均,而在主卡进行参数更新,之后再将模型参数 broadcast 到其他GPU.相较于DP, DDP传输的数据量更少,因此速度更快,效率更高。 - DDP支持 all-reduce(指汇总不同 GPU 计算所得的梯度,并同步计算结果),broadcast,send 和 receive 等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信,缓解了进程间通信有大的开销问题。
官方建议使用 DDP,无论是从效率还是结果来看都要稳定一些
错误记录
模型存在不参与梯度计算的变量
- 报错信息
1 | |
-
错误原因
使用 DistributedDataParallel 向服务器部署模型时,发现模型中有变量不参与梯度回传,为了不为这部分参数浪费显卡之间的通信资源,报错督促修正这部分参数
-
解决方案
在 DistributedDataParallel 函数中加入参数
find_unused_parameters=True例如:
1
student_model = torch.nn.parallel.DistributedDataParallel(student_model, device_ids=[rank], find_unused_parameters=True)
模型保存后无法加载
-
问题复现
经过 DataParallel 部署的模型保存到本地,再次加载权重时报错变量名称不匹配
-
错误原因
事实上经过 DataParallel 的模型已经不是原来的模型了,原来模型的变量会被放到
dp_model.module中,因此我们保存时可以仅保存这一部分 -
解决方案
- 仅保存 module 的部分
1
torch.save(m.module.state_dict(), path)- 加载时仍使用 DP
1
2
3m=nn.DataParallel(Resnet18())
m.load_state_dict(torch.load(path))
m=m.module
MASTER_ADDR / MASTER_PORT
- 分布式训练需要地址和端口进行通信,如果没有配置则会报错
1 | |
- 可以在环境变量中配置
1 | |
- 也可以写死在代码中
1 | |
参考资料
- https://pytorch.org/docs/1.8.1/generated/torch.nn.parallel.DistributedDataParallel.html?highlight=distributeddataparallel#torch.nn.parallel.DistributedDataParallel
- https://zhuanlan.zhihu.com/p/105755472
- https://www.zhihu.com/question/67726969
- https://github.com/tczhangzhi/pytorch-distributed
- https://www.cnblogs.com/tnak-liu/p/14615047.html
- https://zhuanlan.zhihu.com/p/206467852
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/pytorch/pytorch-dist-train/pytorch-dist-train/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付