本文最后更新于:2024年5月11日 下午
模型在训练的时候,为了探明模型到底学到了什么特征,是否是我们期望的,或者模型是否学到了“作弊”的信息,这就需要对模型进行可视化,CAM是一种对模型特征可视化的技术。
CAM 可视化
对一个深层的卷积神经网络而言,通过多次卷积和池化以后,它的最后一层卷积层包含了最丰富的空间和语义信息,其中所包含的信息都是人类难以理解的,CAM可以将特征转化为可解释的信息,通过热力图的形式展示模型对数据的理解方式。
原始论文:《Learning Deep Features for Discriminative Localization》
CAM
- 考虑一个含有 GAP 层的分类网络,在 GAP 之前的特征尺寸 $W\times H\times C$,假设为 $7 \times 7 \times 512$
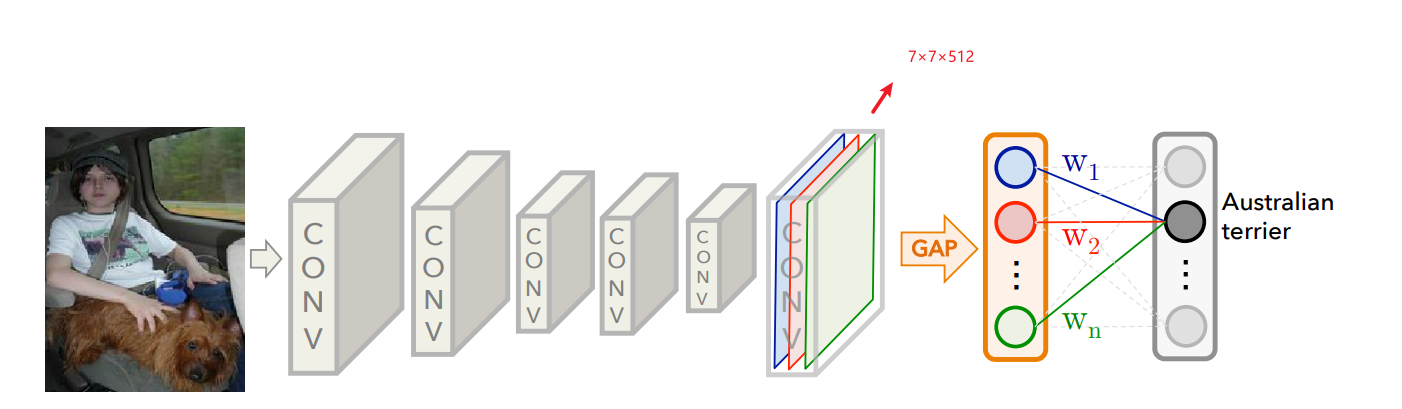
- 通过 GAP 层后则会得到 $1 \times 1 \times 512$ 的特征随后放到全连接层中进行分类、SoftMax 激活得到分类结果

CAM 实现
- 而 CAM 的实现则需要暂时略去 GAP 层,将 $7 \times 7 \times 512$ 特征直接划分为 $ 49 \times 512$ 的向量,分别对 $49$ 个向量执行全连接、激活的步骤即可得到 CAM 可视化图像

实现是容易的,但这种方法为何合理,为何仅对 GAP 层可用需要进一步讨论
CAM 合理性的一种解释
- 分类时全连接层为统一后的特征进行分类,那么 CAM 可以看做是分类头为 $7 \times 7$ 网格中每一个格子 —— 也可以说是图像中近似 $1/49$ 的区域进行分类
- 因此可以得到 $7 \times 7$个分类结果,随后将结果 resize 到原图尺寸,即可查看模型将该数据归类的依据
- 这种方式其实类似于分割网络的实现过程
- 依赖于卷积神经网络结构,需要原始图像与特征图有较强的位置相关性
对 GAP 层的依赖
-
事实上 GMP 层也完全可以执行 CAM 的过程,也可以看到类似的注意力热力图,甚至(如果你尝试过)你可以发现有时候 GMP 的 CAM 结果也是有模有样的
-
但是 GMP 得到的特征进行 CAM 得到的可视化结果理论上是不可靠的
-
分类时最末的特征处理为:
$$
Feature -> GAP -> MLP >> Logits
$$ -
GAP 是 WH 方向上的平均操作,是线性操作
-
MLP 是Channel 方向上的加权平均,也是线性操作
-
那么将二者的顺序交换并不影响网络最终输出的结果:
$$
Feature-> MLP -> GAP >> Logits
$$ -
两种路线得到的 $Logits$ 是相同的,那么 MLP 层之后的结果可以用于考察模型是否得到了正确的注意力
此类考察建立在 $Feature$ 与原始输入图像有较强相关性的基础上,例如网络结构为 $Transformer$ 那么此种结构的 CAM 则会难以起作用
-
如果将 GAP 层替换为 GMP 层,则由于 GMP 层并不是线性操作
$$
Feature -> GMP -> MLP \neq Feature -> MLP -> GMP
$$ -
因此尽管可以看到 GMP 层的 CAM 图但是并不能代表真实的模型注意力
-
-
因此结论就是 CAM 对于 GAP 层的特征可以有效查看模型注意力热力图
原始论文
参考资料
- https://blog.csdn.net/herr_kun/article/details/106997646
- https://arxiv.org/pdf/1512.04150.pdf
- https://zhuanlan.zhihu.com/p/51631163
- https://blog.csdn.net/qq_30159015/article/details/79765520
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/visualization/cam/cam/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付