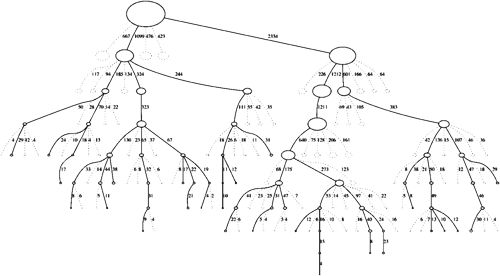
classTreeNode(object): """A node in the MCTS tree. Each node keeps track of its own value Q, prior probability P, and its visit-count-adjusted prior score u. """
def__init__(self, parent, prior_p): self._parent = parent self._children = {} # a map from action to TreeNode self._n_visits = 0 self._Q = 0 self._u = 0 self._P = prior_p
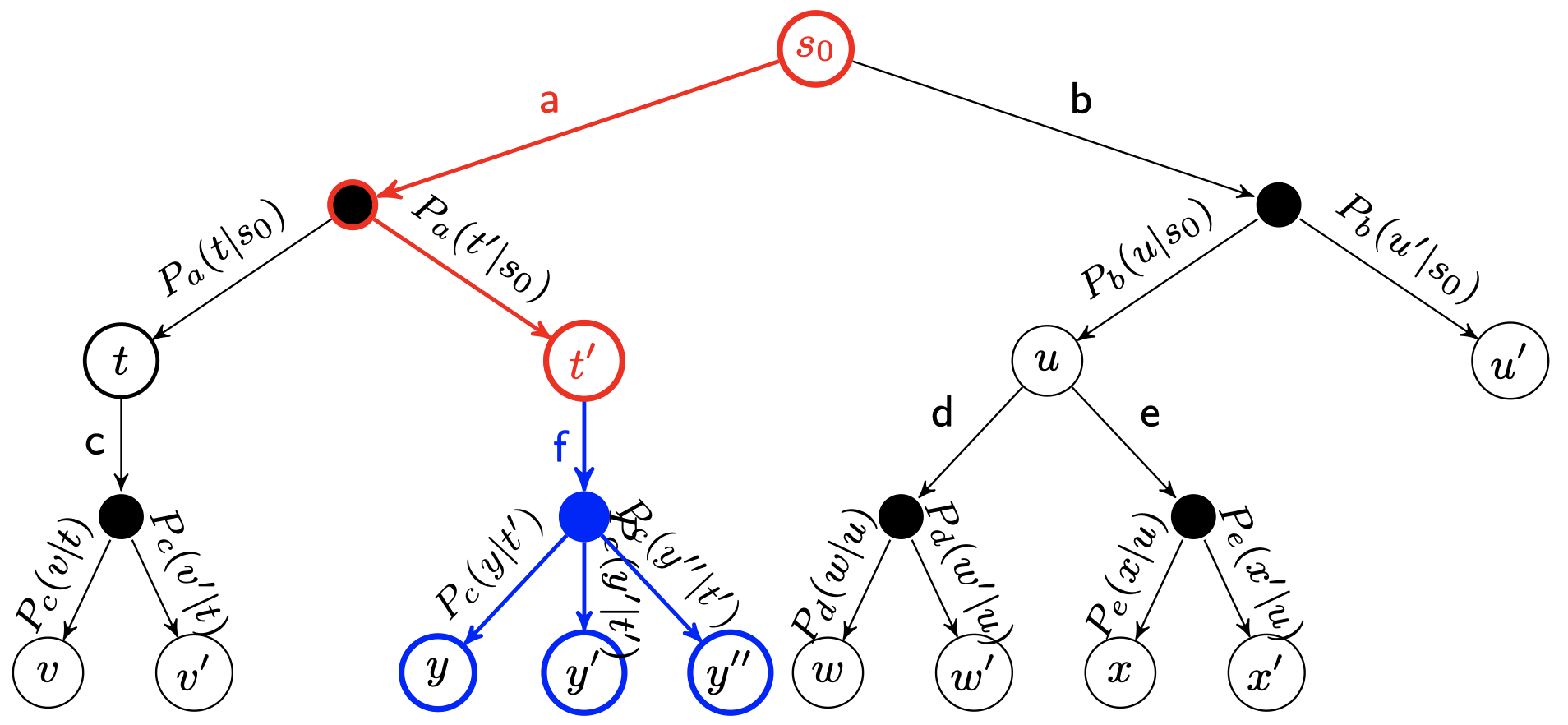
defexpand(self, action_priors): """Expand tree by creating new children. action_priors -- output from policy function - a list of tuples of actions and their prior probability according to the policy function. """ for action, prob in action_priors: if action notin self._children: self._children[action] = TreeNode(self, prob)
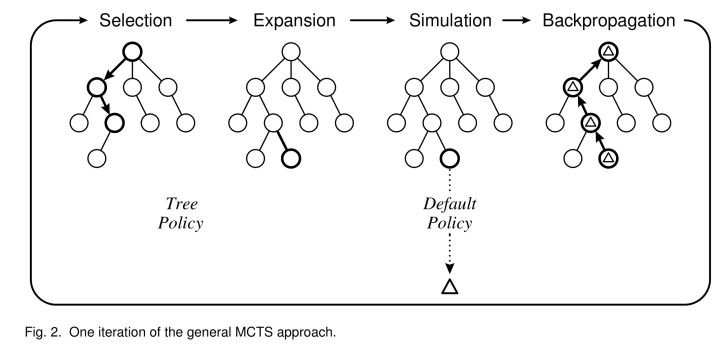
def_playout(self, state): node = self._root whileTrue: if node.is_leaf(): break # Greedily select next move. action, node = node.select(self._c_puct) state.do_move(action)
# Evaluate the leaf using a network which outputs a list of (action, probability) # tuples p and also a score v in [-1, 1] for the current player. action_probs, leaf_value = self._policy(state)
# Check for end of game. end, winner = state.game_end() ifnot end: node.expand(action_probs) else: # for end state,return the "true" leaf_value if winner == -1: # tie leaf_value = 0.0 else: leaf_value = 1.0if winner == state.get_current_player() else -1.0
# Update value and visit count of nodes in this traversal. node.update_recursive(-leaf_value)
defget_move_probs(self, state, temp=1e-3): for n inrange(self._n_playout): state_copy = copy.deepcopy(state) self._playout(state_copy)
act_visits = [(act, node._n_visits) for act, node in self._root._children.items()] acts, visits = zip(*act_visits) act_probs = softmax(1.0/temp * np.log(visits))
return acts, act_probs
defupdate_with_move(self, last_move): if last_move in self._root._children: self._root = self._root._children[last_move] self._root._parent = None else: self._root = TreeNode(None, 1.0)
defupdate(self, leaf_value): # Count visit. self._n_visits += 1 # Update Q, a running average of values for all visits. self._Q += 1.0*(leaf_value - self._Q) / self._n_visits
defupdate_recursive(self, leaf_value): # If it is not root, this node's parent should be updated first.
if self._parent: self._parent.update_recursive(-leaf_value) self.update(leaf_value)
defget_action(self, board, temp=1e-3, return_prob=0): sensible_moves = board.availables move_probs = np.zeros(board.width * board.height) # the pi vector returned by MCTS as in the alphaGo Zero paper iflen(sensible_moves) > 0: acts, probs = self.mcts.get_move_probs(board, temp) move_probs[list(acts)] = probs if self._is_selfplay: # add Dirichlet Noise for exploration (needed for self-play training) move = np.random.choice(acts, p=0.75 * probs + 0.25 * np.random.dirichlet(0.3 * np.ones(len(probs)))) self.mcts.update_with_move(move) # update the root node and reuse the search tree else: # with the default temp=1e-3, this is almost equivalent to choosing the move with the highest prob move = np.random.choice(acts, p=probs) # reset the root node self.mcts.update_with_move(-1)
if return_prob: return move, move_probs else: return move else: print("WARNING: the board is full")
classTreeNode(object): """A node in the MCTS tree. Each node keeps track of its own value Q, prior probability P, and its visit-count-adjusted prior score u. """
def__init__(self, parent, prior_p): self._parent = parent self._children = {} # a map from action to TreeNode self._n_visits = 0 self._Q = 0 self._u = 0 self._P = prior_p
defexpand(self, action_priors): """Expand tree by creating new children. action_priors -- output from policy function - a list of tuples of actions and their prior probability according to the policy function. """ for action, prob in action_priors: if action notin self._children: self._children[action] = TreeNode(self, prob)
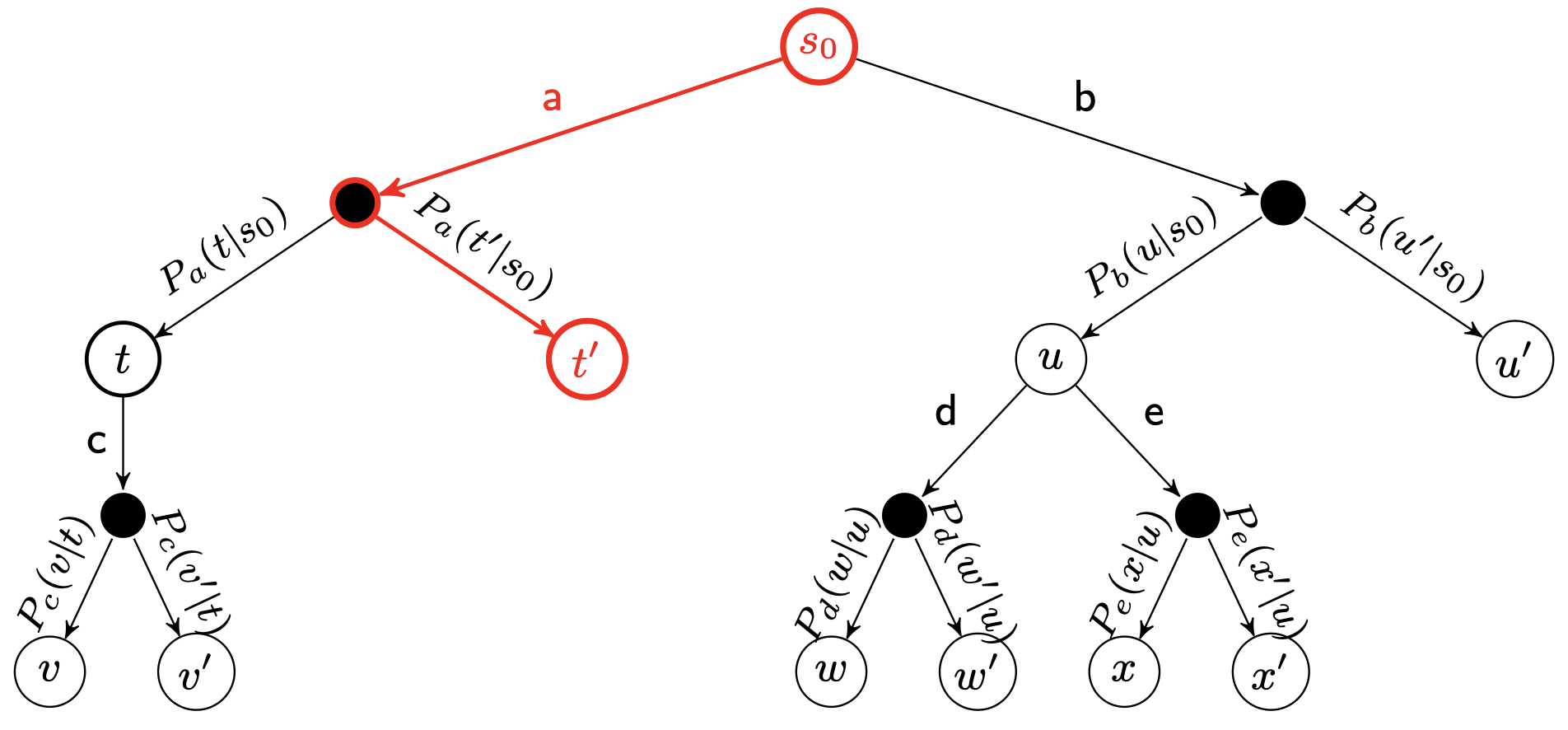
defselect(self, c_puct): """Select action among children that gives maximum action value, Q plus bonus u(P). Returns: A tuple of (action, next_node) """ returnmax(self._children.items(), key=lambda act_node: act_node[1].get_value(c_puct))
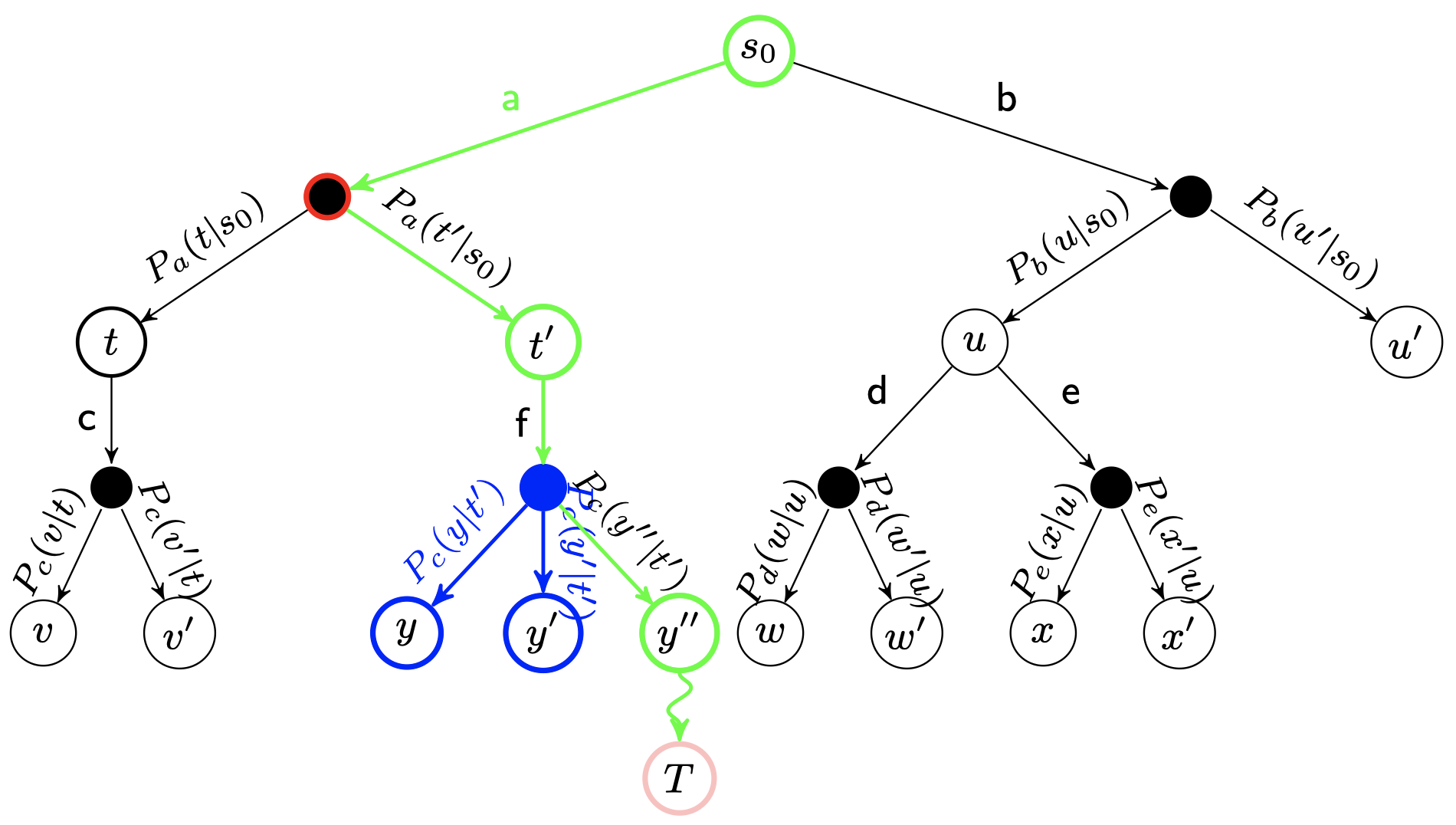
defupdate(self, leaf_value): """Update node values from leaf evaluation. """ # Count visit. self._n_visits += 1 # Update Q, a running average of values for all visits. self._Q += 1.0 * (leaf_value - self._Q) / self._n_visits
defupdate_recursive(self, leaf_value): """Like a call to update(), but applied recursively for all ancestors. """ # If it is not root, this node's parent should be updated first.
if self._parent: self._parent.update_recursive(-leaf_value) self.update(leaf_value)
defget_value(self, c_puct): """Calculate and return the value for this node: a combination of leaf evaluations, Q, and this node's prior adjusted for its visit count, u c_puct -- a number in (0, inf) controlling the relative impact of values, Q, and prior probability, P, on this node's score. """ self._u = c_puct * self._P * np.sqrt(self._parent._n_visits) / (1 + self._n_visits) return self._Q + self._u
defis_leaf(self): """Check if leaf node (i.e. no nodes below this have been expanded). """ return self._children == {}
defis_root(self): return self._parent isNone
classMCTS(object): """A simple implementation of Monte Carlo Tree Search. """
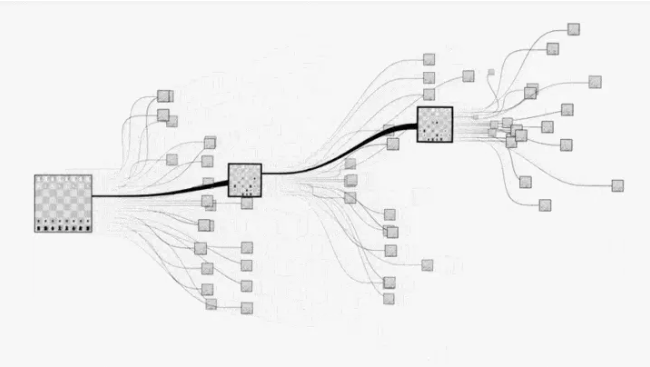
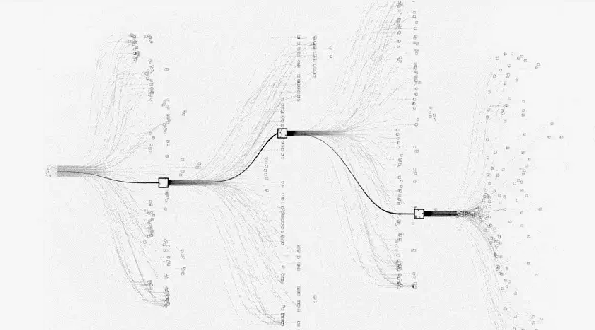
def__init__(self, policy_value_fn, c_puct=5, n_playout=10000): """Arguments: policy_value_fn -- a function that takes in a board state and outputs a list of (action, probability) tuples and also a score in [-1, 1] (i.e. the expected value of the end game score from the current player's perspective) for the current player. c_puct -- a number in (0, inf) that controls how quickly exploration converges to the maximum-value policy, where a higher value means relying on the prior more """ self._root = TreeNode(None, 1.0) self._policy = policy_value_fn self._c_puct = c_puct self._n_playout = n_playout
def_playout(self, state): """Run a single playout from the root to the leaf, getting a value at the leaf and propagating it back through its parents. State is modified in-place, so a copy must be provided. Arguments: state -- a copy of the state. """ node = self._root whileTrue: if node.is_leaf(): break # Greedily select next move. action, node = node.select(self._c_puct) state.do_move(action)
# Evaluate the leaf using a network which outputs a list of (action, probability) # tuples p and also a score v in [-1, 1] for the current player. action_probs, leaf_value = self._policy(state)
# Check for end of game. end, winner = state.game_end() ifnot end: node.expand(action_probs) else: # for end state,return the "true" leaf_value if winner == -1: # tie leaf_value = 0.0 else: leaf_value = 1.0if winner == state.get_current_player() else -1.0
# Update value and visit count of nodes in this traversal. node.update_recursive(-leaf_value)
defget_move_probs(self, state, temp=1e-3): """Runs all playouts sequentially and returns the available actions and their corresponding probabilities Arguments: state -- the current state, including both game state and the current player. temp -- temperature parameter in (0, 1] that controls the level of exploration Returns: the available actions and the corresponding probabilities """ for n inrange(self._n_playout): state_copy = copy.deepcopy(state) self._playout(state_copy)
# calc the move probabilities based on the visit counts at the root node act_visits = [(act, node._n_visits) for act, node in self._root._children.items()] acts, visits = zip(*act_visits) act_probs = softmax(1.0 / temp * np.log(visits))
return acts, act_probs
defupdate_with_move(self, last_move): """Step forward in the tree, keeping everything we already know about the subtree. """ if last_move in self._root._children: self._root = self._root._children[last_move] self._root._parent = None else: self._root = TreeNode(None, 1.0)
def__str__(self): return"MCTS"
classMCTSPlayer(object): """AI player based on MCTS"""
defget_action(self, board, temp=1e-3, return_prob=0): sensible_moves = board.availables # the pi vector returned by MCTS as in the alphaGo Zero paper move_probs = np.zeros(board.width * board.height) iflen(sensible_moves) > 0: acts, probs = self.mcts.get_move_probs(board, temp) move_probs[list(acts)] = probs if self._is_selfplay: # add Dirichlet Noise for exploration (needed for # self-play training) move = np.random.choice( acts, p=0.75 * probs + 0.25 * np.random.dirichlet(0.3 * np.ones(len(probs))) ) # update the root node and reuse the search tree self.mcts.update_with_move(move) else: # with the default temp=1e-3, it is almost equivalent # to choosing the move with the highest prob move = np.random.choice(acts, p=probs) # reset the root node self.mcts.update_with_move(-1) # location = board.move_to_location(move) # print("AI move: %d,%d\n" % (location[0], location[1]))
if return_prob: return move, move_probs else: return move else: print("WARNING: the board is full")