本文最后更新于:2024年5月7日 下午
Transformer是nlp领域的常见模型了,在Attention is All You Need一文中凭借着嚣张的题目和明显的效果席卷了nlp的各个领域。最近CV领域也出现了一些使用Transformer的论文,本文介绍 ICLR 2021 的亮点工作之一 Vision Transformer ,也就是传说中的 VIT。
简介
Transformer 架构早已在自然语言处理任务中得到广泛应用,但在计算机视觉领域中仍然受到限制。在计算机视觉领域,注意力要么与卷积网络结合使用,要么用来代替卷积网络的某些组件,同时保持其整体架构不变。
VIT在研究中表明,视觉网络对 CNN 的依赖不是必需的,当直接面对图像块序列时,transformer 也能很好地执行图像分类任务。而且可以获得与当前最优卷积网络相媲美的结果,而且训练所需的计算资源大大减少。
工作流程

VIT 的目的是将 NLP 中的 Transformer 引入到视觉领域,并得到 Transformer 在原有领域中的性能收益,因此基础架构尽可能照搬了原始 Transformer。
1. 图像变形
由于序列模型输入是1D向量,为了将2D图像应用Transormer,将图像 $ \mathbf{x} \in \mathbb{R}^{H \times W \times C} $进行 reshape ,得到$ \mathbf{x_p} \in \mathbb{R}^{N \times (P^2·C) } $
- $H,W$是图像的高和宽,$C$为原始图像通道,rgb的情况下 $C$ 为3
- 将原图分为一个个 $P\times P$ 的小图,这样小图的个数为 $N = HW/P^2$
- 这样输入由3D转为2D数据,理解为$N$组特征向量,可以套用 transormer 的流程了
- 输入的数据此时表示为:
2. 维度投影
Transformer 的隐藏特征维度定死为 $D$,而当前每个输入 patch 块的维度为 $P^2C$
- 设计了一个可以学习的矩阵 $ E \in \mathbb{R}^{\left(P^{2} \cdot C\right) \times D} $,每个块经过投影后,得到 $ \mathbf{x}_{p}^{i} \mathbf{E} \in \mathbb{R}^{D}$
- 此时N个小patch数据可以表示为:
$$
[x _ { p } ^ { 1 } E ; x _ { p } ^ { 2 } E ; \cdots ; x _ { p } ^ { N } E],\mathbf{x}_{p}^{i} \mathbf{E} \in \mathbb{R}^{D}
$$
3.token
类似BERT的 token,在输入图像块序列的起始位置添加一个可以学习的序列,$ \mathbf{x}_{\text {class }} \in \mathbb{R}^{D}$
- 那么现在输入序列($N+1$ 组)可以表示为:
$$
[x_{class};x _ { p } ^ { 1 } E ; x _ { p } ^ { 2 } E ; \cdots ; x _ { p } ^ { N } E]
$$
4.位置编码
将位置 embedding 添加到每个图像块中,以保留位置信息。文章中使用了标准的1D位置编码(2D没有性能收益)。
- 位置编码用$E_{pos}$表示,$ {E}_{p o s} \in \mathbb{R}^{(N+1) \times D} $
- 叠加了位置编码信息的图像块作为编码器的输入,用$\mathbf{z}_0$表示:
5.Transformer 编码
得到初始输入$\mathbf{z}_0$后,数据会经过$L$轮特征提取,对于已经获得到的第$l=0…L-1$,层特征$\mathbf{z}_l$,需要分别经过多头自注意力模块(MSA)和一个全连接层(MLP),在经过二者前都需要进行层归一化(LN),每个模块结束会经历残差连接。
-
得到特征:
$$
\mathbf{z}_l,0 \le l \le L-1
$$ -
经过MSA模块,提取特征得到 $\mathbf{z} ^ { \prime }_{l+1}$:
- 将$\mathbf{z} ^ { \prime }_{l+1}$ 送入MLP模块,得到$\mathbf{z}_{l+1}$:
6.图像表示
将$\mathbf{x} _ { class }$经过$L$轮特征提取后得到的结果 $ \mathbf{z} _ {L}^{0} $ 通过层归一化得到图像表示 $\mathbf{y}$,也就是图像的分类信息:
$$
\mathbf{y}=\mathrm{LN}\left(\mathbf{z}_{L}^{0}\right)
$$
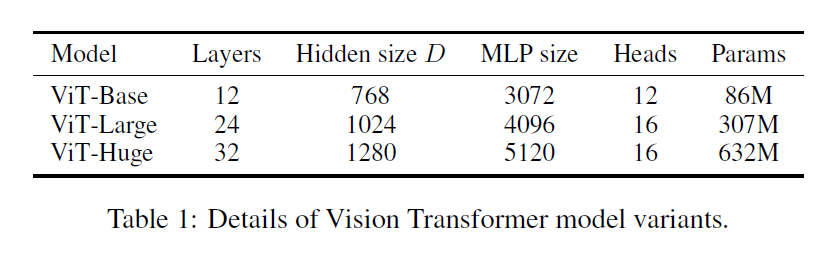
模型规模
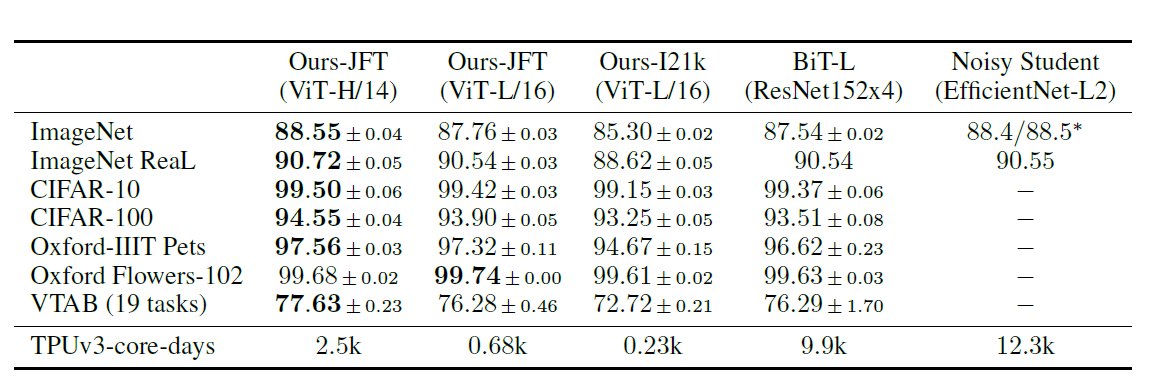
实验结果
结论
ViT工作将Transformer从NLP带到了视觉领域,而且获得了不俗的性能,以较低的预训练成本在大多数识别基准上达到了最先进的水平。
原始论文
《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》
参考资料
- https://zhuanlan.zhihu.com/p/273652295
- https://blog.csdn.net/qq_16236875/article/details/108964948
- https://zhuanlan.zhihu.com/p/48508221
- https://zhuanlan.zhihu.com/p/359071701
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/transformer/vision-transformer/vision-transformer/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付