defget_args() -> Namespace: """Get command line arguments.
Returns: Namespace: List of arguments. """ parser = ArgumentParser() parser.add_argument("--model", type=str, default="fastflow", help="Name of the algorithm to train/test") parser.add_argument("--config", type=str, default="configs/model/fastflow_raw.yaml", help="Path to a model config file") parser.add_argument("--log-level", type=str, default="INFO", help="<DEBUG, INFO, WARNING, ERROR>")
args = parser.parse_args() return args
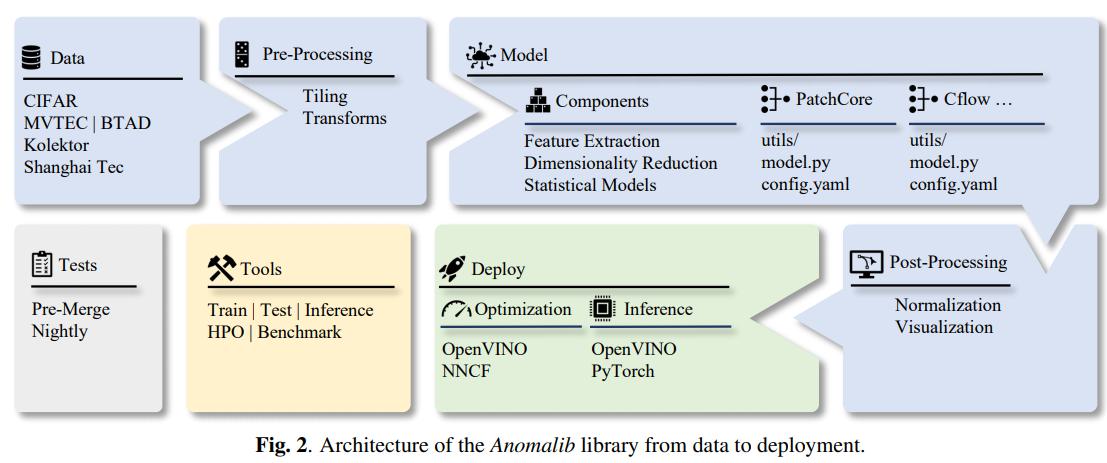
工具会自动执行数据预处理、加载、训练、测试、评估等操作
1 2 3 4 5 6 7 8 9 10 11
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3] Testing DataLoader 0: 0%| | 0/141 [00:00<?, ?it/s]QStandardPaths: XDG_RUNTIME_DIR not set, defaulting to '/tmp/runtime-root' failed to get the current screen resources Testing DataLoader 0: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 141/141 [00:39<00:00, 3.54it/s] ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── Test metric DataLoader 0 ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── image_AUROC 1.0 image_F1Score 0.994535505771637 pixel_AUROC 0.9919205904006958 pixel_F1Score 0.556056797504425
在输出路径中保存了输出测试图像和模型权重
模型部署
当选好模型后需要独立部署时,需要在系统安装 anomalib 工具包
可以省去很多繁琐的流程自己构建模型、预处理流程、加载模型流程建立 Controller
例如 Patchcore 的模型加载可以简化为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
defget_model(self, config_path, model_path): config = OmegaConf.load(config_path) model = Patchcore( input_size=tuple(config.dataset.image_size), backbone=config.model.backbone, layers=config.model.layers, pre_trained=False, coreset_sampling_ratio=config.model.coreset_sampling_ratio, num_neighbors=config.model.num_neighbors, ) weight = load(model_path) print(f"loading Patchcore model from path {model_path}.") load_res = model.load_state_dict(weight["state_dict"], strict=False) print(f"Patchcore model loaded: {load_res}") model.threshold = model.image_threshold.value.cpu() return model