本文最后更新于:2024年5月7日 下午
对比无监督学习最近显示出令人鼓舞的进展,例如在动量对比(MoCo)和SimCLR中。在这篇笔记中,我们通过在MoCo框架中实现SimCLR的两个设计改进来验证它们的有效性。通过对MoCo的简单修改,即使用MLP投影头和更多的数据增强。
简介
-
最近关于从图像进行无监督表征学习的研究正集中在一个被称为对比学习的中心概念上。结果是有希望的:例如,动量对比(MoCo)表明,无监督预训练可以在多个检测和分割任务中超过其ImageNet监督的对应部分,SimCLR 进一步缩小了无监督和监督预训练表示之间的线性分类器性能差距。
-
原始论文:《Improved Baselines with Momentum Contrastive Learning》
对比学习
- 对于一个从组织成相似/不同对的数据中学习相似/不同表示的框架。可以表述为一个查字典的问题。InfoNCE 是解决此类问题常用的损失函数:
- 这里q是查询表示,k+ 是正(相似)关键样本的表示,{k−} 是负(不相似)关键样本的表示。$\tau$ 是温度超参数。如果查询和密钥是同一图像的数据增强版本,则它们形成正对,否则形成负对。
对比损失可以通过各种不同的密钥维护机制最小化。在端到端机制中,负样本来自同一批数据,并通过反向传播进行端到端更新。SimCLR 就是基于这种机制,需要大 batchsize 才能提供大量底片。在MoCo机制中,负样本被保持在队列中,并且在每个训练批次中只有查询样本和正样本被编码。采用动量编码器来提高当前模型和之前模型之间的表示一致性。
具体可以移步参考 自监督学习 —— MoCo v1
MoCo v2 的改进思路
-
MoCo v2 的亮点是不需要强大的 Google TPU 加持,仅仅使用 8-GPU 就能超越 SimCLR v1的性能。
-
MoCo v2 是在 SimCLR 发表以后相继出来的,它是一篇很短的文章, 只有2页。在MoCo v2 中,作者们整合 SimCLR 中的两个主要提升方法到 MoCo 中,并且验证了SimCLR算法的有效性。
-
在 SimCLR v1 发布以后,MoCo的作者团队就迅速地将 SimCLR的两个提点的方法移植到了 MoCo 上面,想看下性能的变化,也就是MoCo v2。结果显示,MoCo v2的结果取得了进一步的提升并超过了 SimCLR v1,证明MoCo系列方法的地位。因为 MoCo v2 文章只是移植了 SimCLR v1 的技巧而没有大的创新,所以作者就写成了一个只有2页的技术报告。
方法改进
- SimCLR的两个提点的方法就是:
-
使用强大的数据增强策略,具体就是额外使用了 Gaussian Deblur 的策略和使用巨大的 Batch size,让自监督学习模型在训练时的每一步见到足够多的负样本 (negative samples),这样有助于自监督学习模型学到更好的 visual representations。
-
使用预测头 Projection head。在 SimCLR 中,Encoder 得到的2个 visual representation再通过Prediction head ()进一步提特征,预测头是一个 2 层的MLP,将 visual representation 这个 2048 维的向量进一步映射到 128 维隐空间中,得到新的representation 。利用 去求loss 完成训练,训练完毕后扔掉预测头,保留 Encoder 用于获取 visual representation。
- 实验测试了改进后的方法和 MoCo v1 的性能:
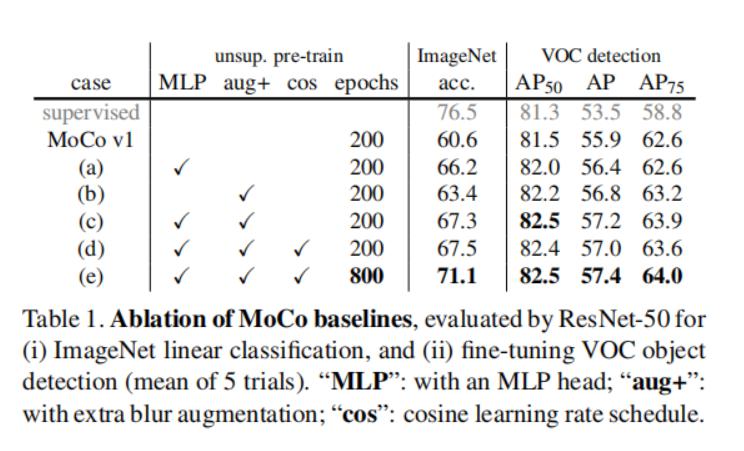
- 也比对了和 SimCLR 方法在对其两个附加条件后的性能:

- 结果表明两个附加 trick 可以有效提示 MoCo v1 的性能,在对其 trick 后 MoCo 还是比 SimCLR 能打的。
原始论文
参考资料
- 《Improved Baselines with Momentum Contrastive Learning》
- https://cloud.tencent.com/developer/article/1867739
- https://zhuanlan.zhihu.com/p/469100381
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/moco/moco-v2/moco-v2/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付