本文最后更新于:2024年5月11日 下午
变分自编码器 (Variational Auto-Encoders, VAE) 属于生成模型家族。VAE 的生成器能够利用连续潜在空间的矢量产生有意义的输出,它是包含隐变量的一种模型,通过潜在矢量探索解码器输出的可能属性。
简介
简单来讲,变分自编码器是可以和GAN相媲美的生成网络。我们可以输入一个低维空间的Z,映射到高维空间的真实数据。比如,生成不同样的数字,人脸等等。
什么是 VAE
- 变分自动编码器(AEV)就是用于生成模型,结合了深度模型以及静态推理。简单来说就是通过映射学习将一个高位数据,例如一幅图片映射到低维空间Z。与标准自动编码器不同的是,X和Z是随机变量。所以可以这么理解,尝试从P(X|Z)中去采样出x,所以利用这个可以生成人脸,数字以及语句的生成。
VAE 使用了类似 AE (Auto Encoder) 的结构,和最早出现的生成模型完成类似的任务,所以和二者有着千丝万缕的联系
与 GAN 的关系
-
变分自编码器与对抗生成网络类似,均是为了解决数据生成问题而生的。在 GAN 中,重点在于如何得出近似输入分布的模型。 VAE 尝试对可解耦的连续潜在空间中的输入分布进行建模。
-
变分自编码器同样的以特定分布的随机样本作为输入,并且可以生成相应的图像,从此方面来看其与对抗生成网络目标是相似的。但是变分自编码器不需要判别器,而是使用编码器来估计特定分布。总体结构来看与自编码器结构类似,但是中间传递向量为特定分布的随机向量。
-
假设,给定一系列猫的照片,我希望你能够对应我随机输入的一个n维向量,生成一张新的猫的照片,你需要怎么去做?对于GAN就是典型的深度学习时代的逻辑,你不清楚这个n维向量与猫的图片之间的关系,没关系,我直接拟合出来猫的图片对于n维向量的分布,通过对抗学习的方式获得较好的模型效果,这个方法虽然很暴力,但是却是有效的。
-
VAE则不同,他通过说我希望生成一张新的猫脸,那么这个n维向量代表的就是n个决定最终猫脸模样的隐形因素。对于每个因素,都对应产生一种分布,从这些分布关系中进行采样,那么我就可以通过一个深度网络恢复出最终的猫脸。
与 AE 的关系
- 在自编码器(Auto Encoder)结构中,通常需要一个输入数据,而且所生成的数据与输入数据是相同的。但是通常希望生成的数据具有一定程度的不同,这需要输入随机向量并且模型能够学习生成图像的风格化特点,因此在后续研究中以随机化向量作为输入生成特定样本的对抗生成网络结构便产生了。
- 在结构上,VAE 与自编码器相似。它也由编码器(也称为识别或推理模型)和解码器(也称为生成模型)组成。 VAE 和自编码器都试图在学习潜矢量的同时重建输入数据。但是,与自编码器不同,VAE 的潜在空间是连续的,并且解码器本身被用作生成模型。
- VAE即在AE的基础上引入变分的思想,使其能够进行数据生成。VAE建模着重考虑 $\hat{x}=g(z)$ 过程的有效性,其中 $z$ 为隐变量特征的分布。
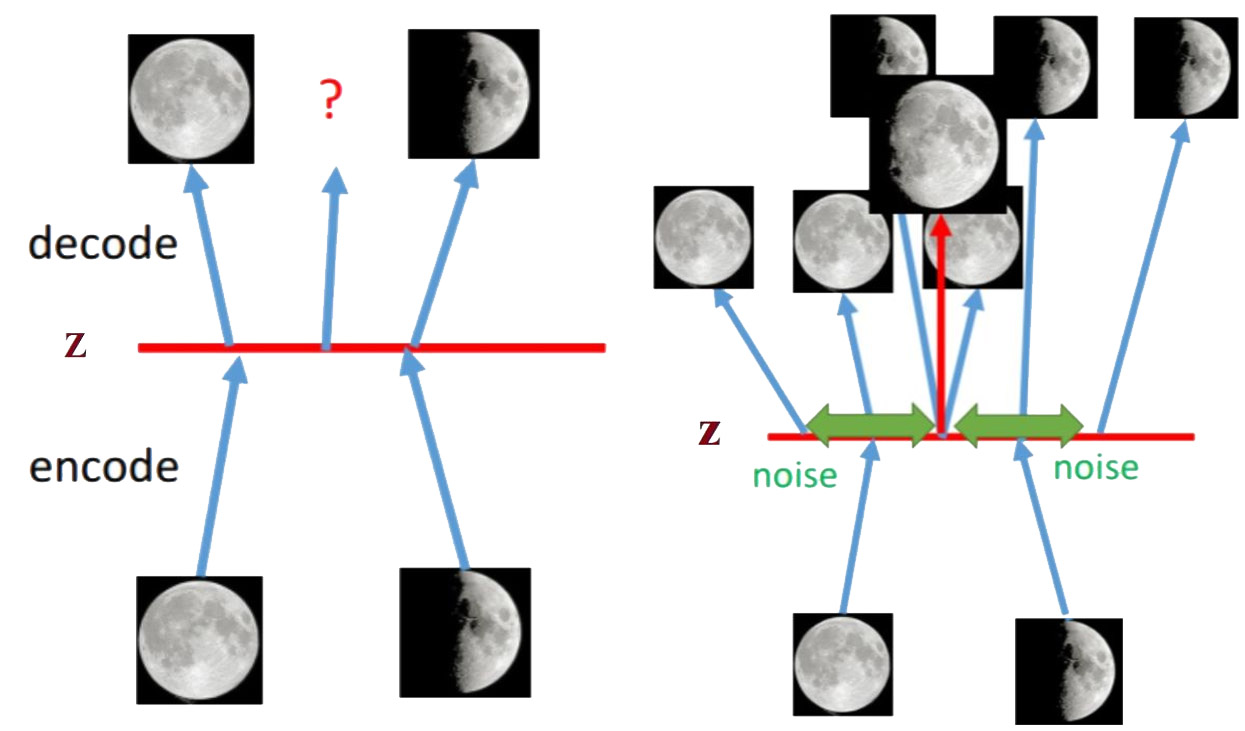
- AE的主要作用为特征提取或数据降维,即寻找合适的抽象特征z,可以使其代表x,如上图左侧,当我们微调z时,无法生成有效的月亮图片;而右侧的VAE过程,此时z为抽象特征的分布,当微调时,可以得到有效的月亮图片。
Auto-Encoder
- Auto encoder 是一种无监督算法,主要用于特征提取或数据降维。其思想非常简单,即输入特征 $x$ 经过 encoder 后抽象为 hidden layer $z$,再将 $z$ 经过 decoder 过程重新预测为 $\hat{x}$ 。其中encoder和decoder 的过程可以是 MLP/CNN/LSTM 等简单的神经网络。
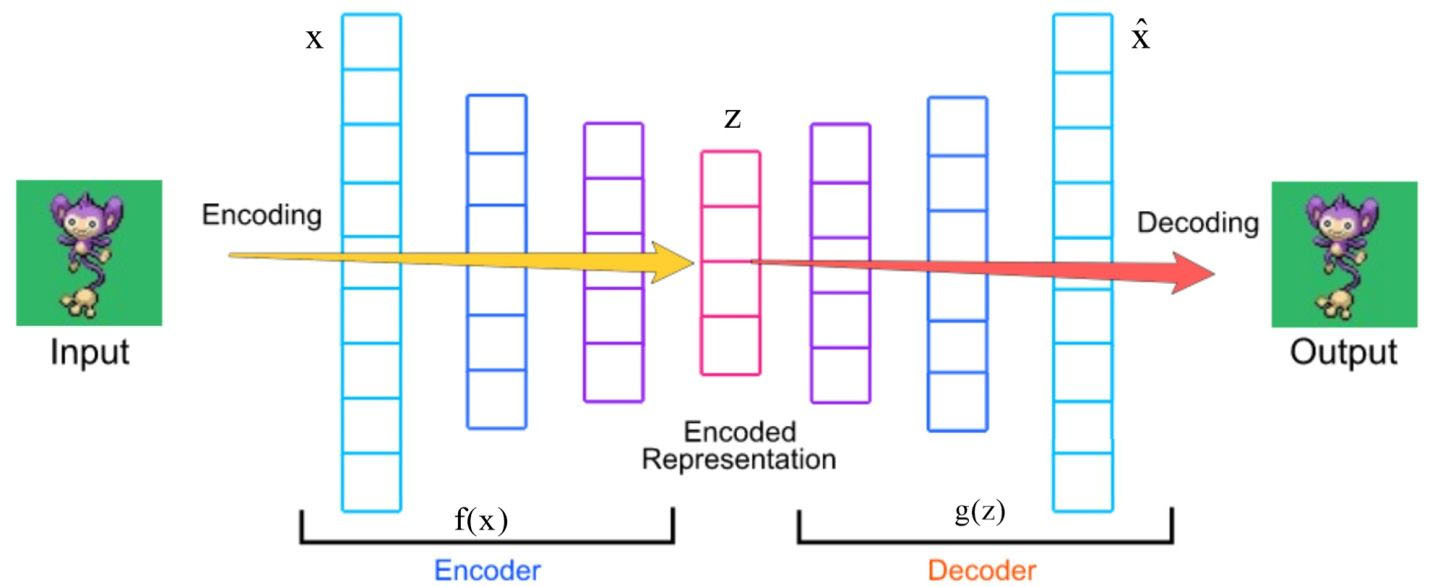
- Auto encoder的目的是提取抽象特征 $z$,其学习过程为最小化损失函数 $L(x,\hat{x})$ ,用于惩罚$\hat{x}$ 和 $x$ 之间的差异,假设使用平方损失,则有:
- 其中 $ i $ 代表第 $ i $ 个样本。 $ x_{i} $ 可以包含 $ \mathrm{n} $ 个特征,即 $ x_{i} \in \mathbb{R}^{n} $ 。
VAE原理
-
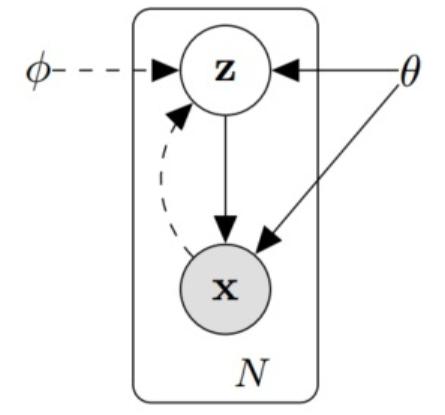
假设数据集为 $ X=\{ \mathrm {x} ^ { ( i ) } \} _ {i=1} ^ {N} $ ,是由连续或离散变量 $x$ 采样得到的 $N$ 个样本。
-
假设数据是由随机过程产生,且包含一个不可见的连续随机隐变量 $z$ ,如上图所示。那样本生成的过程分为两步:
- 从先验分布 $ P_{\theta}(\mathrm{z}) $ 随机采样生成 $ \mathrm{z}^{(i)} $
- 从条件概率分布 $ P_{\theta}(\mathrm{x} \mid \mathrm{z}) $ 中采样生成 $ \mathrm{x}^{(i)} $ 。但这个过程大部分都是隐藏的,难以求取。
-
本文中作者并末针对 $ p_{\theta}(\mathrm{z}) $ 进行建模,而是构建模型 $ Q_{\phi}(\mathrm{z} \mid \mathrm{x}) $ 来近似 $ P_{\theta}(\mathrm{z} \mid \mathrm{x}) $ 。作者使用 $ Q_{\phi}(\mathrm{z} \mid \mathrm{x}) $ 过程作为 encoder,即由每一个样本点 $x$,可以学出一个对应的隐层分布 $z$(注意,此处为每一个样本均可学出其对应的隐层 $z$ 分布);并使用 $P_θ(x|z)$ 作为 decoder 过程进行解码,实现模型生成。
VAE 结构
-
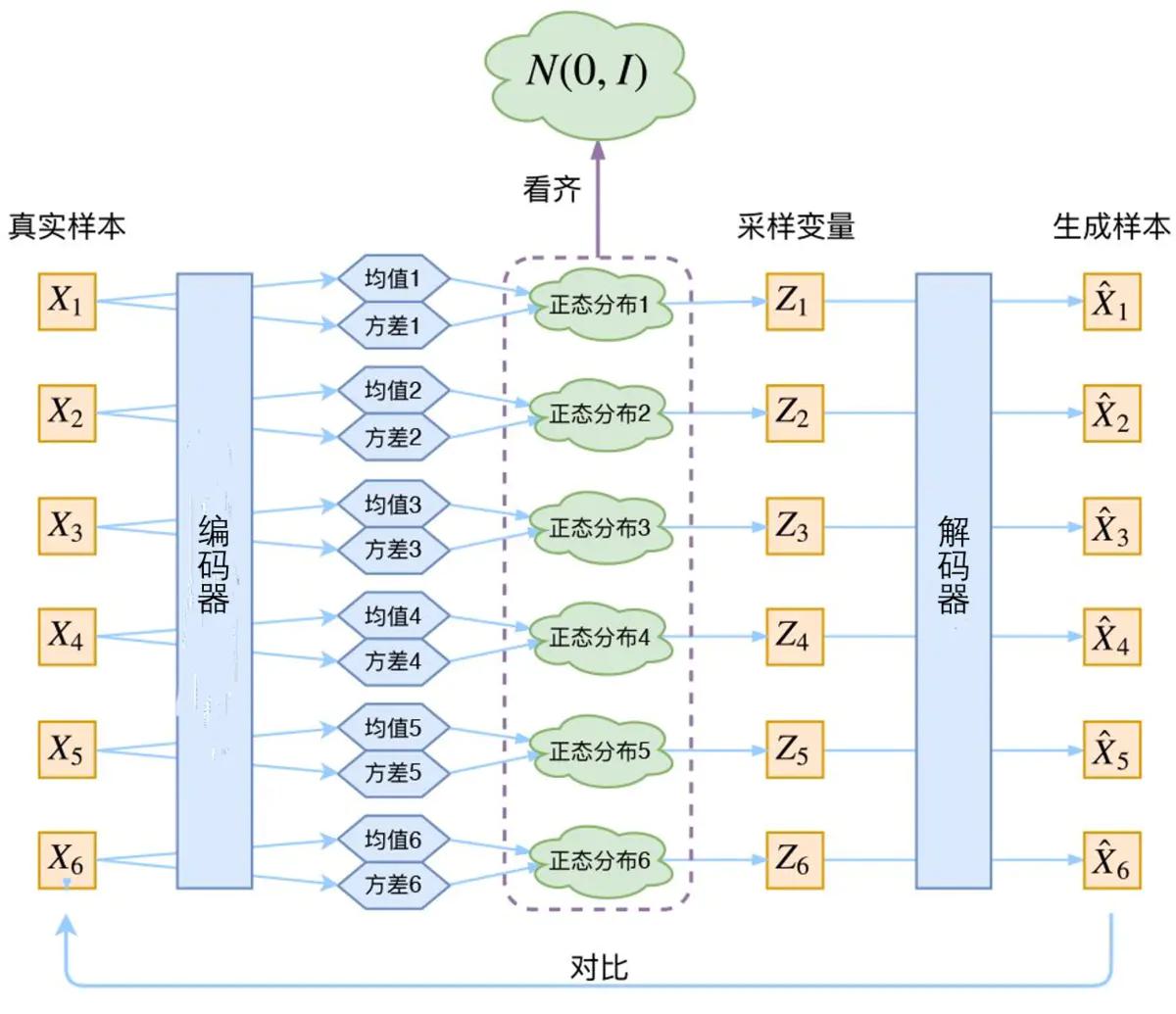
VAE对每一个样本 $X_k$ 匹配一个高斯分布,隐变量 $Z$ 就是从高斯分布中采样得到的。对$K$ 个样本来说,每个样本的高斯分布假设为 $\mathcal N(\mu_k,\sigma_k^2)$ ,问题就在于如何拟合这些分布。VAE构建两个神经网络来进行拟合均值与方差。即 $\mu_k=f_1(X_k),log\sigma_k^2=f_2(X_k)$,拟合 $log\sigma_k^2$ 的原因是这样无需加激活函数。
-
此外,VAE让每个高斯分布尽可能地趋于标准高斯分布 $\mathcal N(0,1)$。这拟合过程中的误差损失则是采用KL散度作为计算,下面做详细推导。
VAE 确定方向的原因
- 原始样本数据 $x$ 的概率分布::
$$
x \sim P_{\theta}(x) \tag1
$$
其中,$θ$ 表示模型参数。
- 在机器学习中,为了执行特定的推理,希望找到输入 $x$ 和潜变量 $z$ 之间的联合分布 $P_θ(x,z)$。潜变量是对可从输入中观察到的某些属性进行编码。如在人脸数据中,这些可能是面部表情,发型,头发颜色,性别等。
- $ P_{\theta}(x, z) $ 实际上是输入数据及其属性的分布。 $ P_{\theta}(x) $ 可以从边缘分布计算:
$$
P_{\theta}(x)=\int P_{\theta}(x, z) d z \tag2 \label2
$$
- 考虑所有可能的属性,最终得到描述输入的分布。在人脸数据中,利用包含面部表情,发型,头发颜色和性别在内的特征,可以恢复描述人脸数据的分布。
- 问题在于该方程式没有解析形式或有效的估计量。因此,通过神经网络进行优化是不可行的。
- 使用贝叶斯定理,可以找到方程式 $\ref{2}$ 的替代表达式:
$$
P_{\theta}(x)=\int P_{\theta}(x \mid z) P(z) d z \tag3 \label3
$$
- 其中, $ P(z) $ 是 $ z $ 的先验分布。它不以任何观察为条件。如果 $ z $ 是离散的并且 $ P_{\theta}(x \mid z) $ 是高斯分 布,则 $ P_{\theta}(x) $ 是高斯分布的混合。如果 $ z $ 是连续的,则高斯分布 $ P_{\theta}(x) $ 无法预估。
- 在实践中,如果尝试在没有合适的损失函数的情况下建立近似 $P_θ(x|z)$ 的神经网络,它将忽略 $z$ 并得出平凡解, $ P_{\theta}(x \mid z)=P_{\theta}(x) $ 。因此,公式 $\ref{3}$ 不能提供 $ P_{\theta}(x) $ 的良好估计。公式 $\ref{2}$ 也 可以表示为:
$$
P_{\theta}(x)=\int P_{\theta}(z \mid x) P(x) d z \tag4
$$
- 但是, $ P_{\theta}(z \mid x) $ 也难以求解。VAE 的目标是找到一个可估计的分布,该分布近似估计 $ P_{\theta}(z \mid x) $ , 即在给定输入 $ x $ 的情况下对潜在编码 $ z $ 的条件分布的估计。
VAE 推导过程
- 原始样本数据 $x$ 的概率分布可表示为:
$$
P(x)=\int_{Z} P(z) P(x \mid z) d z \tag5
$$
- 假设 $z$ 服从标准高斯分布 $N(0,1)$,先验分布 $P(x|z)$ 是高斯的,即 $x|z \sim N(\mu(z),\sigma(z))$。$\mu(z)$ 、$\sigma(z)$ 是两个函数, 分别是 $z$ 对应的高斯分布的均值和方差,则 $P(x)$ 就是在积分域上所有高斯分布的累加:
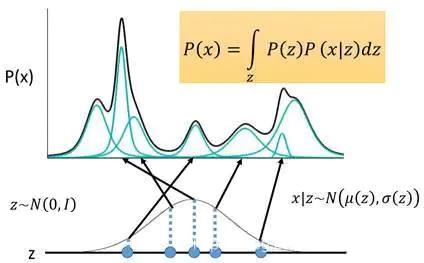
- 由于 $P(z)$ 是已知的,$P(x|z)$ 未知,所以求解问题实际上就是求 $\mu$ , $\sigma$ 这两个函数。最开始的目标是求解 $P(x)$,且希望 $P(x)$ 越大越好,这等价于求解关于 $x$ 最大对数似然:
$$
L=\sum_{x} \log P(x) \tag6
$$
- 为了使 $ P(z \mid x) $ 易于处理,VAE 引入了变分推断模型 (编码器) :
$$
Q(z \mid x) \approx P(z \mid x) \tag7
$$
- 可很好地估计 $P(z|x)$。它既可以参数化又易于处理。 可以通过深度神经网络优化参数来优化 $Q(z|x)$。 通常,将 $Q(z|x)$ 选择为多元高斯分布:
$$
Q(z|x)=N(z;μ(x),diag(σ(x)^2)) \tag8
$$
-
均值 $ μ(x)$ 和标准差 $σ(x)$ 均由编码器神经网络使用输入数据计算得出。对角矩阵表示 $ z$ 中的元素间是相互独立的。
-
而 $logP(x)$ 可变换为:
- 到这里我们发现,右边第二项 $\int_z q(z|x)log(\dfrac{q(z|x)}{P(z|x)})dz$ 其实就是 $q$ 和 $P$ 的KL散度,即$KL(q(z|x)\;||\;P(z|x))$,因为 KL散度是大于等于 0 的,所以上式进一步可写成:
$$
\log P(x) \geq \int_{z} q(z \mid x) \log \left(\frac{P(x \mid z) P(z)}{q(z \mid x)}\right) d z \tag{10}
$$
- 原式也可表示成:
$$
\log P(x)=L_{b}+K L(q(z \mid x) | P(z \mid x)) \tag{11}
$$
- 为了让 $logP(x)$ 越大,目的就是要最大化它的这个下界 ELBO $L_b$
为什么要引入q(z|x),这里的q(z|x)可以是任何分布?
实际上,因为后验分布 $P(z|x)$ 很难求(intractable),所以才用 $q(z|x)$ 来逼近这个后验分布。在优化的过程中发现,首先 $q(z|x)$ 跟 $logP(x)$ 是完全没有关系的,$logP(x)$ 只跟 $P(z|x)$ 有关,调节$q(z|x)$ 是不会影响似然也就是 $logP(x)$ 的。所以,当固定住 $P(x|z)$ 时,调节 $q(z|x)$ 最大化下界$L_b$,KL则越小。当 $q(z|x)$ 与不断逼近后验分布 $P(z|x)$ 时,KL散度趋于为0,$logP(x)$ 就和 $L_b$ 等价。所以最大化 $logP(x)$ 就等价于最大化 $L_b$。
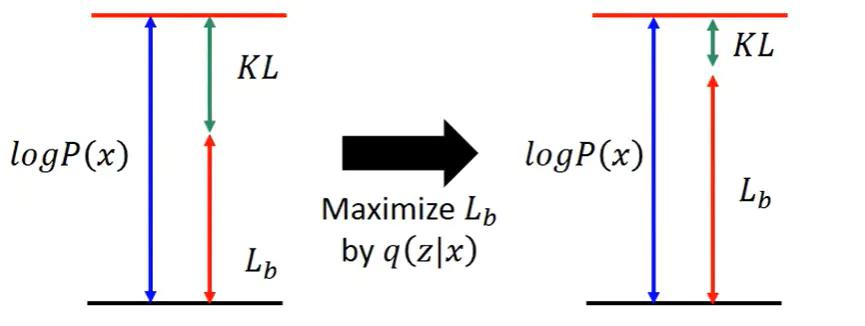
最大化 $L_b$
- 回顾 $L_b$:
- 显然,最大化 $L_b$ 就是等价于最小化 $KL(q(z|x);||;P(z))$ 和最大化 $E_{q(z|x)}[log(P(x|z))]$。
第一项,最小化KL散度
- 前面已假设了 $P(z)$ 是服从标准高斯分布的,且 $q(z∣x)$ 是服从高斯分布$\mathcal N(\mu,\sigma^2)$,于是代入计算可得:
- 化简得到
- 对上式中的积分进一步求解:
- $\dfrac{1}{\sqrt{2\pi\sigma^2}}e^{\frac{-(x-\mu)^2}{2\sigma^2}}$ 实际就是概率密度 $f(x)$,而概率密度函数的积分就是1,所以积分第一项等于 $-log\sigma^2$;
- 又因为高斯分布的二阶矩就是 $E(X^2)=\int x^2f(x)dx=\mu^2+\sigma^2$ ,正好对应积分第二项;
- 积分第三项相当于计算标准化后的正态分布 $E(X^2)=\int x2f(x)dx=\mu2+\sigma^2=1$,算上负号后值为-1。
- 最终化简得到的结果如下:
第二项,最大化期望
- 也就是表明在给定 $q(z|x)$(编码器输出)的情况下 $P(x∣z)$(解码器输出)的值尽可能高
- 第一步,利用 encoder 的神经网络计算出均值与方差,从中采样得到 $z$,这一过程就对应式子中的$q(z∣x)$
- 第二步,利用 decoder 的 $N$ 计算 $z$ 的均值方差,让均值(或也考虑方差)越接近 $x$,则产生 $x$ 的几率 $logP(x|z)$ 越大,对应于式子中的最大化 $logP(x∣z)$ 这一部分
重参数技巧
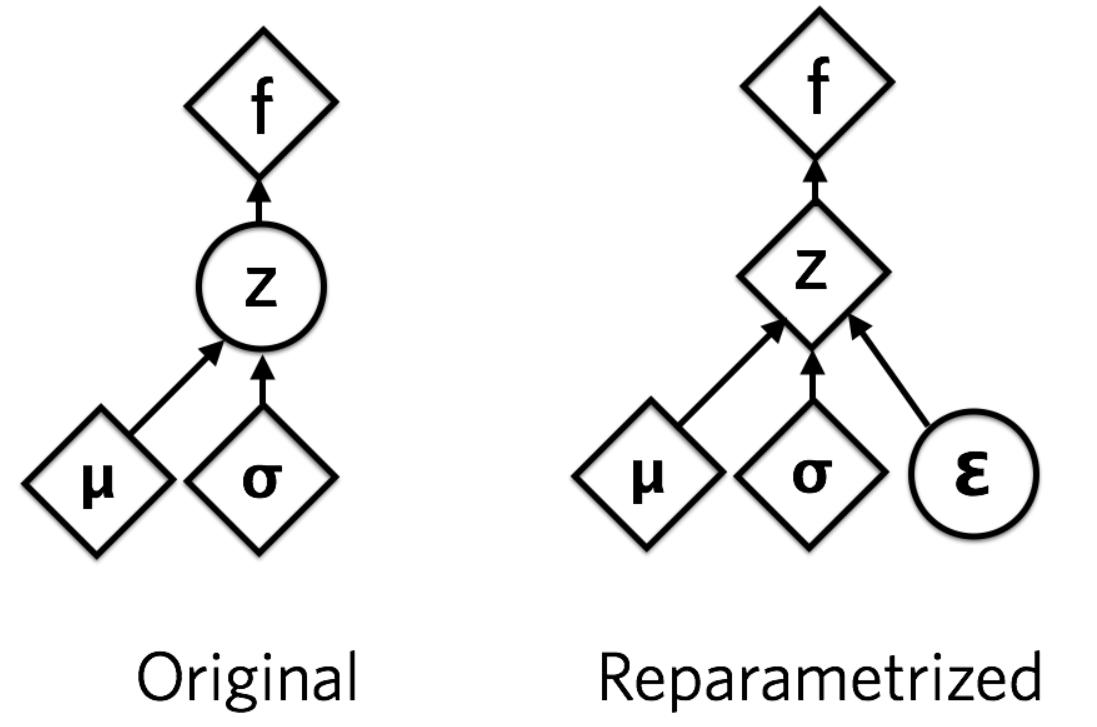
- 最后模型在实现的时候,有一个重参数技巧,就是想从高斯分布 $\mathcal N(\mu,\sigma^2)$ 中采样 $Z$ 时,其实是相当于从 $\mathcal N(0,1)$ 中采样一个 $\epsilon$,然后再来计算 $Z=\mu+\epsilon\times\sigma$。这么做的原因是,采样这个操作是不可导的,而采样的结果是可导的,这样做个参数变换,$Z=\mu+\epsilon\times\sigma$ 这个就可以参与梯度下降,模型就可以训练了
- 那么我们从分布 $N ( 0 , I )$ 采样 $ \varepsilon$,这个就是从已知分布采样了,不需要反向传播来优化。
- 所以我们先从分布 $N(0,I)$采样 $\varepsilon$
- 然后把 $\varepsilon$ 变化到 $z$,即 $z = ε ⋅ σ + μ $
- 如果 $ε$ 和 $σ$ 以矢量形式表示,则 $εσ$ 是逐元素乘法。 这样令采样好像直接来自于潜空间。 这项技术被称为重参数化技巧。
- 重参数计算图的形式:
- 整体计算流程:
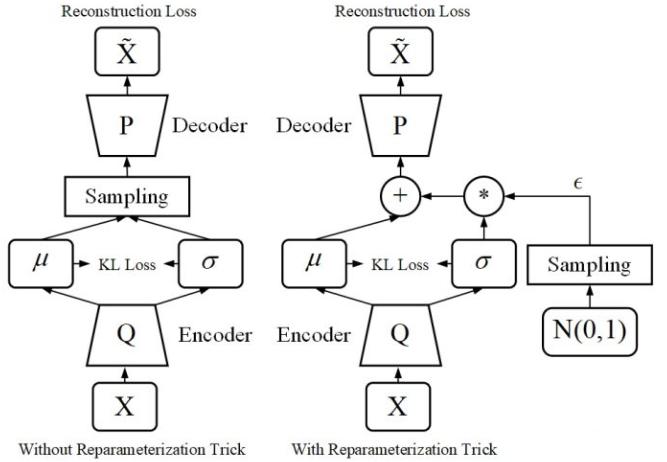
1 | |
- 训练流程

实验结果
- 论文中基于 MNIST 和 Frey Face 做了实验

原始论文
### 参考资料- https://zhuanlan.zhihu.com/p/450516324
- https://www.jianshu.com/p/94d68a03c13e
- https://blog.csdn.net/weixin_43135178/article/details/115412487
- https://blog.csdn.net/weixin_40955254/article/details/81415834
- https://www.jianshu.com/p/98a9c48e9c7f
- https://zhuanlan.zhihu.com/p/161277762
- https://blog.csdn.net/doyouseeman/article/details/108647804
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/generation/vae/vae/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付