本文最后更新于:2024年5月7日 下午
本文介绍GPU编程的一些重要概念。
GPU编程
GPU编程与CPU编程的思考角度不尽相同,举皮皮鲁老师的一个例子:
以加法计算为例,CPU就像大学数学教授,GPU就像几千个小学生,现在需要不借助外界,只通过纸笔,对2000个数字进行加法计算,得到1000个加法结果,在这个过程中,大学教授要协调指挥小学生完成任务。
在计算过程中,每个小学生需要按照大学教授的提出的规范,基于一个加法函数,完成计算。每个小学生就像GPU的一个计算核心,加法函数就是核函数,一个小学生完成本次计算就像一次线程计算。在整个计算过程中,只能通过纸笔交流,无论是计算任务本身,还是计算的中间结果都需要落地到纸上进行计算,作为记录的纸就像是计算机中的存储,
假设我们有2000个数字需要加到一起,得到1000个加法结果。如果只依赖20个大学教授,那每个教授需要执行50次计算,耗时很长。如果大学教授可以借助1000个小学生同时计算,那么大学教授可以这样设计GPU并行算法:
- 设计一个加法函数,加法函数可以将两个数字加在一起。
- 每个小学生分配2个数字,使用加法函数,对这2个数字执行计算。
- 大学教授给1000个小学生分配数字,并告知他们使用怎样的加法函数进行计算。
- 1000个小学生同时计算,得到1000个结果数字,写到纸上,返回给大学教授。
实际上,CUDA并行算法和上面的流程基本相似,就是设计核函数,在存储上合理分配数据,告知GPU以一定的并行度执行配置来并行计算。核函数的设计与所要解决的问题本身高度相关。
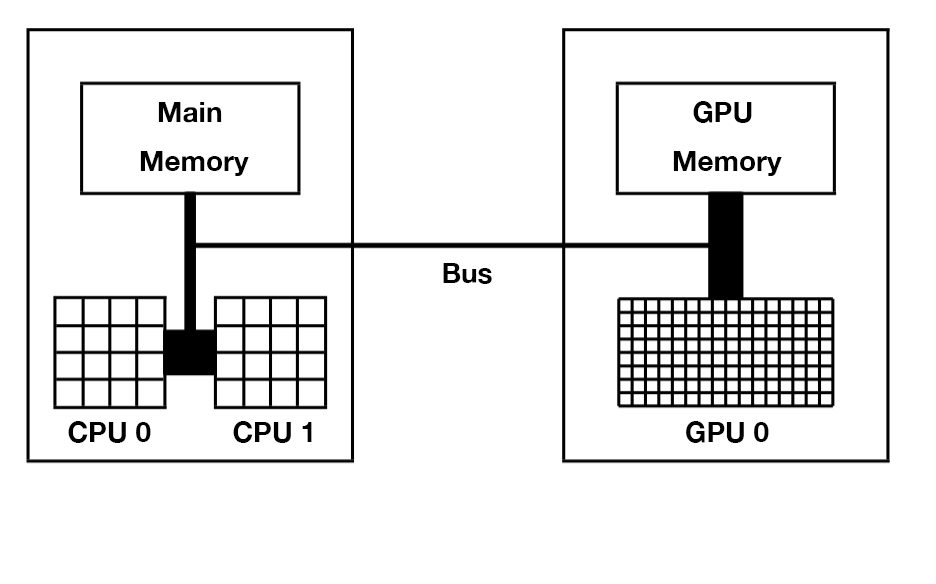
主机与设备
在CUDA中,CPU和主存被称为主机(Host),GPU和显存(显卡内存)被称为设备(Device),CPU无法直接读取显存数据,GPU无法直接读取主存数据,主机与设备必须通过总线(Bus)相互通信。
GPU程序与CPU程序的区别
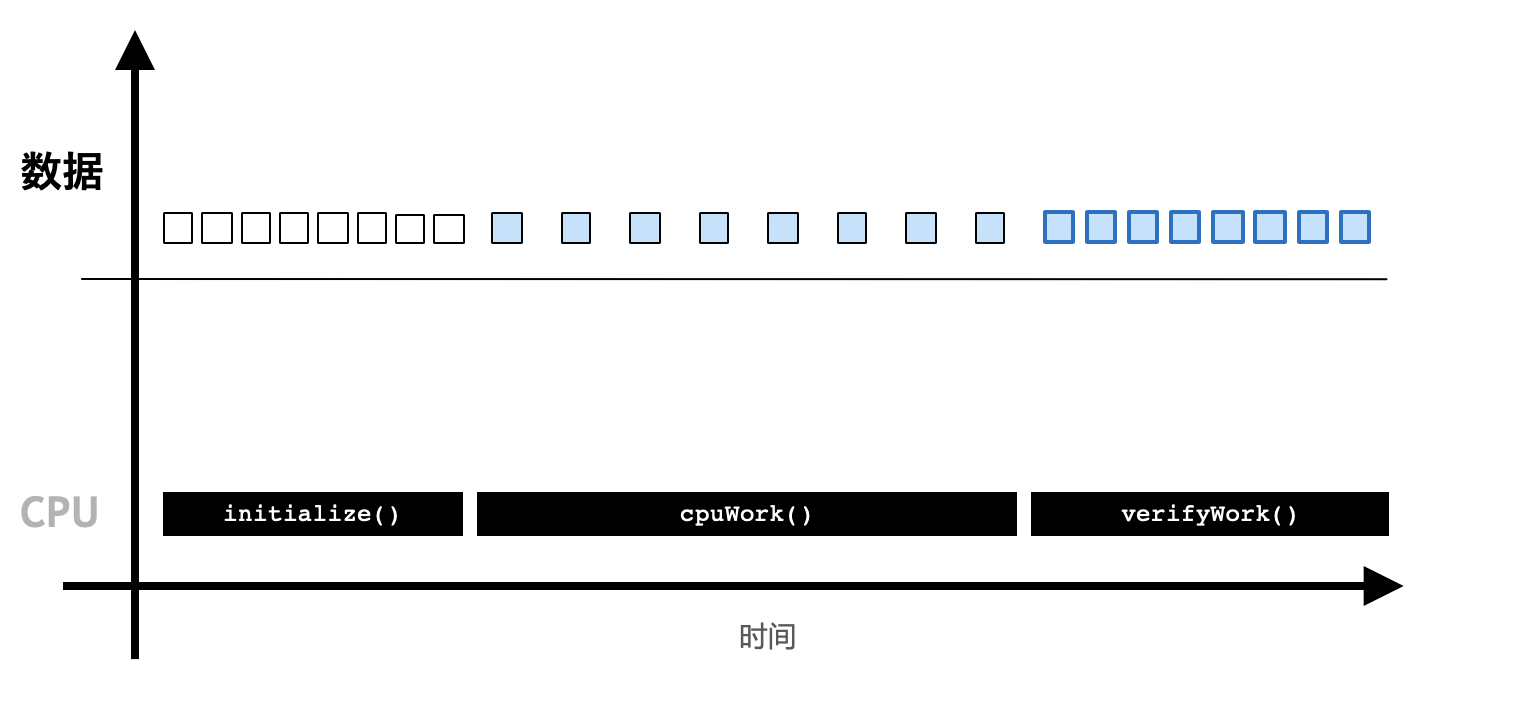
CPU程序
- 初始化。
- CPU计算。
- 得到计算结果。
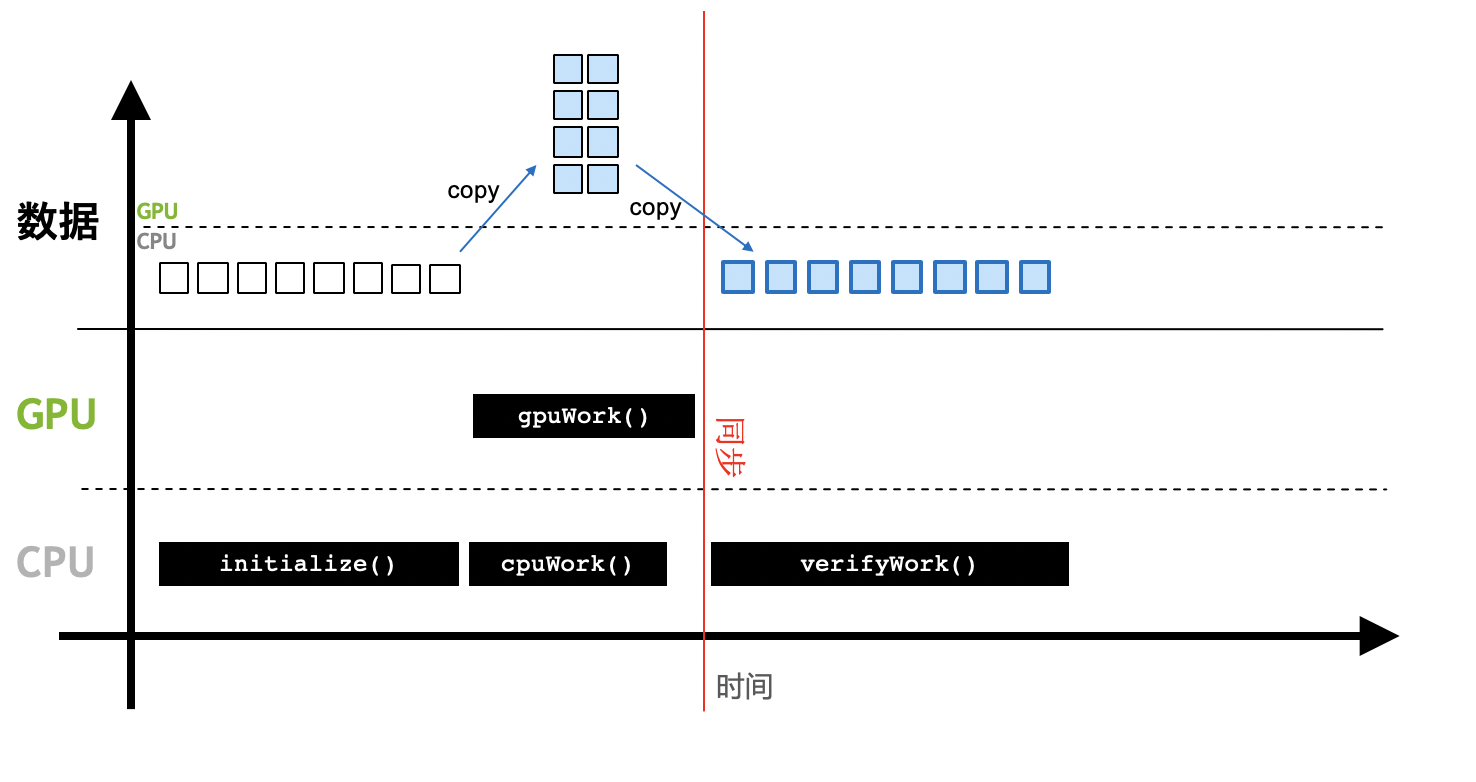
GPU程序
- 初始化,并将必要的数据拷贝到GPU设备的显存上。
- CPU调用GPU函数,启动GPU多个核心同时进行计算。
- CPU与GPU异步计算。
- 将GPU计算结果拷贝回主机端,得到计算结果
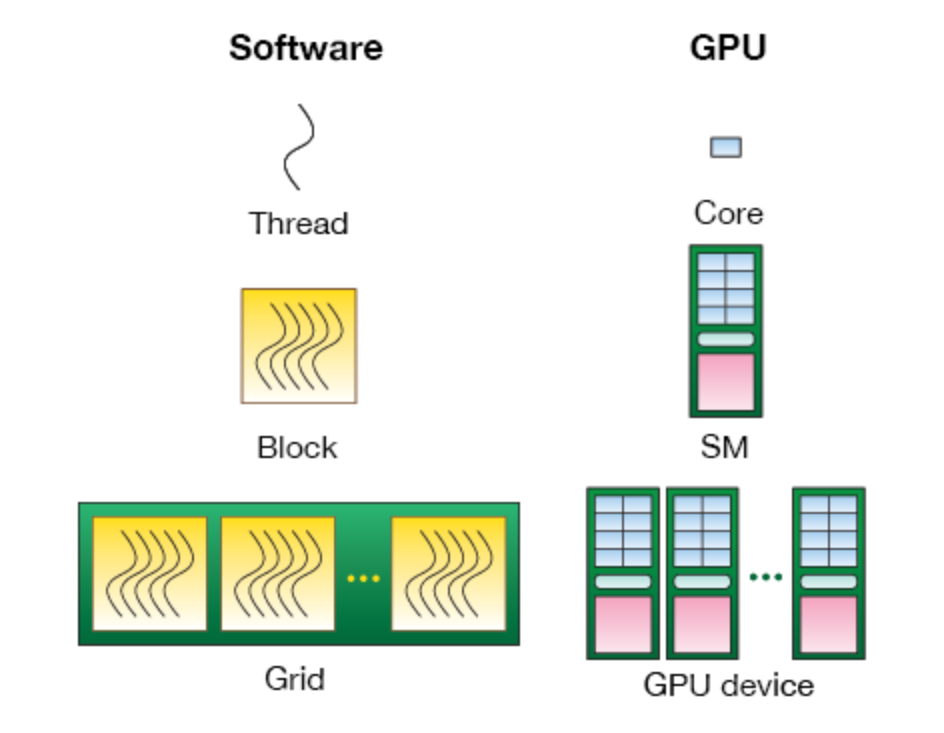
Thread层次结构
在进行GPU并行编程时,需要定义执行配置来告知以怎样的方式去并行执行核函数。CUDA将核函数所定义的运算称为线程(Thread),多个线程组成一个块(Block),多个块组成网格(Grid)。这样一个Grid可以定义成千上万个线程,也就解决了并行执行上万次操作的问题。

实际上,线程(Thread)是一个编程上的软件概念。从硬件来看,Thread运行在一个CUDA核心上,多个Thread组成的Block运行在Streaming Multiprocessor(SM),多个Block组成的Grid运行在一个GPU显卡上。
 )
)
CUDA提供了一系列内置变量,以记录Thread和Block的大小及索引下标。以[2, 4]这样的配置为例:blockDim.x变量表示Block的大小是4,即每个Block有4个Thread,threadIdx.x变量是一个从0到blockDim.x - 1(4-1=3)的索引下标,记录这是第几个Thread;gridDim.x变量表示Grid的大小是2,即每个Grid有2个Block,blockIdx.x变量是一个从0到gridDim.x - 1(2-1=1)的索引下标,记录这是第几个Block。
某个Thread在整个Grid中的位置编号为:threadIdx.x + blockIdx.x * blockDim.x。
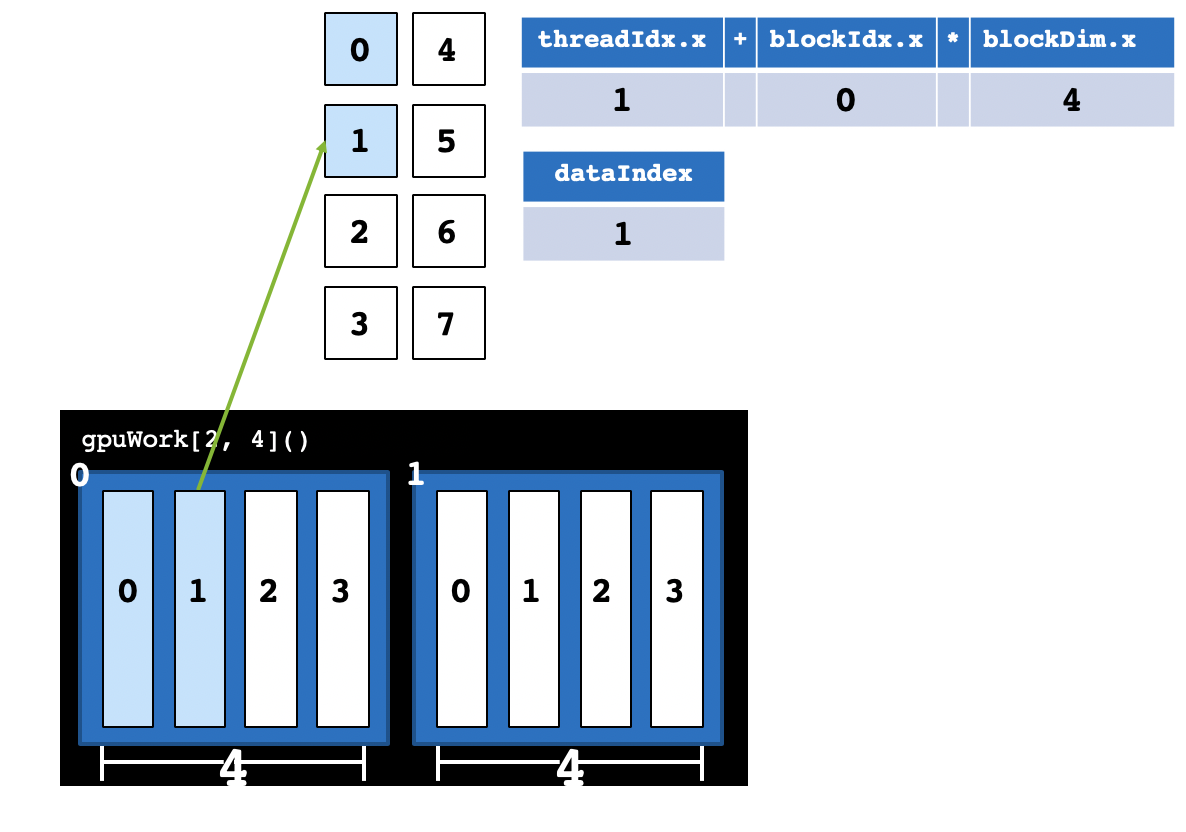
Block大小设置
不同的执行配置会影响GPU程序的速度,一般需要多次调试才能找到较好的执行配置,在实际编程中,执行配置[gridDim, blockDim]应参考下面的方法:
- Block运行在SM上,不同硬件架构(Turing、Volta、Pascal…)的CUDA核心数不同,一般需要根据当前硬件来设置Block的大小
blockDim(执行配置中第二个参数)。一个Block中的Thread数最好是32、128、256的倍数。注意,限于当前硬件的设计,Block大小不能超过1024。 - Grid的大小
gridDim(执行配置中第一个参数),即一个Grid中Block的个数可以由总次数N除以blockDim,并向上取整。
例如,我们想并行启动1000个Thread,可以将blockDim设置为128,1000 ÷ 128 = 7.8,向上取整为8。使用时,执行配置可以写成gpuWork[8, 128](),CUDA共启动8 * 128 = 1024个Thread,实际计算时只使用前1000个Thread,多余的24个Thread不进行计算。
这几个变量比较容易混淆,再次明确一下:blockDim是Block中Thread的个数,一个Block中的threadIdx最大不超过blockDim;gridDim是Grid中Block的个数,一个Grid中的blockIdx最大不超过gridDim。
以上讨论中,Block和Grid大小均是一维,实际编程使用的执行配置常常更复杂,Block和Grid的大小可以设置为二维甚至三维:
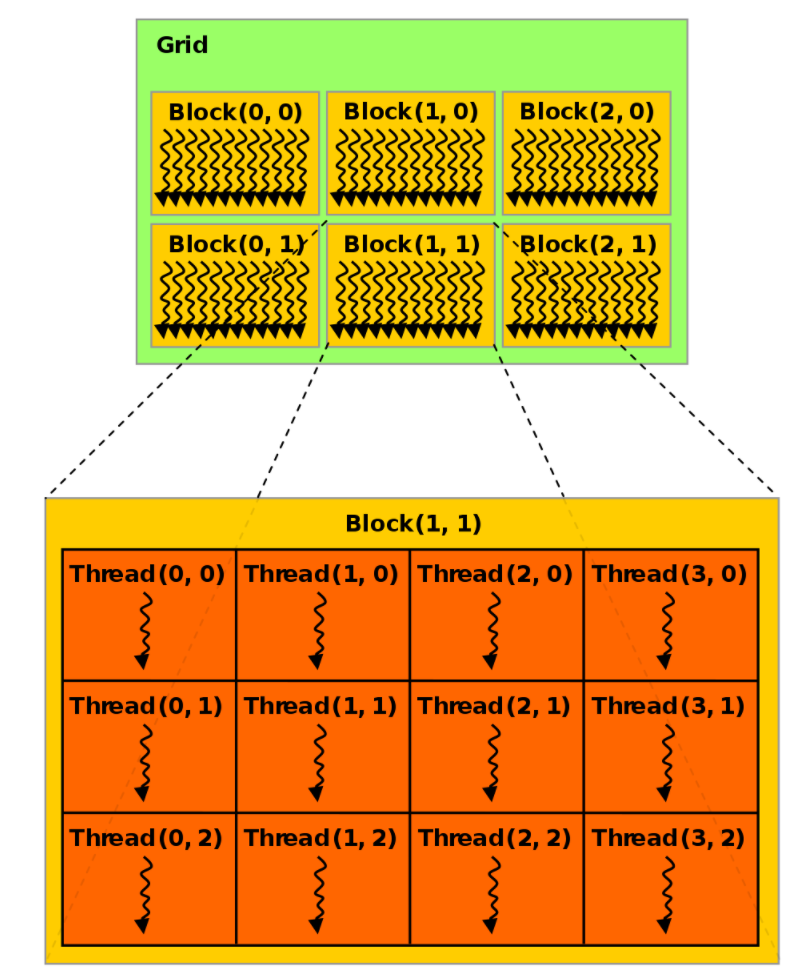
一个二维的执行配置如上图所示,其中,每个Block有(3 * 4)个Thread,每个Grid有(2 * 3)个Block。 二维块大小为 (Dx, Dy),某个线程号 (x, y) 的公式为 (x + y Dx);三维块大小为 (Dx, Dy, Dz),某个线程号*(x, y, z)* 的公式为 (x + y Dx + z Dx Dy)。各个内置变量中.x .y和.z为不同维度下的值。
例如,一个二维配置,某个线程在矩阵中的位置可以表示为:
1 | |
如何将二维Block映射到自己的数据上并没有固定的映射方法,一般情况将.x映射为矩阵的行,将.y映射为矩阵的列。Numba提供了一个更简单的方法帮我们计算线程的编号:
1 | |
其中,参数2表示这是一个2维的执行配置。1维或3维的时候,可以将参数改为1或3。
对应的执行配置也要改为二维:
1 | |
(16, 16)的二维Block是一个常用的配置,共256个线程。之前也曾提到过,每个Block的Thread个数最好是128、256或512,这与GPU的硬件架构高度相关。
内存分配
前文提到,GPU计算时直接从显存中读取数据,因此每当计算时要将数据从主存拷贝到显存上,用CUDA的术语来说就是要把数据从主机端拷贝到设备端。用小学生计算的例子来解释,大学教授需要将计算任务写在纸上,分发给各组小学生。CUDA强大之处在于它能自动将数据从主机和设备间相互拷贝,不需要程序员在代码中写明。这种方法对编程者来说非常方便,不必对原有的CPU代码做大量改动。
参考资料
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/speed-up/numba-usage/numba-usage/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付