本文最后更新于:2024年5月7日 下午
本文介绍了数据科学家必备的五种检测异常值的方法。
简介
在统计学中,异常值是指不属于某一特定群体的数据点。它是一个与其他数值大不相同的异常观测值,与良好构成的数据组相背离。
例如,你可以清楚地看到这个列表里的异常值:[20, 24, 22, 19, 29, 18, 4300, 30, 18].
当观测值仅仅是一堆数字并且是一维时,很容易识别出异常值。但是,当你有成千上万的观测值或者是多维度时,你将需要更多巧妙的办法来检测出那些异常值。这就是本文要讨论的内容。
下面介绍 5 种常用的检测异常值的方法。
标准差
在统计学中,如果一个数据分布式近似正态分布,那么大约68%的数据值在平均值的前后一个标准差范围内,大约95%的数据值在平均值的前后两个标准差范围内,大约99.7%的数据值在前后三个标准差的范围内。
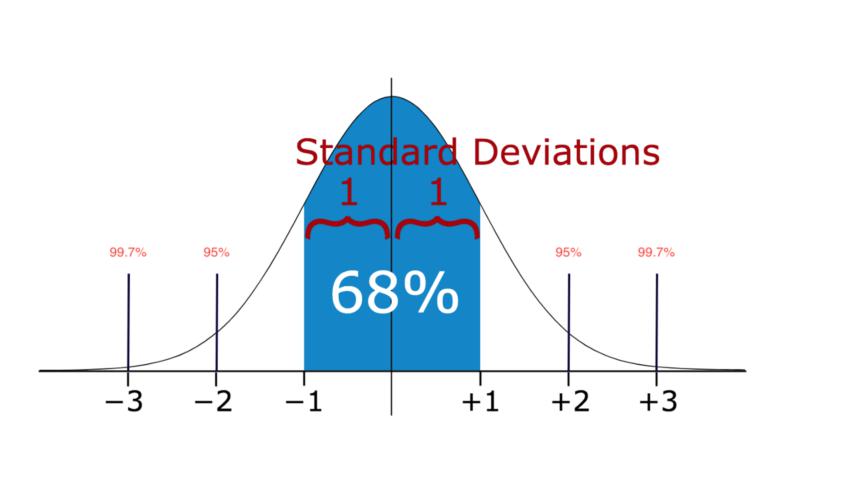
因此,如果你有任何出现在三个标准差范围外的数据点,那么那些点就极有可能是异常值。
箱线图
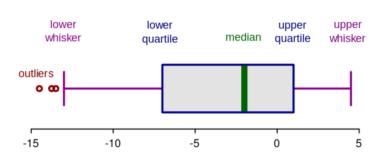
箱线图是指通过分位数对数值型数据的图形化描述。这是一种非常简单但有效的异常值可视化方法。把上下须触线看作数据分布的上下边界。任何出现在下须触线下面或上须触线上面的数据点可以被看作异常值。
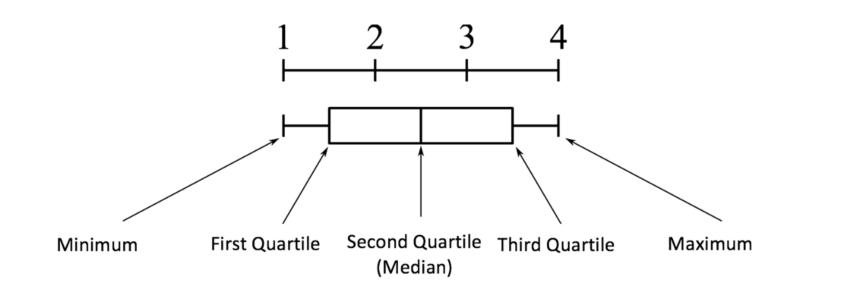
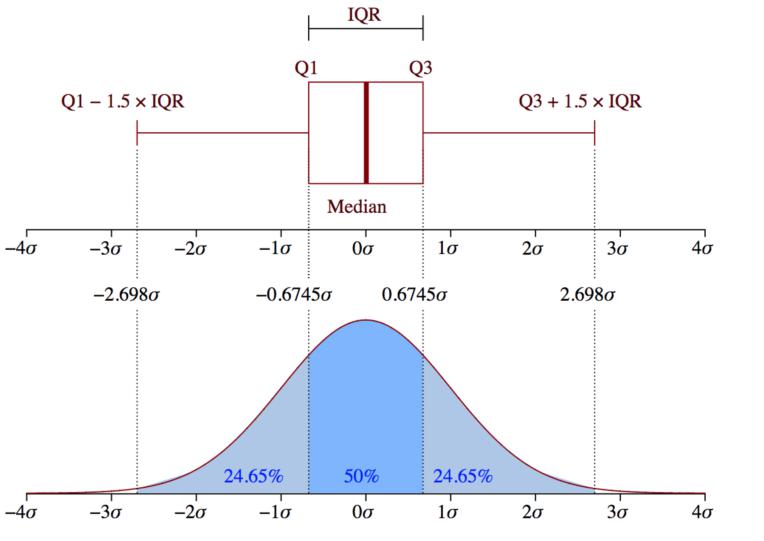
四分位差是重要的,因为它用于定义异常值。它是第三个四分位数和第一个四分位数的差(IQR=Q3-Q1). 这种情况下的异常值被定义为低于(Q1-1.5IQR)或低于箱线图下须触线或高于(Q3+1.5IQR)或高于箱线图上须触线的观测值。
如果数据服从高斯分布,那么可以类比标准差的异常检测结果:
DBScan聚类
DBScan是一种用于将数据分组的集群算法。它也也可以用于基于密度的对于一维或多维数据的异常检测方法。
- 核心点:为了理解核心点,我们需要访问一些用于定义DBScan工作的超参数。第一个超参数是最小值样本(min_samples)。这只是形成集聚的核心点的最小数量。第二重要的超参数eps,它是两个被视为在同一个簇中的样本之间的最大距离。
- 边界点:是与核心点在同一集群的点,但是要离集群中心远得多。
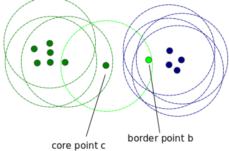
可以用数据建立合理区域的区间,每个数据会产生一个合理范围,这个范围可以叠加,如果测试数据落在大量数据的合理区间内,那么我们基本上可以认为数据正常,如果测试数据落在所有数据或少量数据合理范围内,那么他在一定程度上可以被认为是异常的。
孤立森林
孤立森林是一种无监督学习的算法,属于集成决策树族。这种方法与前面的方法都不同。所有前面的方法是试图找到数据的正常区域,然后将所定义区域外的任何值视为异常值。
这种方法的工作原理不同。它是明确的孤立异常值,而不是通过给每个点分配一个分数来构造正常的点和区域。它充分利用了这样一个事实:异常值只占数据的小部分,并且它们有与正常值大不相同的属性。该算法适用于高维数据集,并且被证实是一种非常有效的检测异常值的方法。
- 原始论文
Robust Random Cut Forest
Robust Random Cut Forest算法是亚马逊用于检测异常值的无监督算法。它也通过关联异常分数来工作。低的分数值表示数据点是“正常的”,高的值表示数据中存在异常。“低”和“高”的定义取决于应用,但是一般实践表明,超过平均值三个标准差的分数被认为是异常的。算法的细节可以在这篇文章中找到。
这个算法的最大优势是它可以处理非常高维的数据。它还可以处理实时数据流(内置AWS Kinesis Analytics)和离线数据。
该算法的论文给出了一些与孤立森林相比较的性能标准。论文结果表明,RCF比孤立森林更加准确和快速。
参考资料
- 每个数据科学家应该知道的五种检测异常值的方法
- https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf
- http://proceedings.mlr.press/v48/guha16.pdf
文章链接:
https://www.zywvvd.com/notes/study/data_analysis/abnormal-data-det/abnormal-data-det/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付