本文最后更新于:2024年5月11日 下午
Halcon 支持自动并行和手动并行功能,本文记录相关文档的学习笔记。
22.11.0.0 版本 HDevelop 并行编程的相关内容。
文档名称: parallel_programming.pdf
简介
Introduction
Halcon 同时为用户提供了自动并行化和手动并行化。
自动并行化一般情况下会自动运行,用户甚至不太需要关注这部分实现,Halcon 会自动确定当前硬件环境和运算资源,实现并行运算。细节文档可以查看 Programmer’s Guide 文档的 2.1 节。
手动并行化更加复杂,因此需要一些更多的专业知识。本文档描述了基于并行化目标的并行化的常见概念。
并行化概念
Parallelization Concepts
并行化可以通过几种方法进行,这取决于特定的应用程序和并行化的目标。本文介绍了一些基本的并行化概念。只能提供一些最常见的一般概念。介绍的并行化概念与下列并行化的具体目标有关:
- 尽量减少响应时间
- 最大限度提高吞吐量
- 提高响应能力
最小化响应时间
数据并行化意味着多个线程对不同的数据段执行相同的任务。
如下图所示:一张图的中值滤波可以分为多个小块并行计算。首先,数据被分割成几个大致相同大小的数据块。然后,由不同的线程对每个数据块单独执行该任务。最后,在最后一个线程完成后,将连接所有线程的结果。

默认情况下,几乎所有的操作符都会自动执行数据并行化。
请注意,在很多情况下,Halcon 的自动操作符并行化(automatic operator parallelization, AOP)足够高效,因此手动实现数据并行化不会导致任何进一步的运行时增强。
要使用AOP,系统参数 parallelize_operators 必须设置为 true (默认值)。通过将系统参数 thread_num 设置为介于1和可用核数之间的值,可以明确地设置要使用的线程数。默认情况下,所有可用的核心都用于 AOP。
手动并行化示例
例程路径:
MVTec/HALCON-22.11-Progress/examples/hdevelop/System/Parallelization/simulate aop.hdev
示例通过模拟AOP实现数据并行化。由于应该模拟AOP,所以首先关闭AOP。图像被分割成大致相同大小的碎片。这是通过将要由单个线程处理的图像的域减少到输入图像的域的各自的子区域来实现的。启动并行运行单个线程。在每个线程中,计算各自的图像部分的中值。使用向量变量收集不同线程的结果。
要等待所有涉及的线程完成,将调用操作符par_join。然后,将各个线程的结果复制到一个图像中,核心代码如下。
1 | |
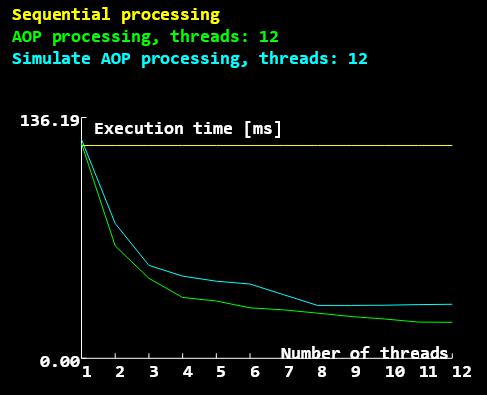
AOP、无AOP、以及在有12个核的硬件线程的机器上使用并行编程模拟AOP的中值过滤器的运行耗时。
由于HEdeviond造成的一些开销,模拟AOP处理的运行时间甚至略大于AOP。但两者都比顺序处理要快得多。
任务并行化
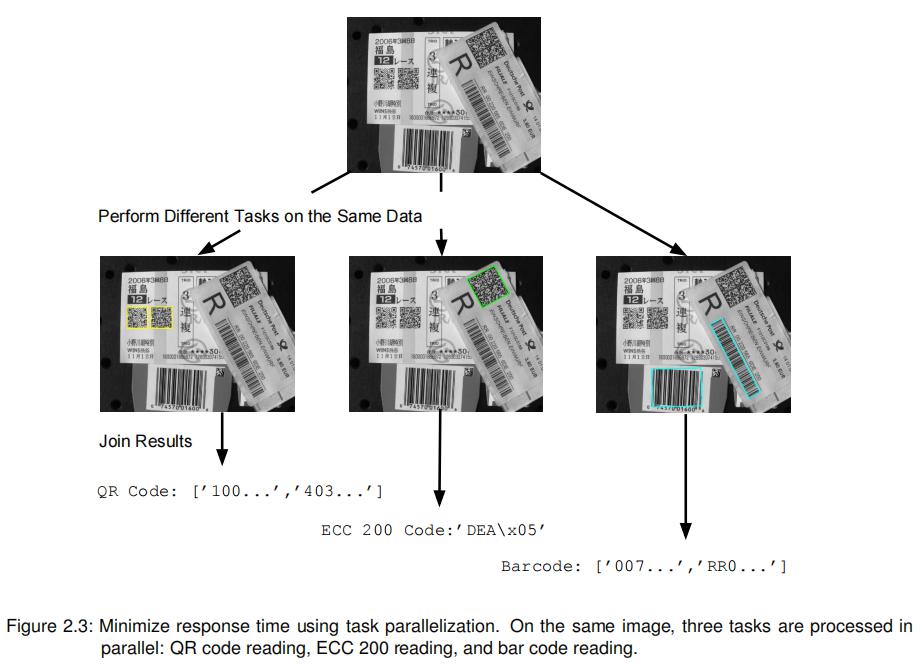
任务并行化意味着,例如,在同一图像上,在不同的线程中执行不同的任务:
例程路径:
hdevelop/Control/par_start.hdev
注意,示例程序不仅展示了如何并行化这三个识别任务,而且还提供了对哪些任务并行化是合理的提示。此外,通过比较并行化过程调用所需的运行时和过程调用和相应的顺序应用过程调用,演示了并行化的加速。
提高吞吐量
Maximize Throughput
特别是在处理流式数据时,系统的吞吐量通常比其响应时间更重要。提高系统吞吐量的一种方法是流水线化。
管道化 (pipelining)
管道传输通常与流式数据的处理有关,比如从监控传送带上物体的摄像机上拍摄的图像:

在这种情况下,可以在处理对象2的图像的同时和在评估对象1的图像处理结果的同时获取对象3的图像。
各个处理步骤,例如图像获取、图像处理和结果评估,由由消息队列连接的不同阶段执行,这样一个阶段的输出是下一个阶段的输入。因此,管道由(通常)多个生产者/消费者对组成。
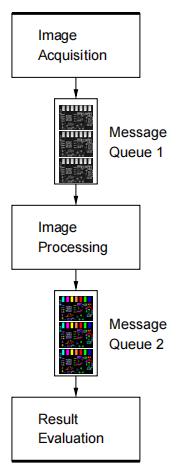
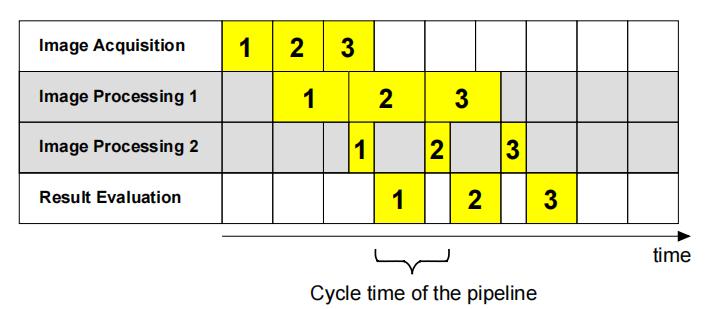
图中的管道由三个阶段组成,它们由两个消息队列连接。所有三个阶段都在并行运行的独立线程中运行。图像采集阶段获取图像,将图像放置到 FIFO 的消息队列 1 中,图像处理模块闲置时会从队列 1 头部获取图像,将处理完成的数据放到消息队列 2 中,结果评估模块会从队列 2 头部获取数据评估完成该图像的处理。
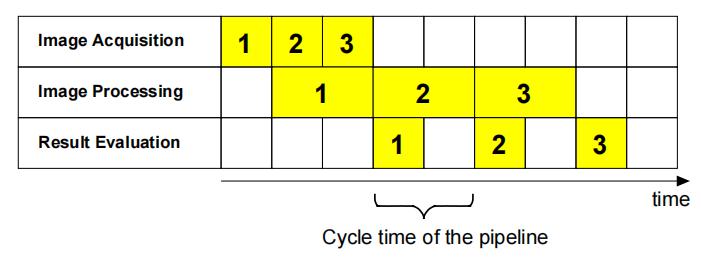
当线程并行运行时,对第一图像的结果评估可以并行于第二图像的处理并并行于第三图像的获取来执行。通常,不同阶段的处理时间是不相等的。例如,图像处理阶段所花费的时间是结果评估阶段的两倍。
管道的周期时间(Cycle time)是完成连续任务之间的时间。管道的吞吐量是其周期时间的倒数。请注意,管道的吞吐量受到其最慢阶段的吞吐量的限制。
因为管道的各个阶段都是并行执行的,所以它的吞吐量通常高于按顺序执行这些阶段的程序的吞吐量。

管道的实现遵循以下模式:
- 将各个阶段的功能放到单独的过程中。
- 创建和配置消息队列。
- 为管道的清空和运行准备数据结构。
- 在单个线程中启动这些过程。
核心流程
运行例程:
hdevelop/System/Multithreading/pipeline_one_thread_per_stage.hdev
首先,不同阶段的功能必须放到单独的过程中。这里采用了三个方法来获取图像、处理图像和评价结果。必须从一个阶段传递到下一个阶段的数据将通过消息队列传递。由于我们有三个阶段,所以我们需要两个消息队列来连接这些阶段。它们是用操作符创建 create_message_queue 创建的:
1 | |
通常,应该限制消息队列的大小,以控制程序的内存使用情况。通过以下调用完成:
1 | |
请注意,消息队列的大小应该选择足够大,以便它们处理短期峰值加载。例如,如果在短时间内,图像的获取速度比处理速度快,那么它们将在消息队列中被缓冲。
在单个线程中启动这些过程:
1 | |
我们必须等到所有的线程都完成。
1 | |
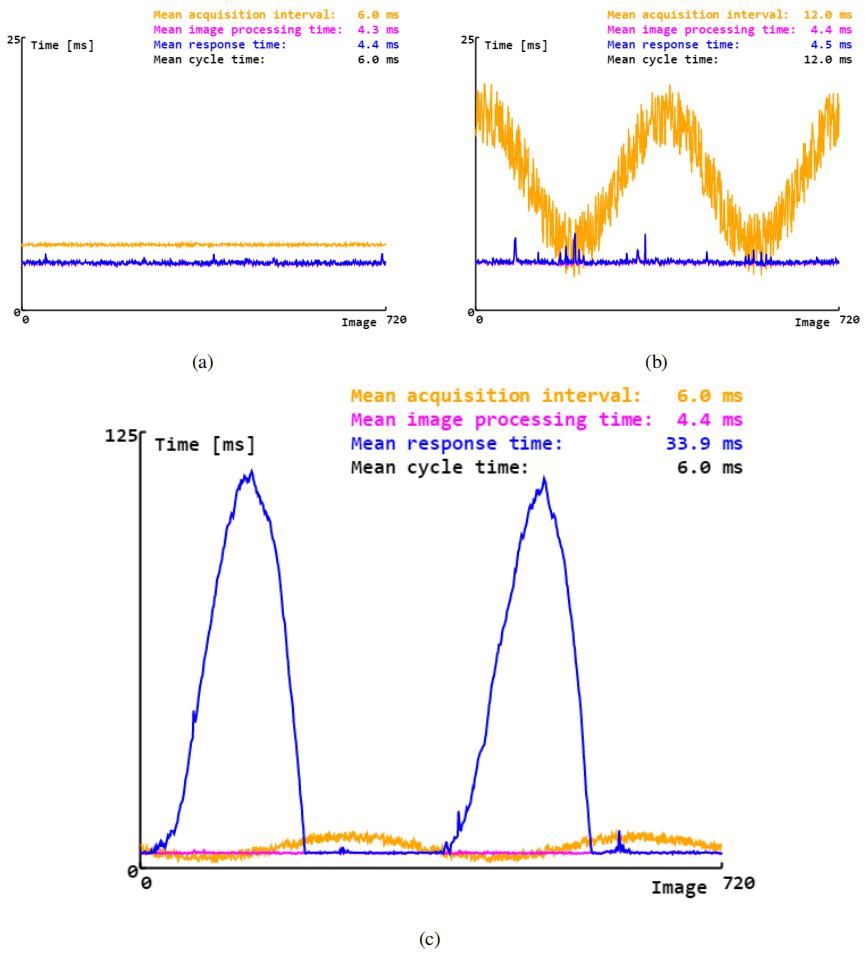
简单管道的运行时行为: (a) 近似恒定的采集间隔。(b) 改变采集间隔。© 不同的采集间隔导致短期峰值负荷。
管道加速
有两种可能的方法可以提高管道的速度:
- 将最慢的阶段分成多个阶段。
- 在多个线程上并行执行最慢的阶段。
这两种方法都试图减少管道最慢阶段所需的平均处理时间,因为这限制了整个管道的速度。
但虽然将最慢的阶段分成多个阶段是很简单且直接的方法,它的有效性取决于将舞台分割成大致相同大小的碎片(运行时间)的可能性。如果这种分段难以实现那么单阶段的运行速度会再次变化,而且管道的周期时间也没有达到最优。
下图显示了将图像处理阶段分为两个阶段的管道的调度图。由于我们不可能将图像处理阶段分成两个相同大小的阶段,假设一段耗时是另一段的三倍,则可以一定程度加速之前的流程。
第二种方法是在多个线程上并行执行最慢的阶段,需要更多的实现工作,但通常更容易加速该阶段的任务执行。例如我们将图像处理的工作并行给两个线程去做:
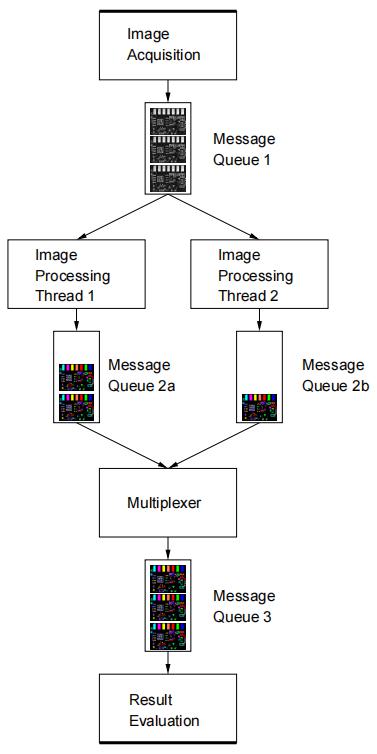
图像处理阶段在两个线程上并行运行。
根据图像内容,最后启动的图像处理任务可能在先启动的任务之前完成。下图显示了上述所讨论的管道的调度过程。当第一图像仍在被处理时,所述第二图像的图像处理开始。
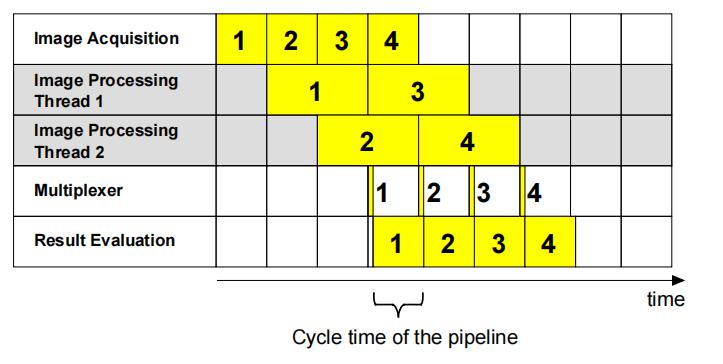
任务完成的周期时间与图像采集时间相等,已经达到了当前数据采集系统的吞吐上限。
测试例程:
hdevelop/System/Multithreading/pipeline_multiple_threads_per_stage.hdev
提高响应能力
Enhance Responsiveness
生产者消费者模式
生产者消费者模型不是一个并行化的概念或场景,而是一种可以在所有不同的并行化方法中使用的方法。通常,这个模型描述了一个线程,即生产者,提供一些数据,一个或几个线程,消费者),使用来进一步处理。线程既可以是生产者,也可以是消费者,例如,在管道中,管道由几个生产者消费者进程组成。生产者线程和消费者线程之间的通信是通过消息队列来实现的。
请注意,处理时间并不总是相同的。因此,例如,如果生产者线程获取图像,并且消费者线程处理它们,那么如果处理线程不能及时捕获它们,图像可能会丢失。图像必须缓冲,必须特别小心以避免缓冲区溢出。

核心函数
par_start
若要启动新线程,请在相应的运算符或过程调用前面加上 par_start 限定符:
1 | |
上述示例代码以调用后台的新子线程的形式启动 together_data() ,并继续执行后续的程序行。 线程 ID 在变量 ThreadID 中返回,该变量必须在尖括号中指定。
请注意,
par_start不是一个实际的操作符,而只是一个修饰符,用于修改调用行为。因此,不可能在运算符窗口中选择par_start。
如果线程数量超过配置的最大线程数将会引发异常。
支持在循环中启动多个线程。在这种情况下,需要收集线程 ID,以便以后可以引用所有线程:
1 | |
在向量变量中收集线程 ID 通常更方便:
1 | |
结果收集
当子线程在输出变量中返回数据时,必须特别小心。特别是,当子线程仍在运行时,不能在其他线程中访问输出变量。否则,不能保证数据是有效的。
同样,必须确保多个线程不会干扰它们的结果。假设搜集数据的过程像上面一样以多个线程的形式启动,但是在输出控制变量中返回数据:
1 | |
在上面的例子中,所有的线程都会在同一个变量中返回它们的结果,这当然不是我们想要的。Result 的最终值将是最后完成的线程的(不可预测的)返回值,其他所有结果都将丢失。
这个问题的一个简单解决方案是在向量变量中收集返回的数据,如前面的线程 ID 所示:
1 | |
在这里,每次数据的调用都会在向量变量 Result 的唯一位置中返回结果。
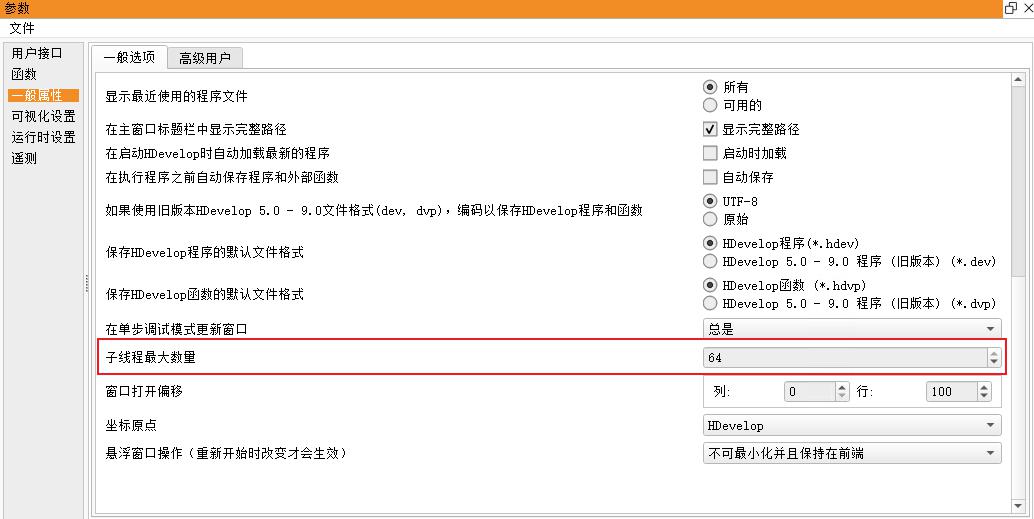
修改最大线程数
Halcon 22.11 默认最大子线程数量为 $max(cpu核心数 , 20)$,可能不够用,如果需要调整的话要在
编辑->参数选择->一般属性->子线程最大数量
最多可以设置为系统逻辑核个数
参考资料
文章链接:
https://www.zywvvd.com/notes/coding/halcon/halcon-parallel/halcon-parallel/
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付