本文最后更新于:2024年5月11日 下午
之前讨论的并行,都是线程级别的,即CUDA开启多个线程,并行执行核函数内的代码。GPU最多就上千个核心,同一时间只能并行执行上千个任务。当我们处理千万级别的数据,整个大任务无法被GPU一次执行,所有的计算任务需要放在一个队列中,排队顺序执行。CUDA将放入队列顺序执行的一系列操作称为流(Stream)。
来源
由于异构计算的硬件特性,CUDA中以下操作是相互独立的,通过编程,是可以操作他们并发地执行的:
- 主机端上的计算
- 设备端的计算(核函数)
- 数据从主机和设备间相互拷贝
- 数据从设备内拷贝或转移
- 数据从多个GPU设备间拷贝或转移
针对这种互相独立的硬件架构,CUDA使用多流作为一种高并发的方案:
- 把一个大任务中的上述几部分拆分开,放到多个流中,每次只对一部分数据进行拷贝、计算和回写,并把这个流程做成流水线。
- 因为数据拷贝不占用计算资源,计算不占用数据拷贝的总线(Bus)资源,因此计算和数据拷贝完全可以并发执行。
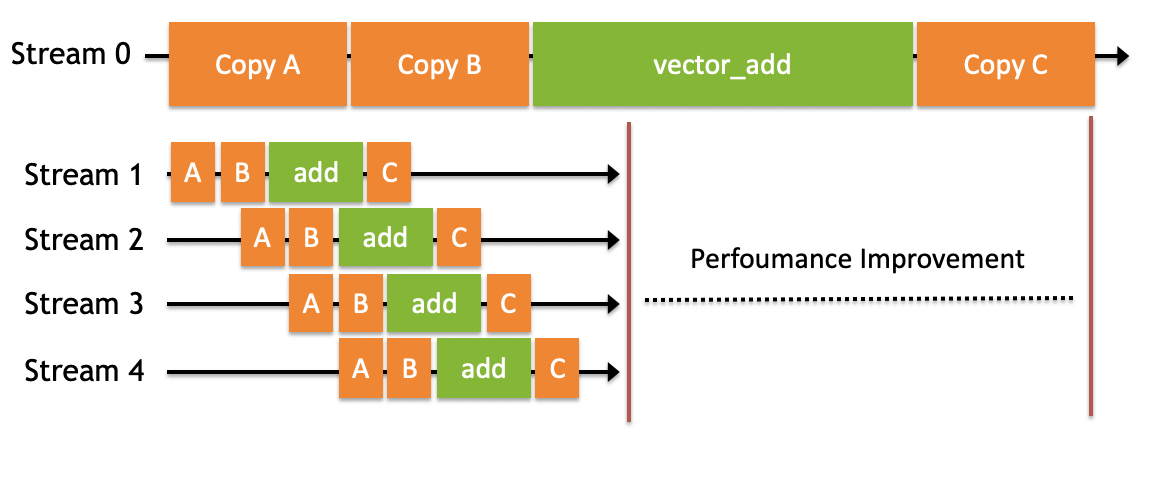
- 如图所示,将数据拷贝和函数计算重叠起来的,形成流水线,能获得非常大的性能提升。
实际上,流水线作业的思想被广泛应用于CPU和GPU等计算机芯片设计上,以加速程序。
多流
以向量加法为例,上图中第一行的Stream 0部分是我们之前的逻辑,没有使用多流技术,程序的三大步骤是顺序执行的:
-
先从主机拷贝初始化数据到设备(Host To Device);
-
在设备上执行核函数(Kernel);
-
将计算结果从设备拷贝回主机(Device To Host)。
当数据量很大时,每个步骤的耗时很长,后面的步骤必须等前面执行完毕才能继续,整体的耗时相当长。
以2000万维的向量加法为例,向量大约有几十M大小,将整个向量在主机和设备间拷贝将占用占用上百毫秒的时间,有可能远比核函数计算的时间多得多。将程序改为多流后,每次只计算一小部分,流水线并发执行,会得到非常大的性能提升。
规则
默认情况下,CUDA使用0号流,又称默认流。不使用多流时,所有任务都在默认流中顺序执行,效率较低。在使用多流之前,必须先了解多流的一些规则:
- 给定流内的所有操作会按序执行。
- 非默认流之间的不同操作,无法保证其执行顺序。
- 所有非默认流执行完后,才能执行默认流;默认流执行完后,才能执行其他非默认流。

参照上图,可将这三个规则解释为:
- 非默认流1中,根据进流的先后顺序,核函数1和2是顺序执行的。
- 无法保证核函数2与核函数4的执行先后顺序,因为他们在不同的流中。他们执行的开始时间依赖于该流中前一个操作结束时间,例如核函数2的开始依赖于核函数1的结束,与核函数3、4完全不相关。
- 默认流有阻塞的作用。如图中红线所示,如果调用默认流,那么默认流会等非默认流都执行完才能执行;同样,默认流执行完,才能再次执行其他非默认流。
某个流内的操作是顺序的,非默认流之间是异步的,默认流有阻塞作用。
使用
定义
如果想使用多流时,必须先定义流:
1
| stream = numba.cuda.stream()
|
CUDA的数据拷贝以及核函数都有专门的stream参数来接收流,以告知该操作放入哪个流中执行:
numba.cuda.to_device(obj, stream=0, copy=True, to=None)numba.cuda.copy_to_host(self, ary=None, stream=0)
核函数调用的地方除了要写清执行配置,还要加一项stream参数:
kernel[blocks_per_grid, threads_per_block, stream=0]
根据这些函数定义也可以知道,不指定stream参数时,这些函数都使用默认的0号流。
对于程序员来说,需要将数据和计算做拆分,分别放入不同的流里,构成一个流水线操作。
将之前的向量加法的例子改为多流处理,完整的代码为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| from numba import cuda
import numpy as np
import math
from time import time
@cuda.jit
def vector_add(a, b, result, n):
idx = cuda.threadIdx.x + cuda.blockDim.x * cuda.blockIdx.x
if idx < n :
result[idx] = a[idx] + b[idx]
def main():
n = 20000000
x = np.random.uniform(10,20,n)
y = np.random.uniform(10,20,n)
start = time()
x_device = cuda.to_device(x)
y_device = cuda.to_device(y)
z_device = cuda.device_array(n)
z_streams_device = cuda.device_array(n)
threads_per_block = 1024
blocks_per_grid = math.ceil(n / threads_per_block)
vector_add[blocks_per_grid, threads_per_block](x_device, y_device, z_device, n)
default_stream_result = z_device.copy_to_host()
cuda.synchronize()
print("gpu vector add time " + str(time() - start))
start = time()
number_of_streams = 5
segment_size = n // number_of_streams
stream_list = list()
for i in range (0, number_of_streams):
stream = cuda.stream()
stream_list.append(stream)
threads_per_block = 1024
blocks_per_grid = math.ceil(segment_size / threads_per_block)
streams_result = np.empty(n)
for i in range(0, number_of_streams):
x_i_device = cuda.to_device(x[i * segment_size : (i + 1) * segment_size], stream=stream_list[i])
y_i_device = cuda.to_device(y[i * segment_size : (i + 1) * segment_size], stream=stream_list[i])
vector_add[blocks_per_grid, threads_per_block, stream_list[i]](
x_i_device,
y_i_device,
z_streams_device[i * segment_size : (i + 1) * segment_size],
segment_size)
streams_result[i * segment_size : (i + 1) * segment_size] = z_streams_device[i * segment_size : (i + 1) * segment_size].copy_to_host(stream=stream_list[i])
cuda.synchronize()
print("gpu streams vector add time " + str(time() - start))
if (np.array_equal(default_stream_result, streams_result)):
print("result correct")
if __name__ == "__main__":
main()
|
运行结果:
1
2
| gpu vector add time 7.996402740478516
gpu streams vector add time 0.3867764472961426
|
多流不仅需要程序员掌握流水线思想,还需要用户对数据和计算进行拆分,并编写更多的代码,但是收益非常明显。对于计算密集型的程序,这种技术非常值得认真研究。
参考资料
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/speed-up/cuda-multistream/cuda-multistream/

