本文最后更新于:2024年5月11日 下午
关于深度学习的算力、计算量存在很多单位,本文记录相关内容。
概念
算力
指计算设备(GPU、CPU、NPU等)完成计算的能力大小,一般评价指标为在单位时间内完成的运算次数
计算量
指模型推断过程中需要的运算量,一般用来评价模型规模以及推断运行时间
常用单位
| 单位类型 | 英文缩写 | 英文 | 含义 |
|---|---|---|---|
| 芯片速度类 | OPS | operations per second | 每秒处理次数 (S大写,表示 second),通俗是对INT8类型的操作次数,整型默认省略。 |
| 芯片速度类 | FLOPS | Floating point number operations per second | 每秒处理浮点数次数(S大写,表示 second),通常是FP32,浮点着重强调。 |
| 芯片速度类 | TOPS | Tera operations per second | 每秒处理的万亿次数 $10^{12}$(S大写,表示 second) |
| 芯片速度类 | TFLOPS | Tera Floating point number operations per second | 每秒处理浮点数的万亿次数 $10^{12}$(S大写,表示 second) |
| 芯片速度类 | FLOPs | Floating point number operations | 模型推理需要处理浮点操作的次数(S小写,表示复数) |
| 模型体量类 | TFLOPs | Tera Floating point number operations | 模型推理需要处理浮点操作的万亿次数 $10^{12}$(S小写,表示复数) |
- 最常用也容易混淆的几个单位:TOPS 和 FLOPS,及FLOPs
1、最大的混淆点,上述三个名词是两种东西,注意“S/s”的大小写。TOPS和FLOPS指的是每秒的计算量,算是速度方面的,用在芯片算力性能上。FLOPs指的是深度学习模型自身的计算量,算是体量方面的,用在深度学习模型本身参数计算量上。
2、针对算力速度方面的TOPS和FLOPS,其中OPS指的是每秒处理次数,但通常是默认对INT8整型数的处理次数(INT8省略不写),加上FL后FLOPS指的是对FP32浮点数的处理次数。
3、仍然是针对算力速度方面的TOPS和FLOPS,这里的T指的是量级(Tera ,万亿,10^12),同理TFLOPS专门指每秒对浮点数处理的达到多少万亿次数。
- 下图为nvidia-A100/H100部分算力信息,可对比TOPS/TFLOPS区别。
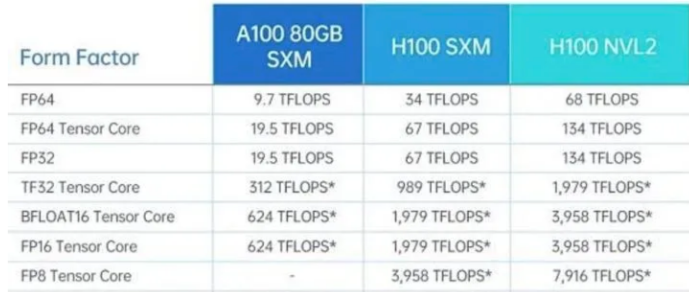
- 对于描述模型算力的 TFLOPs
| 网络 | 运算量 |
|---|---|
| AlexNet | 对于AlexNet处理224*224的图像,需要1.4G FLOPS |
| ResNet-152 | 对于224*224的图像,ResNet-152需要22.6G FLOPS |
算力单位量级变换
| 单位 | 描述 |
|---|---|
| 1 MOPS = 10^6 FLOPS | 一个MFLOPS(megaFLOPS)等于每秒一百万 (=10^6)次的浮点运算, |
| 1 GOPS = 10^9 FLOPS | 一个GFLOPS(gigaFLOPS)等于每秒十亿 (=10^9)次的浮点运算,十亿(部分地方可能会用B,billion,十亿) |
| 1 TOPS = 10^12 FLOPS | 一个TFLOPS(teraFLOPS)等于每秒一万亿 (=10^12)次的浮点运算,(1太拉) |
| 1 PFLOPS = 10^15 FLOPS | 一个PFLOPS(petaFLOPS)等于每秒一千万亿 (=10^15) 次的浮点运算 |
| 1 EFLOPS = 10^18 FLOPS | 每秒一百京(=10^18)次的浮点运算。 |
| 1 ZFLOPS = 10^21 FLOPS | 等于每秒十万京(=10^21)次的浮点运算。 |
MACs
MACs (Multiply ACcumulate operations)指 乘加累积操作次数,有时也用MAdds(Multiply-Add operations)表示,是微处理器中的特殊运算。MACs也可以为是描述总计算量的单位,但常常被人们与FLOPs概念混淆(Python第三方包Torchstat、Thop等),实际上一个MACs包含一个乘法操作与一个加法操作,因此1个MACs约等价于2个FLOPs,即 1 MACs = 2 FLOPs ,$1GMACs = 10^9 MACs$。
科学计算单位换算
| 10^15 | 拍[它] | P | peta | |
|---|---|---|---|---|
| 10^12 | 太[拉](万亿) | T | tera | trillion 万亿 |
| 10^9 | 吉[咖](十亿) | G | giga | billion 十亿 |
| 10^6 | 兆(百万) | M | mega | million 百万 |
| 10^3 | 千 | k | kilo |
深度学习模型 FLOPs 推导与估算
FC Layer
一个全连接层的神经网络计算的过程可以看成是两个矩阵进行相乘的操作,忽略掉激活函数(activation) 部分的计算,假设输入矩阵是$A$、矩阵大小是$H\times I$,全连接层的参数矩阵是$B$, 矩阵大小是$I\times W$, 全连接层矩阵计算过程实际就是:
$$
Y=AB
$$
结果矩阵$Y$中的每个元素都是经过$I$ 次乘法和$I-1$次加法,因此FC层的FLOPs公式就是:
$$
H\times W\times(I+(I-1))=H\times W\times(2I-1)
$$
如果忽略这个常数项或者考虑加入bias,即$Y$中每一个元素需要额外进行一次加法,则可以将公式
中-1去掉。
$$
H\times W\times2I
$$
CNN Layer
一个卷积神经网络(CNN)进行的计算主要来自卷积层,忽略掉激活函数(activation)部分计算,分析每一层卷积输出结果矩阵中每个值都经过对卷积核的每个元素都进行一次“乘加累积”(MACs)运算操作 (等价2倍FLOPs)。因此假设这一层输出的结果矩阵维度是 $H\times W$、输出通道数 (卷积核的个数) 是$Out_Chanel$,卷积层的卷积核的大小 (kernel size) 是$K$,输入卷积层前通道数是$In_Chanle$,则CNN每一层的计算量 (FLOPs) 有如下公式:
$$
H\times W\times Out_Chanel\times(2\times K^2-1)\times In_Chanel
$$
为什么括号里是$(2\times K^2\times In_Chanel-1)$ 有一个 -1,是因为仔细分析这里每个卷积核, 实际上进行了$K2$次乘法,$K2-1$次加法操作 (n个数相加,进行n-1次加法)。如果忽略这个常数项或者考虑加入bias,则-1去掉后的公式为:
$$
H\times W\times Out_Chanel\times2\times K^2\times In_Chanel
$$
LSTM Layer
对于一个循环神经网络层(LSTM\RNN\GRU),忽略掉激活层等操作只关注矩阵之间计算量,分析一下每层LSTM的计算量(FLOPs),假设词向量的维度(embedding dimension)是E,隐藏层的维度是H(hidden state dimension)、即LSTM层有多少个cell,则计算LSTM层的FLOPs有以下公式:
$$
(E+H)\times H\times4\times2
$$
公式中的4是指LSTM层的4个非线性变换(3个门+1个tanh)。
统计 Pytorch 模型运算量
核心使用 thop 的 profile 方法计算模型 FLPOs
1 | |
参考资料
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/deploy/cal-aba/cal-aba/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付