本文最后更新于:2024年5月7日 下午
numpy 和 pytorch tensor 存在内存是否连续的情况,对运行速度甚至网络运行结果都存在影响。
含义
- contiguous 本身是形容词**,**表示连续的。所谓
contiguous array,指的是数组在内存中存放的地址也是连续的(注意内存地址实际是一维的),即访问数组中的下一个元素,直接移动到内存中的下一个地址就可以。 - 在numpy和torch的数据结构中,都有表示变量是否在内存中数据连续存储的概念。
- 连续存储又分为按照行优先(C order)和按照列优先(Fortran order)
行优先 C order
行是指多维数组一维展开的方式,对应的是列优先。C/C++中使用的是行优先方式(row major),Matlab、Fortran使用的是列优先方式(column major),PyTorch中Tensor底层实现是C,也是使用行优先顺序,因此也称为 C order。
- Pascal, C,C++,Python都是行优先存储的。
列优先 Fortran order
而Fortran Order则指的是列优先的顺序(Column-major Order),即内存中同列的元素存在一起。
- Fortran,MatLab是列优先存储的。
数据举例
行优先
考虑一个2维数组arr = np.arange(12).reshape(3,4)。这个数组看起来结构是这样的:

在计算机的内存里,数组arr实际存储是像下图所示的:

这意味着arr是C连续的(C contiguous)的,因为在内存是行优先的,即某个元素在内存中的下一个位置存储的是它同行的下一个值。
如果想要向下移动一列,则只需要跳过3个块既可(例如,从0到4只需要跳过1,2和3)。
1 | |
- 输出:
1 | |
- C_CONTIGUOUS 为 True 表示该矩阵行连续
也就是其中的行 [ 0 1 2 3] 在内存中连续,那么 [0 4 8] 就不会连续了,因此 F_CONTIGUOUS 为 False
列优先
上述数组的转置arr.T则没有了C连续特性,因为同一行中的相邻元素现在并不是在内存中相邻存储的了:
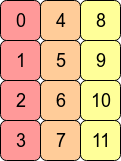
这里要说明一下,如果直接用这些值创建的numpy变量是连续的,因为Python默认 C order,新创建的numpy都是行优先的
但是我们创建arr时是以 0 - 11 为顺序创建的,其中[0 1 2 3] [4 5 6 7] [8 9 10 11]连续,矩阵转置后只改变引用,内存数据并不发生变化
类似的操作如numpy 的
slice、transpose、转置或 tensor中的permute等操作都可能导致改变之前数据与内存的行连续状况
- 转置后,内存上仍然是 [0 1 2 3] [4 5 6 7] [8 9 10 11]连续,在当前矩阵上就是列连续,因此这是个Fortran order 连续的矩阵
1 | |
- 输出:
1 | |
查看连续性
numpy
- 可以使用
data.contiguous、data.c_contiguous、data.f_contiguous属性 - 或者使用
flags属性
1 | |
- 输出
1 | |
pytorch
- pytorch 的 tensor 有方法
is_contiguous用来查看是否 C 连续
1 | |
- 输出
1 | |
产生的影响
性能影响
从性能上来说,获取内存中相邻的地址比不相邻的地址速度要快很多(从RAM读取一个数值的时候可以连着一起读一块地址中的数值,并且可以保存在Cache中),这意味着对连续数组的操作会快很多。
由于
arr是C连续的,因此对其进行行操作比进行列操作速度要快通常来说
np.sum(arr, axis=1) # 按行求和会比
np.sum(arr, axis=0) # 按列求和稍微快些。
同理,在
arr.T上,列操作比行操作会快些。
结果影响
其实写这篇博客的原因,就是我的onnx模型对于完全相同数据的tensor产生了完全不同的表现,险些三观俱碎。挣扎了几个小时后发现原来是数据的连续性在作祟。
- 对 pyhton 中算法平台的影响
| 平台 | 影响 |
|---|---|
| numpy | 计算不连续的变量,结果不会受到影响 |
| pytorch | 输入不连续的tensor,结果不会受到影响 |
| onnx | 输入不连续的tensor,结果直接爆炸 |
- 在 python 的 tensor 中,如果不是C连续的tensor,在执行
view方法时会报错:
1 | |
- 在 numpy 中某些需要连续的操作在遇到不连续的变量时也会报错:
1 | |
连带影响
- 不连续的numpy转为tensor后也是不连续的
- 不连续的tensor转为numpy后也是不连续的
修正连续性
变量可以通过重新开辟空间,将数据连续拷贝进去的方法将不连续的数据变成某种连续方式。
numpy
- numpy 变量中连续性可以用自带的函数修正,不连续的变量通过函数
np.ascontiguousarray(arr)变为C连续,np.asfortranarray(arr)变为Fortran连续
1 | |
- 输出:
1 | |
pytorch
- pytorch 的 tensor 在python中运行,需要C连续的变量,因此只有C连续的函数
contiguous()
1 | |
- 输出
1 | |
参考资料
- https://zhuanlan.zhihu.com/p/64551412
- https://www.cnblogs.com/peixu/articles/13455350.html
- https://www.cnblogs.com/sdu20112013/p/11981793.html
- https://zhuanlan.zhihu.com/p/59767914
- https://stackoverflow.com/questions/51304154/check-if-numpy-array-is-contiguous
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/numpy-tensor-contiguous/numpy-tensor-contiguous/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付