本文最后更新于:2024年5月11日 下午
Contrastive Loss(对比损失)是一种损失函数,通常用于训练对比学习(Contrastive Learning)模型,这些模型旨在学习数据中的相似性和差异性。本文记录相关内容。
简介
Contrastive Loss(对比损失)是一种损失函数,通常用于训练对比学习(Contrastive Learning)模型,这些模型旨在学习数据中的相似性和差异性。对比学习的主要目标是将相似的样本对映射到接近的位置,而将不相似的样本对映射到远离的位置。Contrastive Loss 有助于实现这一目标。
Contrastive Loss 可以认为是ranking loss类型,我们平时ML任务的时候,用的最多的是cross entropy loss或者MSE loss。需要有一个明确的目标,比如一个具体的数值或者是一个具体的分类类别。但是ranking loss实际上是一种metric learning,他们学习的相对距离,相关关系,而对具体数值不是很关心。
对比损失
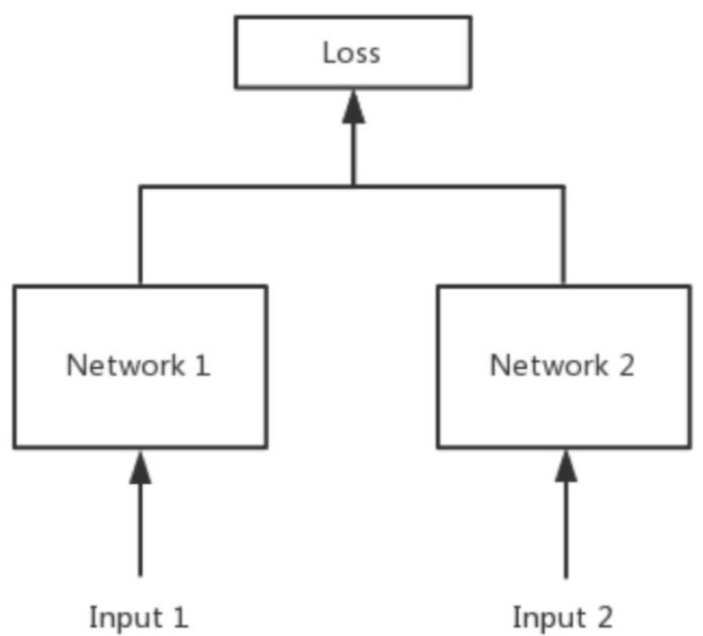
对比损失大多数情况下运用在孪生网络(siamese network)中,这种损失函数可以有效的处理孪生神经网络中的paired data的关系(形式上并不一定是两个Net,也可以是一个Net两个Out,可以认为上面示意图的Network1和2是同一个,或者不是同一个)。contrastive loss的表达式如下:
$$ L=\frac{1}{2N}~\sum_{n=1}^Nyd^2+(1-y)\max(margin-d,0)^2 $$其中 $\mathrm{d=||a_n-b_n||_2}$ 代表两个样本特征的欧氏距离,y为两个样本是否匹配的标签,y=1代表两个样本相似或者匹配,y=0 则代表不匹配,margin为设定的阈值。
这种损失函数最初来源于Yann LeCun 的 Dimensionality Reduction by Learning an Invariant Mapping,主要是用在降维中,即本来相似的样本,在经过降维(特征提取)后,在特征空间中,两个样本仍旧相似;而原本不相似的样本,在经过降维后,在特征空间中,两个样本仍旧不相似。
观察上述的contrastive loss的表达式可以发现,这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。
- 当 $y=1$(即样本相似)时,损失函数只剩下 $∑ y d^ 2 $ ,即原本相似的样本,如果在特征空间的欧式距离较大,则说明当前的模型不好,因此加大损失。
- 当 $y=0$ 时(即样本不相似)时,损失函数为 $∑ ( 1 − y )\max ( m a r g i n − d , 0 ) ^2 $ ,即当样本不相似时,其特征空间的欧式距离反而小的话,损失值会变大,这也正好符号我们的要求。
其中 $margin$ 是一个超参,相当于是给 $loss$ 定了一个上界($margin$ 平方),如果 $d$ 大于等于 $margin$,那么说明已经优化的很好了,$loss=0$。
下图表示的就是损失函数值与样本特征的欧式距离之间的关系,其中红色虚线表示的是相似样本的损失值,蓝色实线表示的不相似样本的损失值。
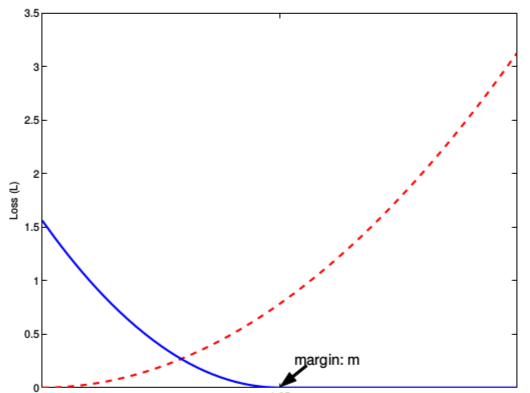
Contrastive Loss 的目标是最小化正样本对的距离或相似度,同时确保负样本对的距离或相似度大于一定的阈值 $margin$。这样,模型就会学习到在嵌入空间中更好地区分相似和不相似的样本。
参考资料
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/loss/contrastive-loss/contrastive-loss/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付