本文最后更新于:2024年5月11日 下午
本文记录异常检测 2023 年的一篇工作 EfficientAD。
EfficientAD
基本信息
| 项目 | 内容 | 备注 |
|---|---|---|
| 方法名称 | EfficientAD | |
| 论文题目 | EfficientAD: Accurate Visual Anomaly Detection at Millisecond-Level Latencies[^31] | |
| 论文连接 | https://arxiv.org/pdf/2303.14535v2.pdf | |
| 开源代码 | https://github.com/nelson1425/EfficientAD | |
| 发表时间 | 2023.06.28 | |
| 方法类别 | 深度学习 -> 基于特征 -> 教师学生网络 深度学习 -> 基于重构 -> 自动编码器 |
|
| Detection AU-ROC | 99.8%-98.8% | |
| Segmentation AU-ROC | - 96.8% | |
| Segmentation AU-PRO | - 96.5% | |
| FPS | 614 | |
| 核心思想 | 1. 在教师学生网络架构上提出更高效的网络, 可以快速推断得出异常检测结果 2. 高效地结合了自动编码器和教师学生网络的结果 3. 小网络速度快, 最快每秒处理 600+ 图像 |
高效的 Patch 特征提取
常用的异常检测特征提取网络都是 ImageNet 预训练的 backbone, 典型的是 WideResNet-101, 文章使用四次卷积的网络作为特征提取器
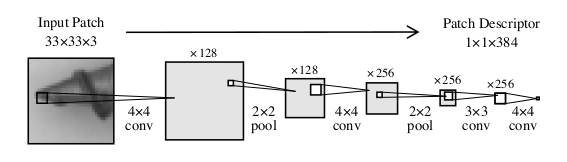
输入 Patch 为 $33\times 33$, 即每组输出描述一个 patch 的特征, 网络被称为 patchd escription network (PDN), 这个小网络可以在 1ms 内提取 $256\times 256$ 的图像特征. 该网络的训练使用的就是 WideResNet-101 进行蒸馏, 训练数据为 ImageNet, 损失为 MSE.
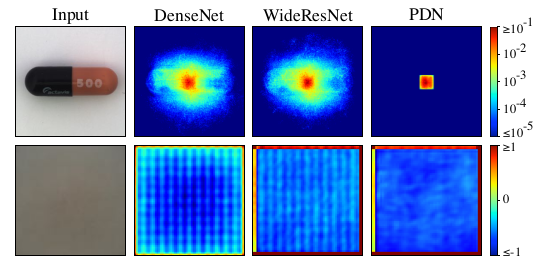
该 PDN 相比于之前的预训练网络还有一个优势, 预训练网络将整幅图像作为输入, 产生的异常特征很有可能外溢到图像的其他区域中, 而 PDN 则会将异常的影响限制在自己的感受野之内, 这会使得网络具有更精准的定位能力.
轻量级教师-学生网络
为了提取异常特征, 文章使用了教师-学生网络架构, 只是该架构中教师网络是上一步训练得到的 PDN 网络. 同样学生网络也用 PDN 结构.
在训练学生网络时, 如果使用过多的训练图像, 会使得学生模仿教师对异常数据的行为, 这样不利于异常检测;而故意减少训练图像的数量又会使得学生没有学到正常图像的重要信息. 我们的目标是既需要学生学会正常图像特征, 又不能产生构建异常特征的能力.
为此, 文章设计了类似在线困难样本挖掘的实现思想, 限制学生网络梯度回传的区域, 仅在学生没有很好模仿老师行为的区域上进行梯度回传.
考虑教师网络 $T$, 学生网络 $S$, 训练数据 $I$, 得到对应两组特征 $T(I)~\in~\mathbb{R}^{C\times W\times H}, S(I)~\in~\mathbb{R}^{C\times W\times H}$ , 计算二者的平方误差: $$ D_{c,w,h}=(T(I)_{c,w,h}-S(I)_{c,w,h})^2. $$给定一个超参 $p_{hard} \in[0,1]$ 作为一个分位数, 从 $D_{c,w,h}$ 选择该分位数对应的数值 $d_{hard}$, 仅用 $D_{c,w,h}$ 中不小于 $d_{hard}$ 的部分用于梯度回传.
这里当 $p_{hard}$ 为 0 时则该 loss 退化为普通的 MSE
文章中设置 $p_{hard} = 0.999$, 表示仅用 千分之一的结果用于梯度回传, 原始用意是每个维度上使用 10% 的数据.
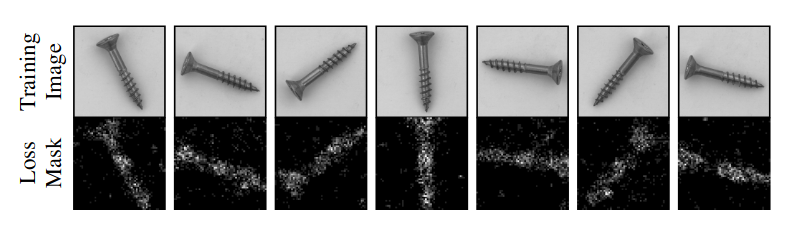
上图是一组以此法得到的 Loss Mask.
在推断过程中, 异常得分图直接将平方损失在通道维度求平均得到:
$$
M_{w,h}=C^{-1}\sum_{c}{D_{c,w,h}}
$$
文章也同时为学生模仿教师异常区域的行为加入了惩罚, 初衷是由于教师网络接触过 ImageNet, 想把该数据集的信息应用到学生网络身上, 文章将 ImageNet 中任意一幅图 $P$ 作为正则项的输入, 将正则加入到 Loss 中:
作者认为:这种惩罚会阻碍学生将对老师的模仿推广到分布外的图像.
逻辑异常检测
异常又很多种情况, 教师学生网络适合检测局部区域的异常, 而自编码器善于检测逻辑上的异常, 因此文章为了同时检测所有异常在教师学生网络之外, 使用自动编码器来学习训练图像的逻辑约束并检测对这些约束的违反.
自编码器用 $A$ 表示, 在编码过程使用卷积层完成, 在解码时使用差值上采样, 得到 $A(I)~\in~\mathbb{R}^{C\times W\times H}$, 训练损失为: $$ L_{\mathrm{AE}}=(CWH)^{-1}\sum_{c}\|T(I)_{c}-A(I)_{c}\|_{F}^{2} $$相比于仅推断Patch 数据的学生网络, 自编码器需要编解码整张图像, 文章中用64个隐变量进行编码, 这种情况下, 当图像中出现逻辑上的异常时解码器很难还原回原始图像. 自编码器的重建在普通图像上也存在缺陷, 因为自动编码器通常难以重建细粒度的模式.
教师网络输出的特征与自编码器输出的特征风格不一样, 直接对比二者容易产生过检, 文章将学生网络作为“中间人”, 学生网络蒸馏教师网络得到与教师网络可以对比的输出, 同时叠加一组输出用于与自编码器输出结果对比, 我们把额外的输出叫做 $S’$, 那么对应输出就是 $S’(I)$, 其训练过程相当于蒸馏自编码器:
$$ \begin{aligned}L_{\mathrm{STAE}}=(CWH)^{-1}\sum_{c}\|A(I)_{c}-S'(I)_{c}\|_{F}^{2}\end{aligned} $$这样学生网络可以配合教师网络和自编码器实现细节和逻辑上的异常检测, 下图为论文中展示的例子.

左右两组流程分别展示细节异常和逻辑异常的检测过程.
- 左图为细节异常, 线上多了一个金属片, 然而整幅图像在逻辑上没有问题, 因此自编码器无法看到精细的内容, 没有察觉到异常;而教师学生网络的组合可以看到较细粒度的问题, 发觉出了异常点
- 右图为逻辑异常, 正常图像有一条线, 该图有两条. 这种情况下教师网络由于其卷积特性, 关注局部信息, 无法知道图里多了一根线, 因此没有发觉其中的异常;但自编码器恢复不出来有两根线的图像, 因此发觉了逻辑上的错误
异常图归一化
至此我们有教师学生网络和自编码器两组异常图了, 但是二者在合并时必须归一化到同样的尺度, 否则一幅图上的噪声很可能将另一幅图的正确检测结果掩盖掉. 为了估计噪声尺度, 文章使用训练数据中的验证集找到一组鲁棒的线性变换作为两组异常图的后处理方法.
经过后处理的异常图尺度统一, 可以对比叠加.
源码解析
代码来源
源码仓库: https://github.com/nelson1425/EfficientAD
数据集
EfficientAD 需要用到 ImageNet 数据集蒸馏初始的教师网络,也会用到异常检测数据集 MVTec AD 数据
这里我下载了飞桨的 ImageNetMini 和 MVTec AD 数据集
将 ImageNet 数据集随机划分到40个文件夹中,放到代码根目录 imagenet_train 文件夹中
将 MVTec 数据放到根目录 mvtec_anomaly_detection 文件夹中
文件结构
1 | |
环境依赖
| 环境 | 版本 | 备注 |
|---|---|---|
| Python | 3.10.+ | |
| torch | 1.13.0 | |
| torchvision | 0.14.0 | |
| tifffile | 2021.7.30 | |
| tqdm | 4.56.0 | |
| scikit-learn | 1.3.2 | |
| scipy | 1.7.2 | readme 版本错误 |
| tabulate | 0.8.7 | |
| Pillow | 10.2.0 | readme 版本错误 |
预训练
由于官方开放了预训练模型,该步骤可省略,核心代码在
pretraining.py文件中
预训练使用 ImageNet 数据集,首先配置 ImageNet 数据位置
加载特征提取模型(默认 Wide_ResNet101_2),提取下采样 4 × 和 8 × 的特征
在 ImageNet 数据集上创建 Dataloader
在图像特征上统计得到特征均值方差用于归一化
随后用特征提取模型蒸馏教师网络,过程中使用统计特征的均值方差归一化特征
训练 60000 步后保存教师网络
异常检测
有了预训练模型后可以进行异常检测模型训练了,核心代码在 efficientad.py 文件中
配置好 ImageNet 数据路径和 MVTec 数据路径就可以开始训练了
-
准备数据
-
计算训练数据的特征均值方差用于归一化
-
蒸馏训练学生网络,同时加入防止泛化的正则
-
训练 AE 网络
-
训练另一部分学生网络蒸馏 AE 的结果
在 MVTec screw 类别上EfficientAD-S 测试结果 Image AUC 97.233% (Small)
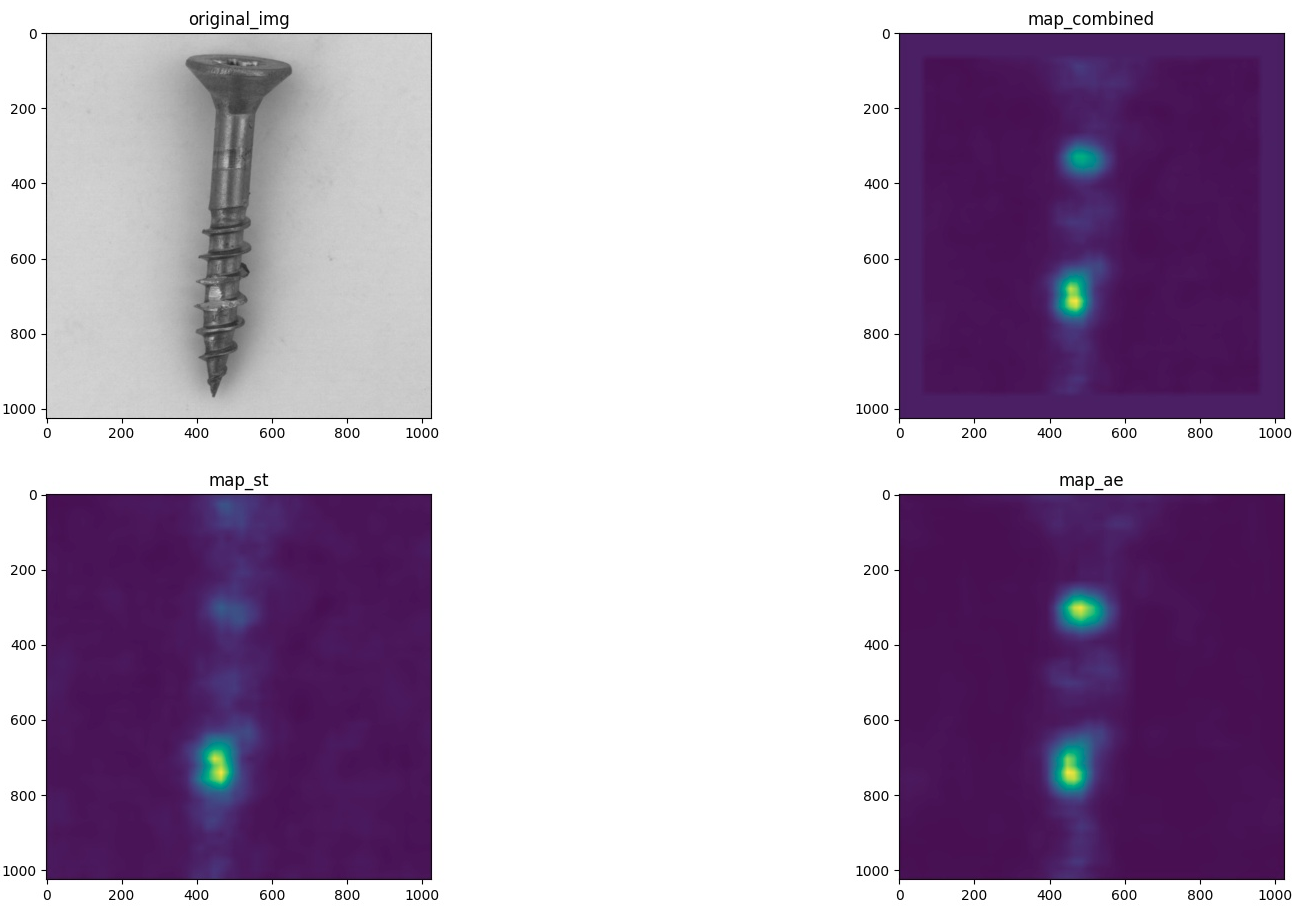
性能测试
benchmark.py 文件为模型性能测试代码
构建了与实际模型相同架构的随机初始化的模型,完整复现了异常检测流程
执行 2000 次计算取后 1000 次运行时间的平均值作为性能结果
- 本机 3080 显卡测试 EfficientAD-M 模型 256*256 单张图像平均运行时间 6.6ms
- 本机 3080 显卡测试 EfficientAD-S 模型 256*256 单张图像平均运行时间 3.1ms
原始论文
参考资料
- https://arxiv.org/pdf/2303.14535v2.pdf
- https://www.mvtec.com/company/research/datasets/mvtec-ad
- https://aistudio.baidu.com/datasetdetail/89857
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/anomaly-detection/efficientad/efficientad/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付