本文最后更新于:2025年4月30日 下午
中科院自动化所模式识别国重实验室的申抒含老师和崔海楠老师的关于基于凸显的大规模场景三维重建的讲习班中分享了很棒的课件资料,本文记录相关内容。
目录
- 简介
- 稀疏重建sfm
- 稠密重建mvs
- 资源
简介
图像三维重建基本流程
- 三维重建流程包括:
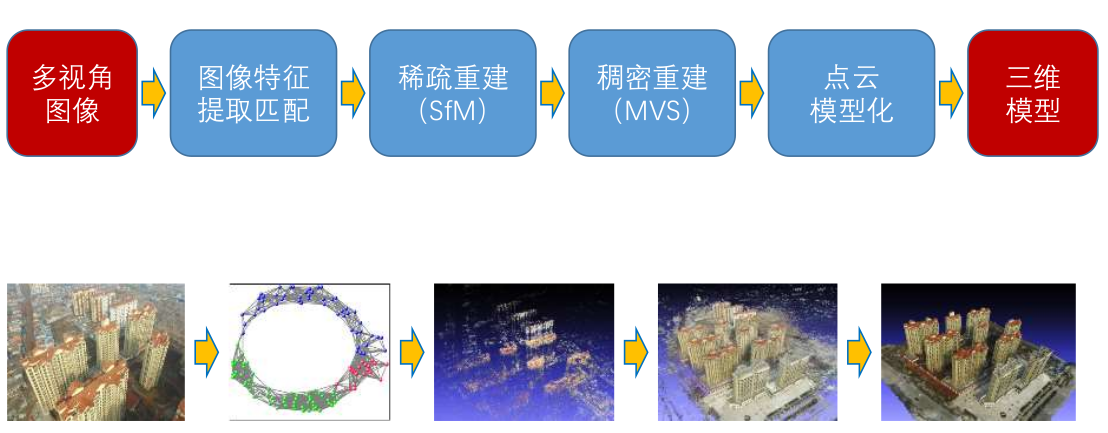
- 多视角图像
- 图像特征提取匹配
- 稀疏重建Sfm
- 稠密重建MVS
- 点云模型化
- 生成三维模型
- 科普小孔成像与齐次、非齐次坐标系相关内容
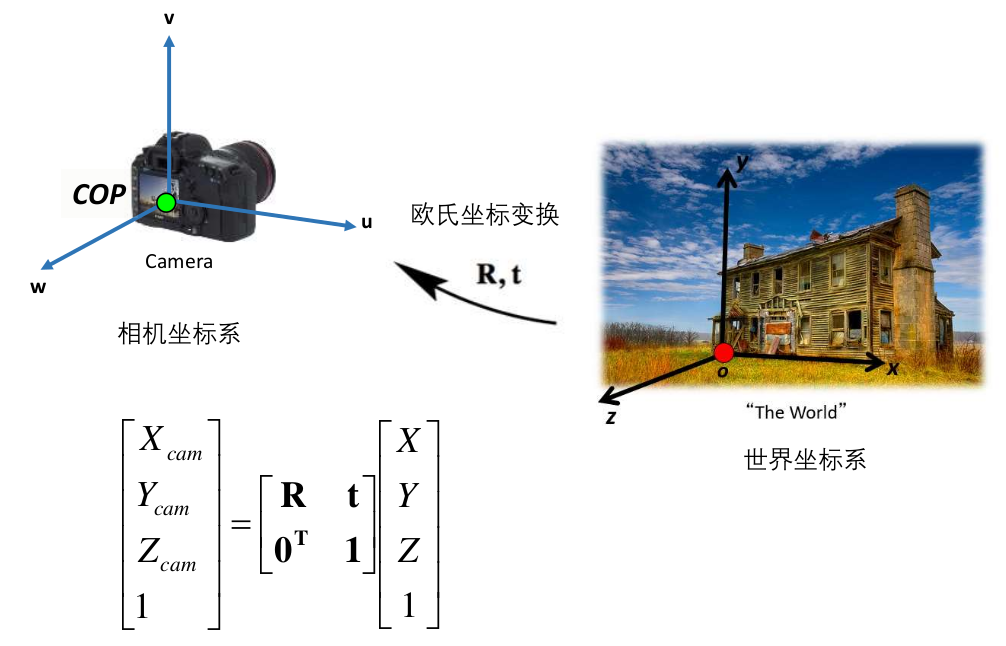
多视几何
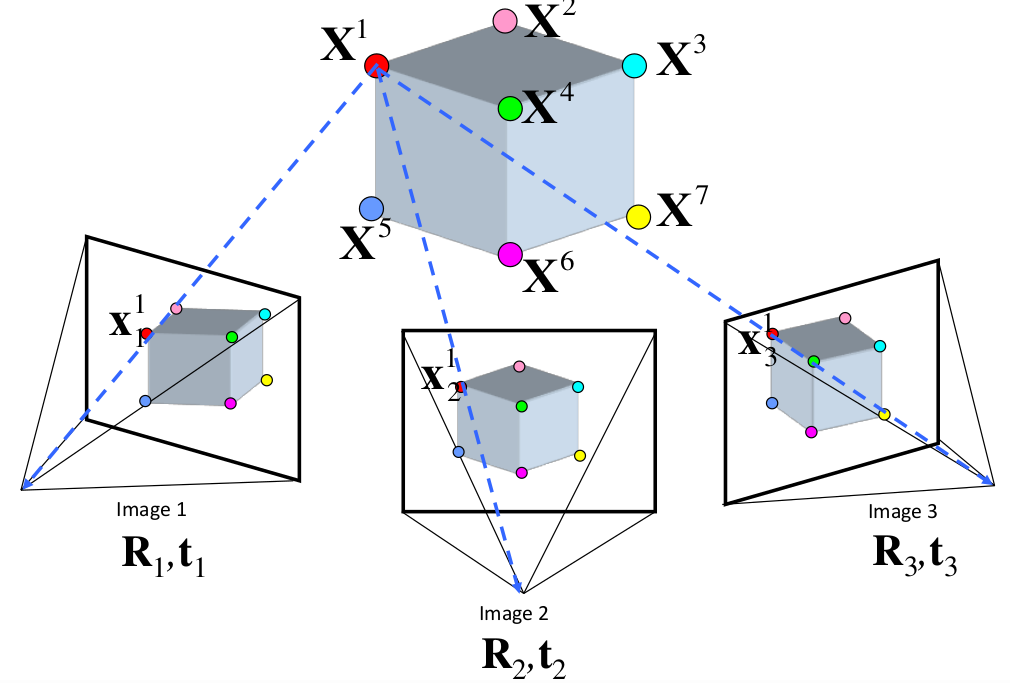
求解思路为最小化重投影误差平方和

接着推导就可以写成 $𝐹(\hat{𝑋})−𝑏$ 的形式。

这样求解重投影误差最小化问题是一个高维非线性最小二乘问题。未知数数量由图像数量乘以旋转矩阵、平移向量、内参数、畸变加上稀疏点数目乘以世界坐标X。
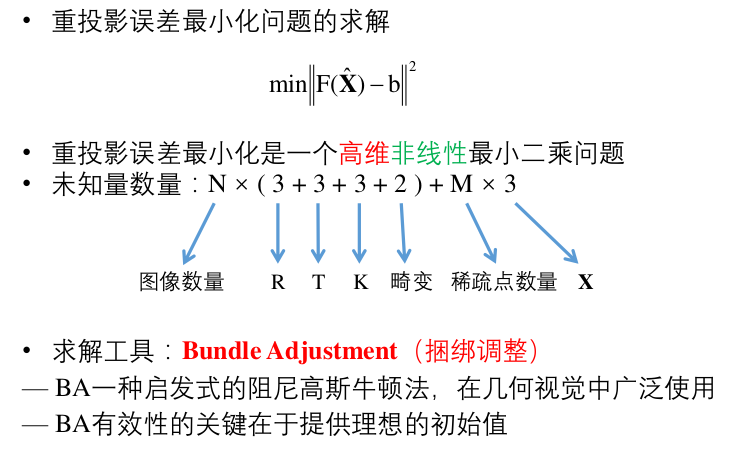
- 介绍视图重建的初始值求解方法

稀疏重建
- 通过相机运动恢复场景的结构(SfM, Structure-from-Motion):
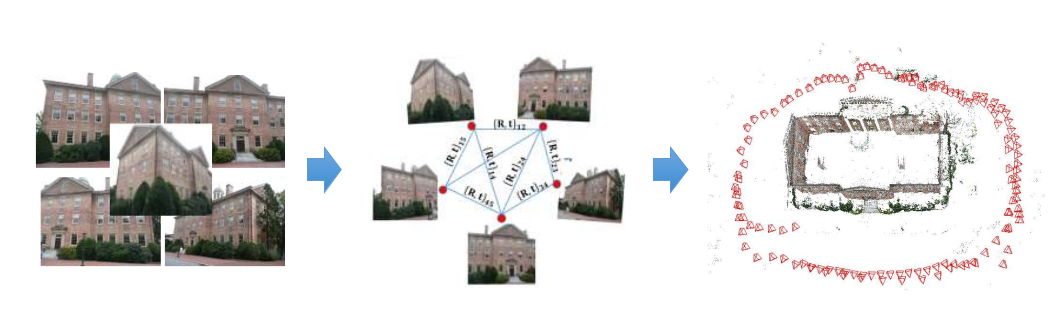
- SfM 包括以下步骤:
- 特征点检测与匹配
- 外极几何图构造
- 摄像机位姿和场景结构估计
- 捆绑调整(BA)优化摄像机位姿和场景
-
特征提取采用 SIFT 特征
-
特征点匹配:
-
L2范数距离最小
-
比值约束:最近邻/次近邻小于一定阈值
-
外极几何约束(匹配特征点在对应的外极线附近)
-
-
匹配难点
候选图像匹配对非常多。这里介绍了一篇解决这个问题的论文。
通过聚类、建树、匹配。(K-means层级树)
可以把复杂度降到线性。
误匹配问题(用Loop约束来去除错误外极几何关系)。
-
本质矩阵分解:三角化选择内点最多的一组配置作为外极几何关系。
-
外极几何图构建
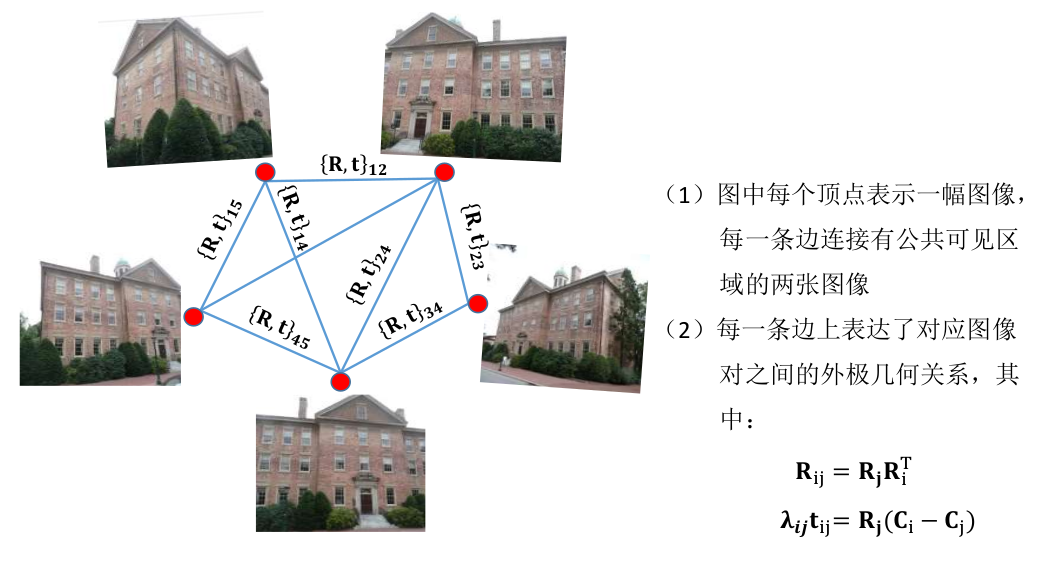
-
摄像机位姿和场景结构估计
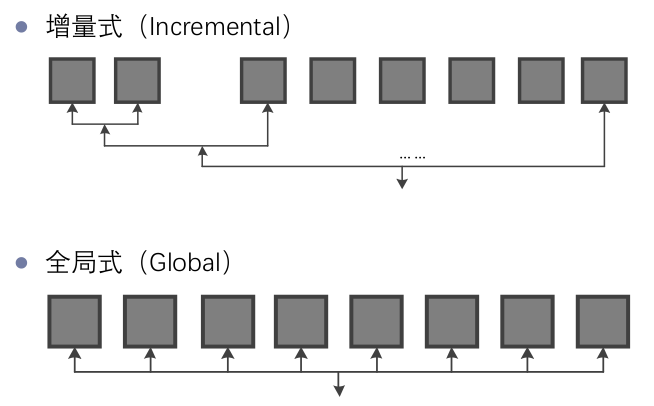
包括三种方法:
- 增量式(Incremental)
- 全局式(Global)
- 混合式(Hybrid)
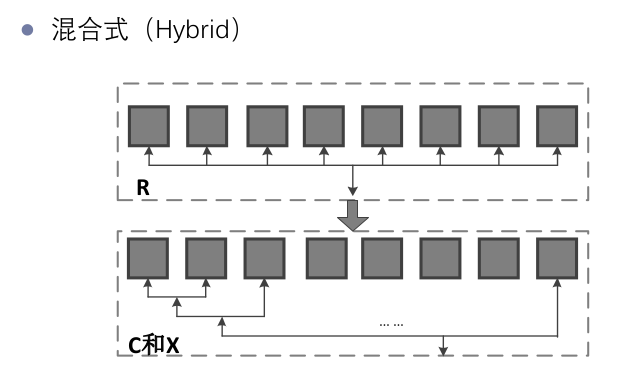
增量式的优缺点:

全局式的优缺点:

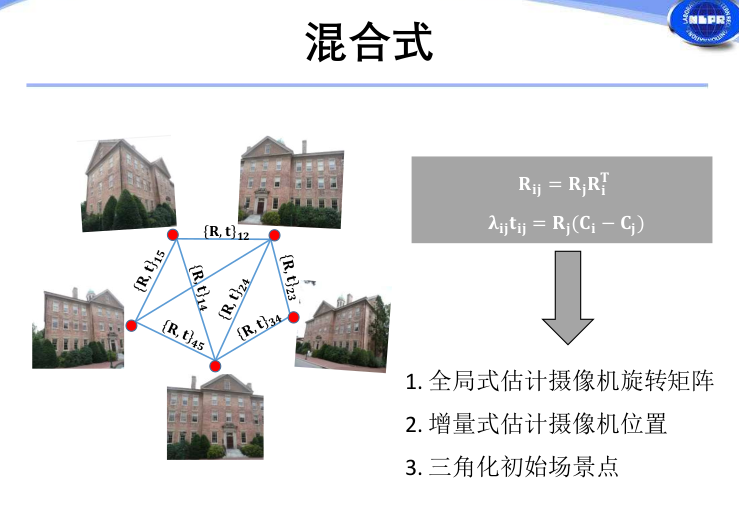
混合式的优缺点:
三者定性对比:
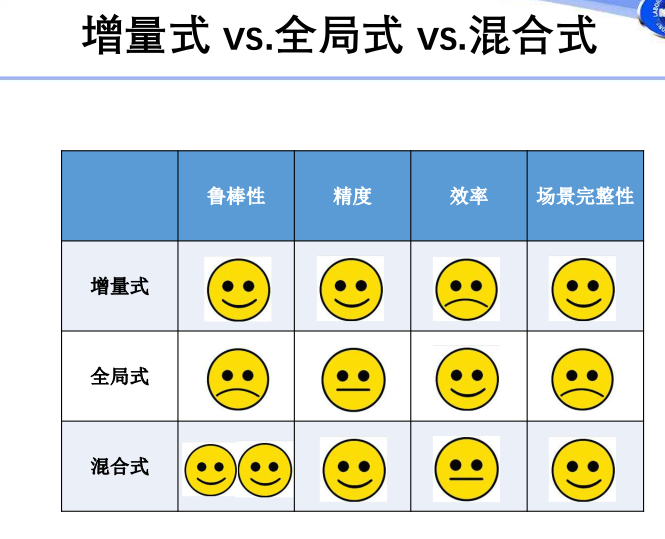
- 总结
稀疏重建通过摄像机运动恢复场景结构,当前主流方法主要区分在于摄像机初始位姿计算的模式。- 增量式鲁棒,场景结构准确,但效率不足;
- 全局式仅一次捆绑调整,效率高,但鲁棒性不足,易受到匹配外点的影响;
- 混合式继承了增量和全局两种模式的优点:不仅提高了旋转矩阵的求取精度,而且在保持鲁棒性的前提下,提高了增量式重建的效率。
原始课件
参考资料
文章链接:
https://www.zywvvd.com/notes/3d/reconstruction/reconstruction-3d/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付
基于图像的大规模场景三维重建
https://www.zywvvd.com/notes/3d/reconstruction/reconstruction-3d/