本文最后更新于:2024年5月11日 下午
XML已经成为数据传输存储使用越来越广泛的数据格式,本文讲述使用Python DOM处理XML文件的方法。
准备工作
Python常用处理XML库
常见的 XML 编程接口有 DOM 和 SAX,这两种接口处理 XML 文件的方式不同,当然使用场合也不同。Python 有三种方法解析 XML,SAX,DOM,以及 ElementTree:
DOM(Document Object Model) - 本文介绍
DOM (Document Object Model) 译为文档对象模型,是 HTML 和 XML 文档的编程接口。HTML DOM 定义了访问和操作 HTML 文档的标准方法。将 XML 数据在内存中解析成一个树,通过对树的操作来操作XML。
SAX (simple API for XML )
Python 标准库包含 SAX 解析器,SAX 用事件驱动模型,通过在解析XML的过程中触发一个个的事件并调用用户定义的回调函数来处理XML文件。
ElementTree(元素树)
ElementTree就像一个轻量级的DOM,具有方便友好的API。代码可用性好,速度快,消耗内存少。
测试用例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <?xml version="1.0" encoding="utf-8" ?> <bookstore type ="info science" > <book category ="Coding" > <title > C++Primer</title > <author > StanleyB.Lippman</author > <price > 60.0</price > <year > 2009</year > </book > <book category ="Computer" > <title > 编译原理</title > <author > AlfredV.Aho</author > <price > 70.0</price > <year > 2013</year > </book > </bookstore >
Python DOM 解析XML
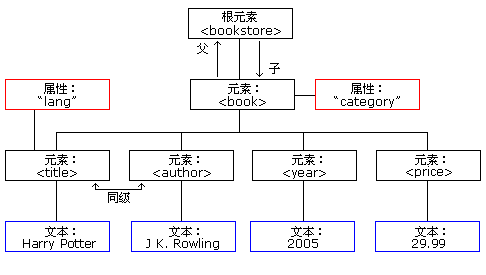
DOM节点树
一个 DOM 的解析器在解析一个 XML 文档时,一次性读取整个文档,把文档中所有元素保存在内存中的一个树结构里。
节点级别
节点树中的节点彼此之间都有等级关系。
在节点树中,顶端的节点成为根节点
根节点之外的每个节点都有一个父节点
节点可以有任何数量的子节点
叶子是没有子节点的节点
同级节点是拥有相同父节点的节点
解析XML
python 加载DOM解析XML,并输出整个XML
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from xml.dom.minidom import parse'test.xml' )print (root.toxml())type ="info science" >"Coding" >60.0 </price>2009 </year>"Computer" >70.0 </price>2013 </year>
此时root获取了XML文件中所有内容,组织成了一棵树,root就是该树的根节点
获取节点名称
1 2 3 4 5 6 print (root.nodeName)print (root.tagName)>>> bookstore
获取子节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 print (f'子节点个数:{children_Nodes.length} ' )for item in children_Nodes:print (item.toxml())>>> 子节点个数:5 "Coding" >60.0 </price>2009 </year>"Computer" >70.0 </price>2013 </year>
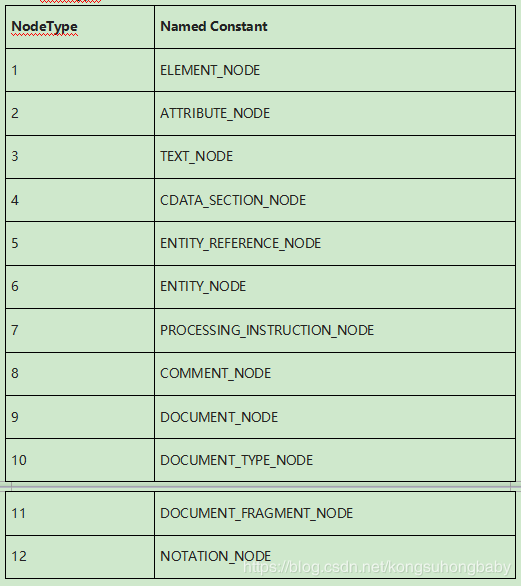
节点类型
为什么2本书却有5个节点?
因为两本书前中后各有一个回车,被划为文本节点。
DOM规定节点:
整个文档是一个文档节点
每个 XML 标签是一个元素节点
包含在 XML 元素中的文本是文本节点
每一个 XML 属性是一个属性节点
注释属于注释节点
文本总是存储在文本节点中
在 DOM 处理中一个普遍的错误是,认为元素节点包含文本。
不过,元素节点的文本是存储在文本节点中的。
在这个例子中:<year>2005</year>,元素节点 <year>,拥有一个值为 “2005” 的文本节点。
“2005” 不是 <year> 元素的值!d
获取节点属性
1 2 3 4 5 6 7 8 9 print (root.attributes.items())'type' ]print (atr_root.name)print (atr_root.value)'type' , 'info science' )]type
获取指定名称的节点
1 2 3 4 5 6 7 8 'book' )for book in books:print (book.nodeName)
判断是否包含属性值
1 2 3 4 5 6 print (books[0 ].hasAttribute('nnn' ))print (books[0 ].hasAttribute('category' ))False True
获取节点指定属性的属性值
1 2 3 4 5 6 print (books[0 ].getAttribute('category' ))print (books[1 ].getAttribute('category' ))
获取节点文本值
1 2 3 4 5 6 0 ]'author' )print (author[0 ].firstChild.data)
判断是否有子节点
1 2 3 4 5 6 7 8 print (root.hasChildNodes())print (author[0 ].hasChildNodes())print (author[0 ].firstChild.hasChildNodes())True True False
DOM解析XML方法总结
contents = xml.dom.minidom.parse(filename):加载读取XML文件
node = contents.documentElement:获取XML文档对象
node.getAttribute(AttributeName):获取XML节点属性值
node.getElementsByTagName(TagName):获取XML节点对象集合
node.childNodes :返回子节点列表。
node.childNodes[index].nodeValue:获取XML节点值
node.firstChild:访问第一个节点,等价于pagexml.childNodes[0]
node.toxml(‘UTF-8’)返回Node节点的xml表示的文本:
访问元素属性:atr.name # “id”
node.nodeName/node.tagName:节点的名称
node.nodeValue:节点的值,文本节点才有值,其它节点返回的是None
node.nodeType:节点的类型
Python DOM 修改XML
生成XML树、添加属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from xml.dom import minidom'root' )'book' )'price' ,'399' )'name' )'C++ Primer 第1版' )print (dom.toxml()) print (dom.toprettyxml()) >>> <?xml version="1.0" ?><root><book price="399" ><name>C++ Primer 第1 版</name></book></root>"1.0" ?>"399" >1 版</name>
删除节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 'delete' )'content' )'testing data' )print (dom.toprettyxml())"1.0" ?>"399" >1 版</name>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 for i in range (children_Nodes.length-1 ,-1 ,-1 ):if children_Nodes[i].tagName=='delete' :print (dom.toprettyxml())>>> <?xml version="1.0" ?>"399" >1 版</name>
删除节点属性
1 2 3 4 5 6 7 8 9 10 'price' ,'199' )print (book_node.hasAttribute('price' ))print (book_node.getAttribute('price' ))'price' )print (book_node.hasAttribute('price' ))True 199 False
修改节点内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ' (中文版)' for item in children_Nodes:'name' print (c_name[0 ].firstChild.data)0 ].firstChild.data+=name_Appendprint (dom.toprettyxml())1 版"1.0" ?>1 版 (中文版)</name>
修改节点属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 'price' ,'199' )print (book_node.hasAttribute('price' ))print (book_node.getAttribute('price' ))'price' ,'399' )print (book_node.getAttribute('price' ))'price2' ,'599' )print (book_node.attributes.items())>>> True 199 399 'price' , '399' ), ('price2' , '599' )]
修改节点名称(可用、不安全)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 'name' )'node name' 'tag name' print (dom.toxml())print (name_node.nodeName)print (name_node.localName)1 ])"1.0" ?><root><book price="399" price2="599" ><name>C++ Primer 第1 版 (中文版)</name></book><tag name/></root>
可以看到,改变tagName在事实上实现了改变节点名称的效果,但nodeName并没有一并更新,使用时需要谨慎。
DOM修改XML方法总结
dom=minidom.Document() #创建DOM树对象
root_node=dom.createElement(‘root’) #用DOM对象创建元素节点
name_text=dom.createTextNode(‘计算机程序设计语言 第1版’)#用DOM对象创建文本节点
dom.appendChild(root_node) # 用DOM对象添加节点
book_node.setAttribute(‘price’,‘199’) #添加节点属性(可多个),也可以用来覆盖修改原有的属性
children_Nodes.remove(children_Nodes[i]) #删除节点
book_node.removeAttribute(‘price’) #删除节点属性
price[0].firstChild.data=str(price_float) #直接修改文本节点完成对xml保存内容的修改
name_node.tagName=‘tag name’ #修改节点名称
Python DOM 写入XML
写入XML
语法:writexml(writer, indent=“”, addindent=“”, newl=“”, encoding=None)
writer:文件对象
indent:根节点缩进格式(一般根节点不缩进,所以一般为空)
addindent:子节点缩进格式(一般为空格 或制表符/t)
newl:换行格式(一般为换行回车/n)
encoding:编码方式
1 2 3 with open ('write_test.xml' ,'w' ,encoding='UTF-8' ) as writer:'' ,addindent=' ' ,newl='/n' ,encoding='UTF-8' )
得到xml文件write_test.xml:
1 2 3 4 5 6 7 <?xml version="1.0" encoding="UTF-8" ?> <root > <book price ="399" price2 ="599" > <name > C++ Primer 第1版 (中文版)</name > </book > </root >
获取源码
文中测试环境与所有源码可在Github 下载。
文章链接:https://www.zywvvd.com/notes/coding/python/processing-xml/python-xml/