本文最后更新于:2024年5月7日 下午
基于CPU和GPU的异构计算已经逐步发展成为高性能计算的主流模式。CUDA作为GPU高性能计算的主要开发工具之一,已经在各个领域取得广泛应用。
什么是GPU
GPU全名为Graphics Processing Unit,又称视觉处理器、图形显示卡。GPU负责渲染出2D、3D、VR效果,主要专注于计算机图形图像领域。后来人们发现,GPU非常适合并行计算,可以加速现代科学计算,GPU也因此不再局限于游戏和视频领域。
加速原理
为了同时并行地处理更多任务,芯片公司开发出了多核架构,只要相互之间没有依赖,每个核心做自己的事情,多核之间互不干扰,就可以达到并行计算的效果,极大缩短计算时间。
CPU与GPU
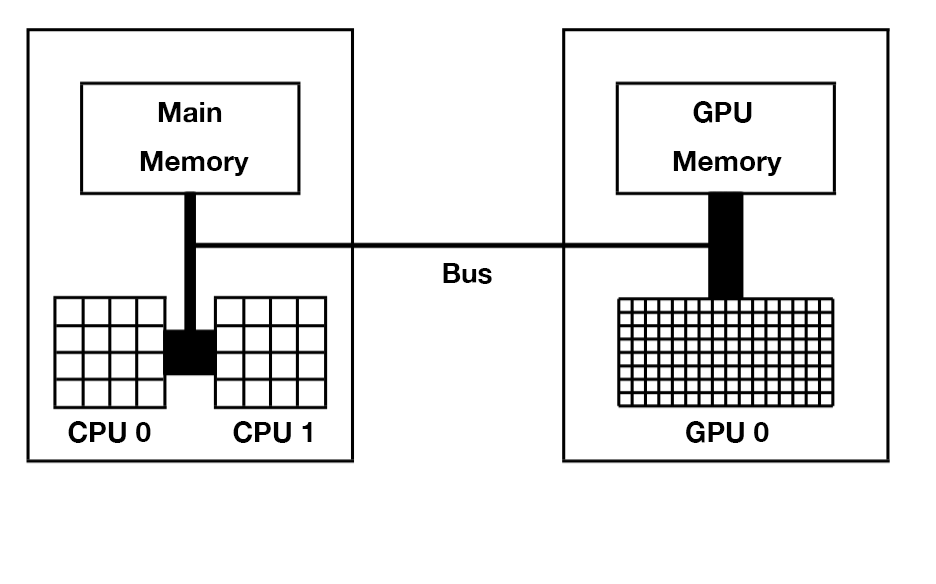
CPU主要从主存(Main Memory)中读写数据,并通过总线(Bus)与GPU交互。GPU除了有超多计算核心外,也有自己独立的存储,被称之为显存。一台服务器上可以安装多块GPU卡,但GPU卡的发热量极大,普通的空调系统难以给大量GPU卡降温,所以大型数据中心通常使用水冷散热,并且选址在温度较低的地方。
主机与设备
由于CPU和GPU是分开的,在英伟达的设计理念里,CPU和主存被称为主机(Host),GPU被称为设备(Device)。Host和Device概念会贯穿整个英伟达GPU编程,甚至包括OpenCL等其他平台。
以上结构也被称为异构计算:使用CPU+GPU组合来加速计算。绝大多数的高性能计算中心会使用上图所示的结构,比如一台服务器上有2至4块Intel Xeon CPU和1至8块英伟达GPU显卡,多台机器之间通过InfiniBand高速网络互联。
英伟达GPU硬件架构
在英伟达的设计里,多个核心组成一个Streaming Multiprocessor(SM),一张GPU卡有多个SM。从“Multiprocessor”这个名字上也可以看出SM包含了多个处理器。实际上,英伟达主要以SM为运算和调度的基本单元。

英伟达不同时代产品的芯片设计不同,每代产品背后有一个微架构代号,微架构均以著名的物理学家为名,以向先贤致敬。当前比较火热的架构有:
- Ampere 安培
- 2020年5月发布
- 专业显卡:Telsa A100
- Turing 图灵
- 2018年发布
- 消费显卡:GeForce RTX 2080 Ti、Titan RTX
- Volta 伏特
- 2017年末发布
- 专业显卡:Telsa V100 (16或32GB显存 5120个CUDA核心)
- Pascal 帕斯卡
- 2016年发布
- 专业显卡:Telsa P100(12或16GB显存 3584个CUDA核心)
软件生态
英伟达能够在人工智能时代成功,除了他们在长期深耕显卡芯片领域,更重要的是他们率先提供了可编程的软件架构,确切地说,软硬件一体方案帮他们赢得了市场。2007年,英伟达发布了CUDA(Compute Unified Device Architecture)编程模型,软件开发人员从此可以使用CUDA在英伟达的GPU上进行并行编程。在此之前,GPU编程并不友好。CUDA简单到什么程度?有经验的程序员经过半天的培训,掌握一些基础概念后,能在半小时内将一份CPU程序修改成为GPU并行程序。
继CUDA之后,英伟达不断丰富其软件技术栈,提供了科学计算所必需的cuBLAS线性代数库,cuFFT快速傅里叶变换库等,当深度学习大潮到来时,英伟达提供了cuDNN深度神经网络加速库,目前常用的TensorFlow、PyTorch深度学习框架的底层大多基于cuDNN库。
关于英伟达的软件栈,可以总结为:
- 最底层是GPU硬件,包括各类GPU显卡,DGX工作站等。
- 操作系统是基于硬件的第一层软件,在操作系统上我们需要安装GPU驱动。
- CUDA在GPU驱动之上,有了CUDA,我们可以进行一些GPU编程。
- 英伟达对相似计算进一步抽象,进而有了cuBLAS、cuFFT、cuDNN等库,这些库基于CUDA提供常见的计算。
- 最顶层是应用,包括TensorFlow和PyTorch的模型训练和推理过程。
CUDA
英伟达能在人工智能时代击败Intel、AMD等强大对手,很大一部分是因为它丰富的软件体系。这些软件工具库使研发人员专注于自己的研发领域,不用再去花大量时间学习GPU底层知识。CUDA对于GPU就像个人电脑上的Windows、手机上的安卓系统,一旦建立好生态,吸引了开发者,用户非常依赖这套软件生态体系。
- GPU编程可以直接使用CUDA的C/C++版本进行编程,也可以使用其他语言包装好的库,比如Python可使用Numba库调用CUDA。CUDA的编程思想在不同语言上都很相似。
CUDA及其软件栈的优势是方便易用,缺点也显而易见:
- 软件环境复杂,库以及版本很多,顶层应用又严重依赖底层工具库,入门者很难快速配置好一整套环境;多环境配置困难。
- 用户只能使用英伟达的显卡,成本高,个人用户几乎负担不起。
英伟达之外的选项
-
前文对GPU的描述主要基于英伟达旗下产品。在GPU领域,AMD也提供了独立显卡产品,价格较低。历史上,AMD的显卡产品线是收购ATI而获得的。相对来说,AMD的显卡在人工智能和超级计算领域并没有英伟达强势。为了与CUDA对抗,AMD提供的软件开发平台名为ROCm(Radeon Open Compute platforM )。
-
与相对封闭的CUDA不同,OpenCL(Open Computing Language)也是当前重要的计算加速平台,可以兼容英伟达和AMD的GPU,以及一些FPGA等硬件。一些上层软件为了兼容性,在计算加速部分并没有使用CUDA,而是使用了OpenCL。比如,决策树算法框架LightGBM主要基于OpenCL进行GPU加速。
无论是ROCm还是OpenCL,其编程思想与CUDA都非常相似,如果掌握了CUDA,那上手OpenCL也会很容易。
参考资料
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/speed-up/numba/numba/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付