本文最后更新于:2024年5月7日 下午
注意力机制(Attention)是深度学习中常用的tricks,可以在模型原有的基础上直接插入,进一步增强你模型的性能。本文记录常用 Attention 方法与 Pytorch 实现。
概述
注意力机制起初是作为自然语言处理中的工作Attention Is All You Need被大家所熟知,从而也引发了一系列的XX is All You Need的论文命题,SENET-Squeeze-and-Excitation Networks是注意力机制在计算机视觉中应用的早期工作之一,并获得了2017年imagenet, 同时也是最后一届Imagenet比赛的冠军,后面就又出现了各种各样的注意力机制,应用在计算机视觉的任务中。
论文 arxiv 镜像
如果大家遇到论文下载比较慢, 推荐使用中科院的 arxiv 镜像: http://xxx.itp.ac.cn, 国内网络能流畅访问
简单直接的方法是, 把要访问 arxiv 链接中的域名从 https://arxiv.org 换成 http://xxx.itp.ac.cn
比如: 从 https://arxiv.org/abs/1901.07249 改为 http://xxx.itp.ac.cn/abs/1901.07249
注意力
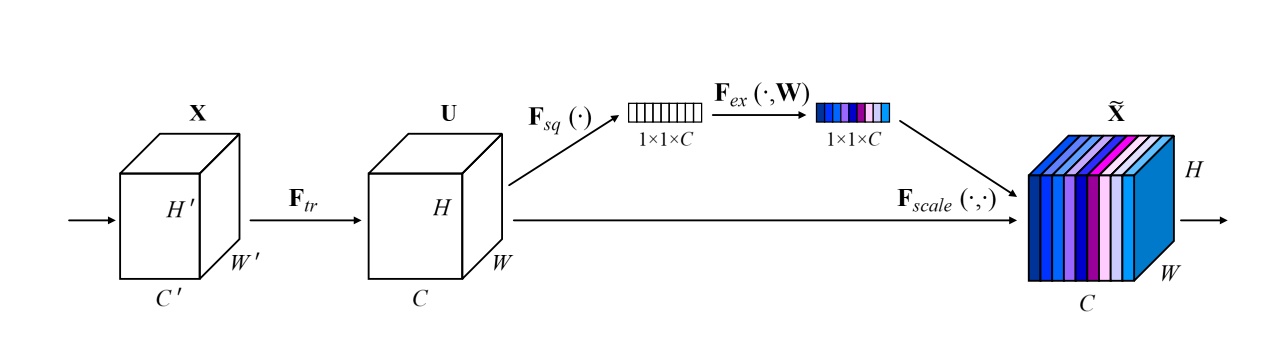
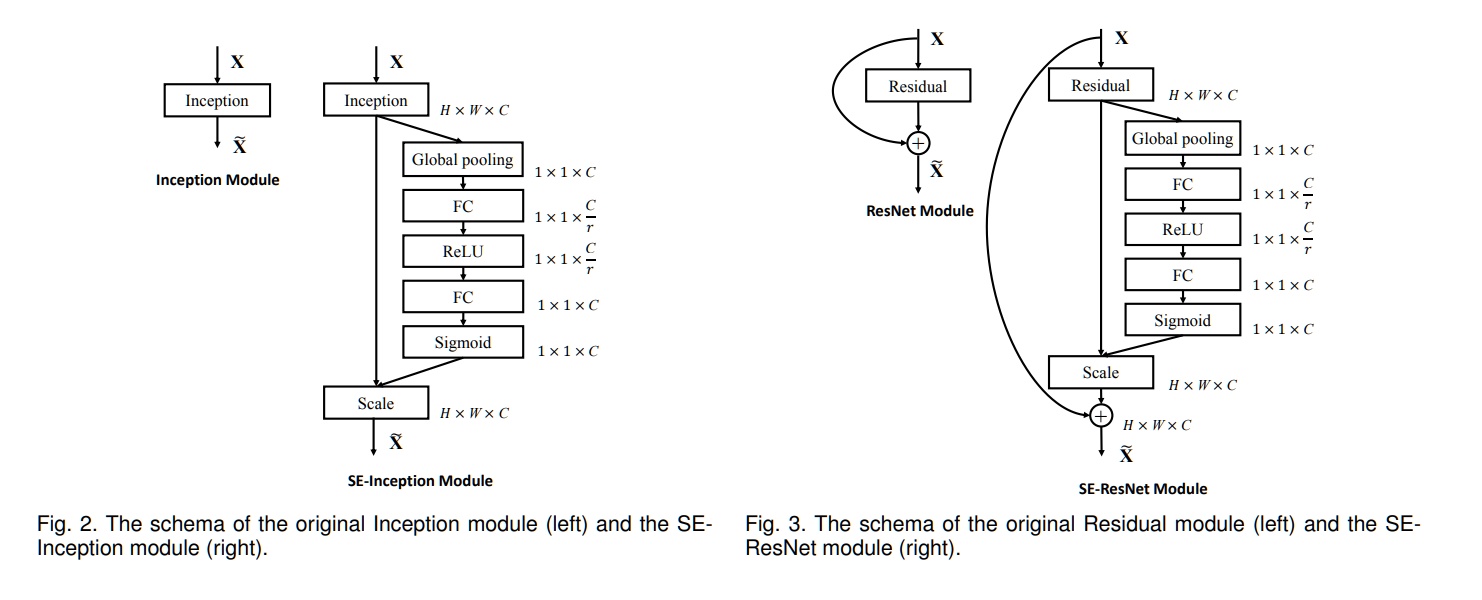
SeNet: Squeeze-and-Excitation Attention
- 论文地址:https://arxiv.org/abs/1709.01507
- 核心思想:对通道做注意力机制,通过全连接层对每个通道进行加权。
- 网络结构:
- Pytorch代码
1 | |
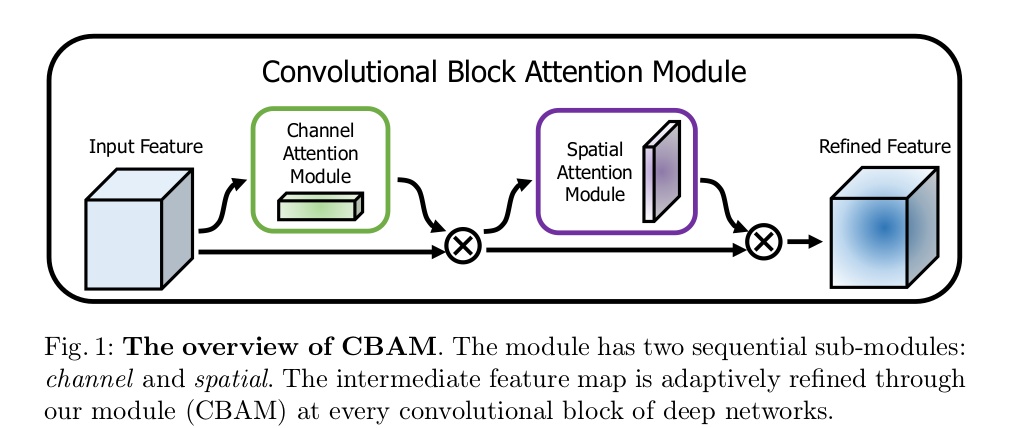
CBAM: Convolutional Block Attention Module
- 论文地址:CBAM: Convolutional Block Attention Module
- 核心思想:对通道方向上做注意力机制之后再对空间方向上做注意力机制
- 网络结构
- Pytorch代码
1 | |
BAM: Bottleneck Attention Module
- 论文地址:https://arxiv.org/pdf/1807.06514.pdf
- 网络结构:

- Pytorch代码
1 | |
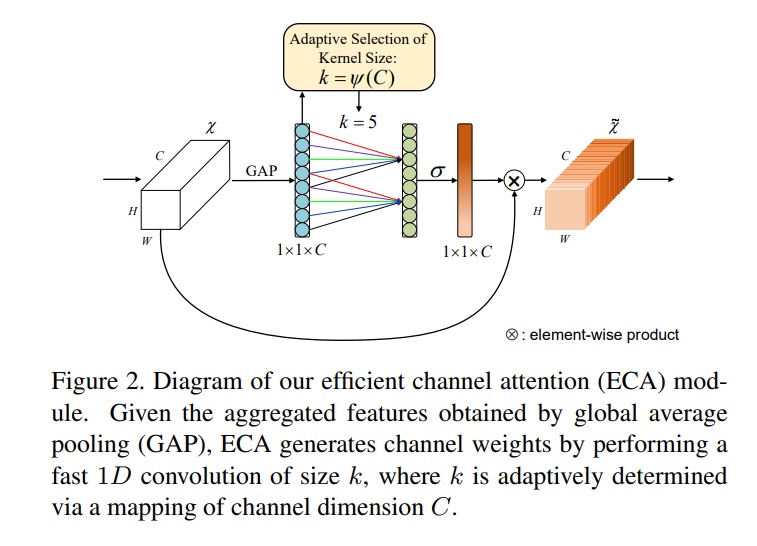
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
- 论文地址:https://arxiv.org/pdf/1910.03151.pdf
- 网络结构:
- Pytorch代码
1 | |
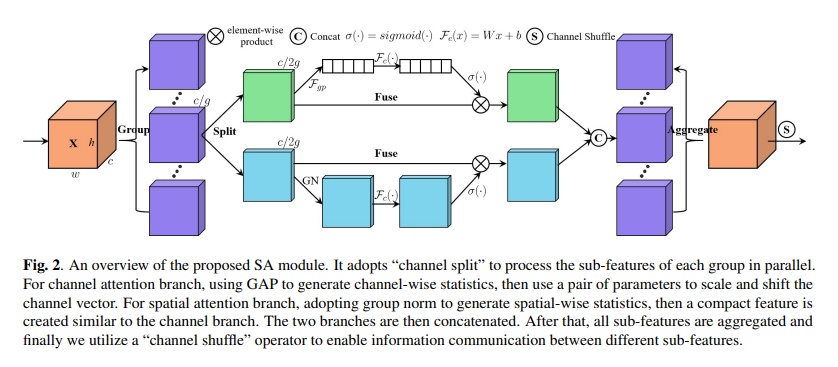
SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS
- 论文地址:https://arxiv.org/pdf/2102.00240.pdf
- 网络结构:
- Pytorch代码
1 | |
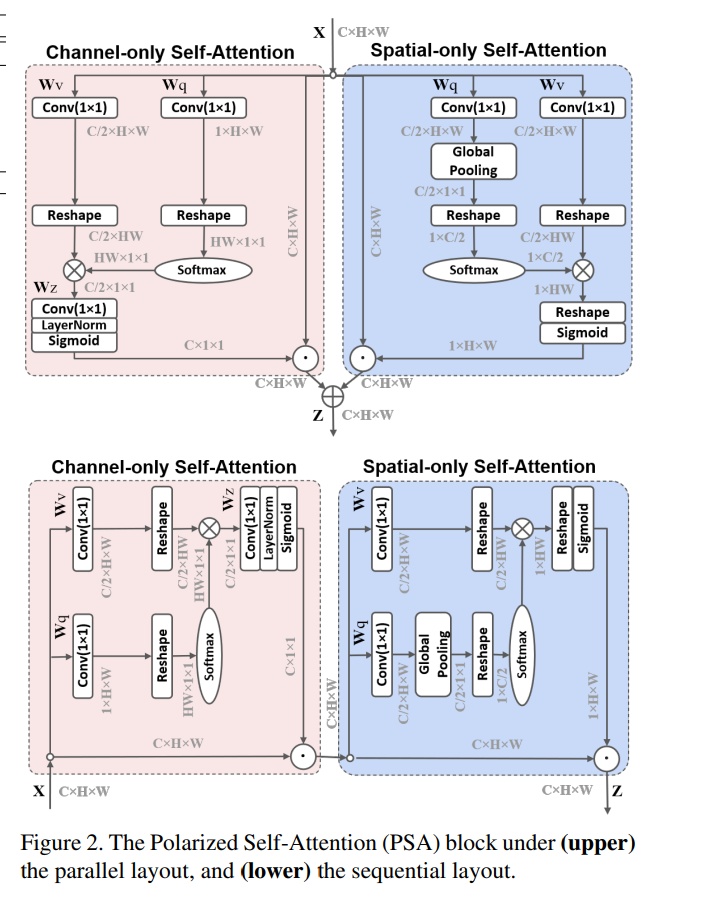
Polarized Self-Attention: Towards High-quality Pixel-wise Regression
- 论文地址:https://arxiv.org/abs/2107.00782
- 网络结构:
- Pytorch代码
1 | |
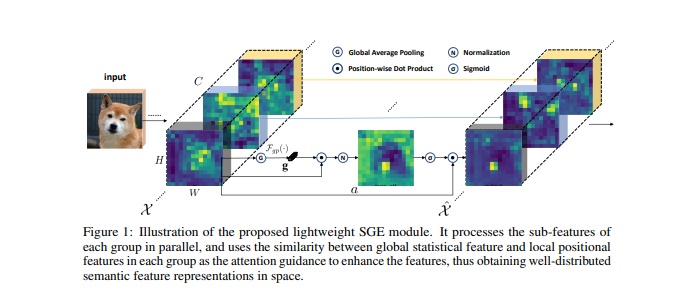
Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks
- 论文地址:https://arxiv.org/pdf/1905.09646.pdf
- 网络结构:
- Pytorch代码
1 | |
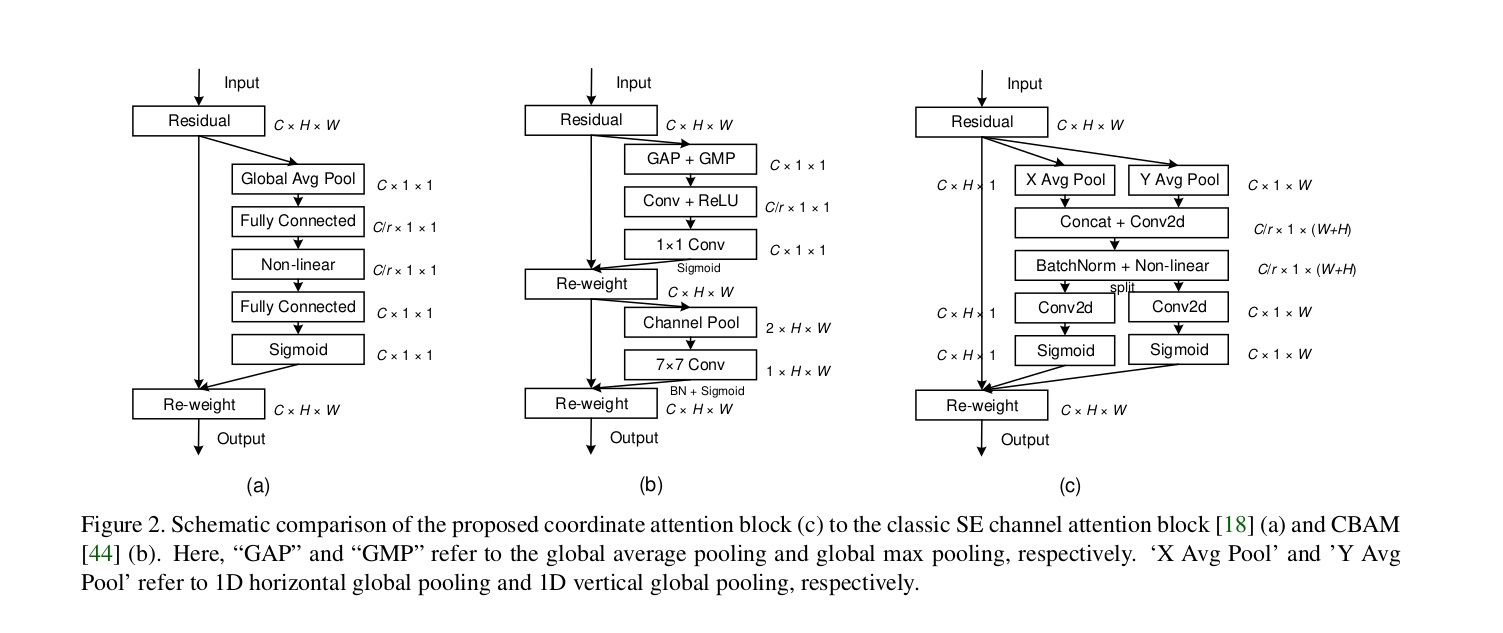
Coordinate Attention for Efficient Mobile Network Design
主要应用在轻量级网络上,在resnet系列上效果不好。
- 论文地址:https://arxiv.org/abs/2103.02907
- 网络结构
- Pytorch代码
1 | |
Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
计算量特别大,效果一般
- 论文地址: https://arxiv.org/abs/2112.05561
- Pytorch 代码
1 | |
更多注意力
双路注意力机制-DANET
-
论文标题:Fu_Dual_Attention_Network_for_Scene_Segmentation
-
时间:2019
-
网络结构
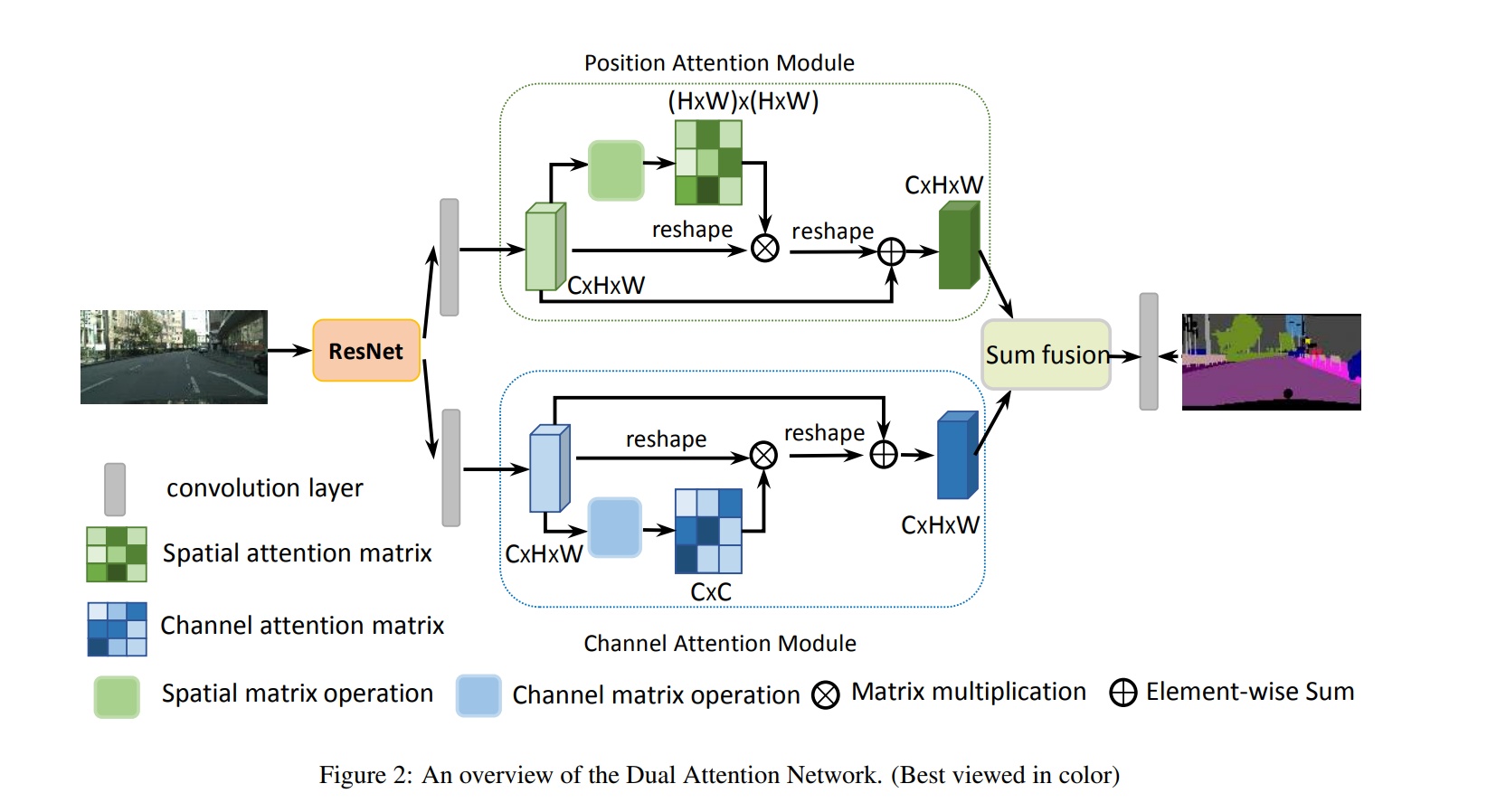
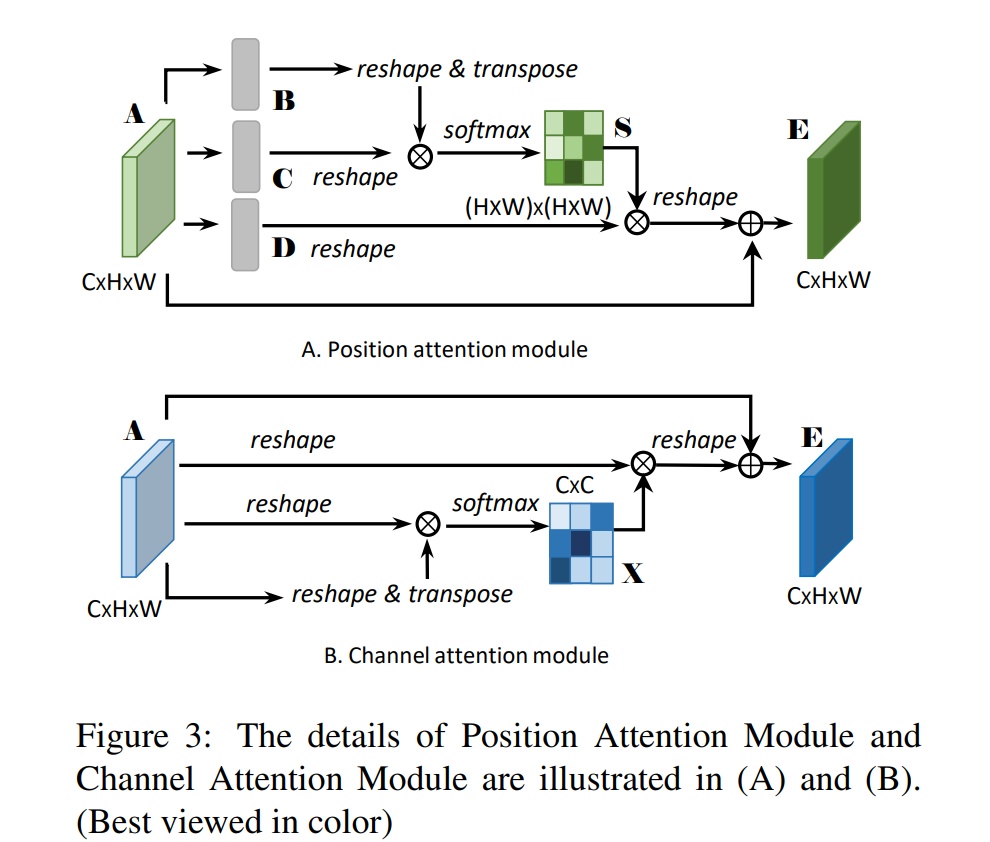
位置注意力-CCNET
在上面的danet上改的,主要是解决计算量的问题, 通过十字交叉的结构来解决
-
论文标题:CCNet: Criss-Cross Attention for Semantic Segmentation
-
时间:2019
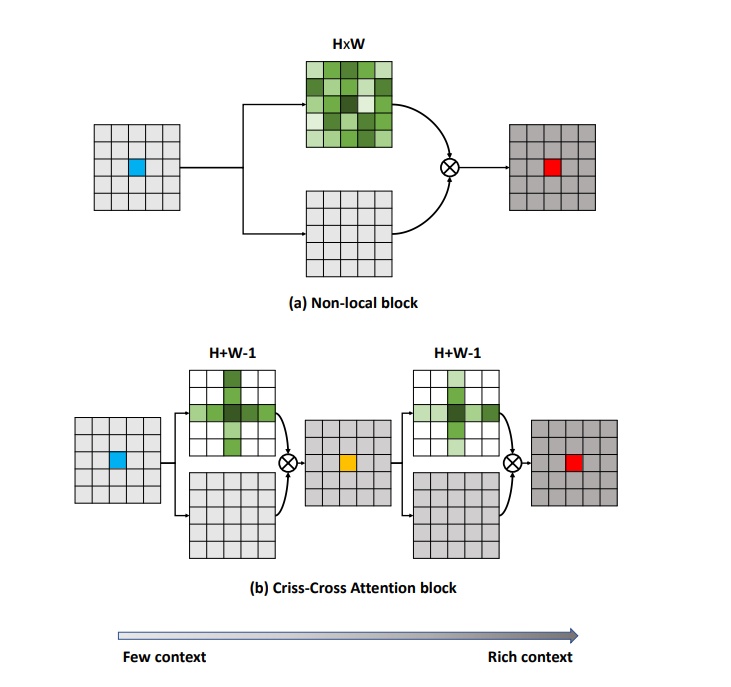
参考资料
- https://blog.csdn.net/ECHOSON/article/details/121993573
- https://github.com/xmu-xiaoma666/External-Attention-pytorch
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/attention/visual-attention/visual-attention/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付